Feature Engineering 特征工程 1. Baseline Model
learn from
发布日期:2021-07-01 03:25:51
浏览次数:3
分类:技术文章
本文共 2402 字,大约阅读时间需要 8 分钟。
文章目录
下一篇:
1. 读取数据
预测任务:用户是否会下载APP,当其点击广告以后
数据集:ks-projects-201801.csv- 读取数据,指定两个特征
'deadline','launched',parse_dates解析为时间
ks = pd.read_csv('ks-projects-201801.csv',parse_dates=['deadline','launched']) 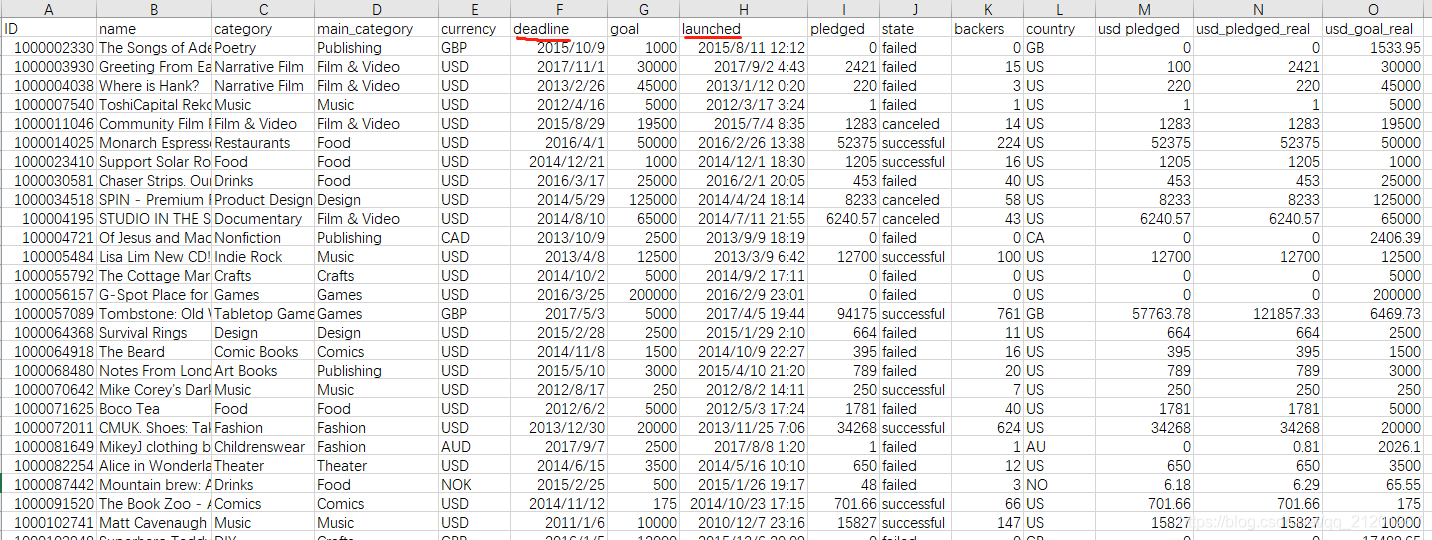
state作为结果label 可以使用类别category,货币currency,资金目标funding goal,国家country以及启动时间launched等特征 2. 处理label
- 准备标签列,看看有哪些值,转换成可用的数字格式
pd.unique(ks.state)
有6种数值
array(['failed', 'canceled', 'successful', 'live', 'undefined', 'suspended'], dtype=object)
每种多少个?按state分组,每组中ID行数有多少
ks.groupby('state')['ID'].count() statecanceled 38779failed 197719live 2799successful 133956suspended 1846undefined 3562Name: ID, dtype: int64
- 简单处理下标签列,正在进行的项目
live丢弃,successful的标记为1,其余的为0
ks = ks.query('state != "live"') # live行不要ks = ks.assign(outcome=(ks['state']=='successful').astype(int))# label 转成1,0,int型 3. 添加特征
- 把
launched时间拆分成,年月日小时,作为新的特征
ks = ks.assign(hour=ks.launched.dt.hour, day=ks.launched.dt.day, month=ks.launched.dt.month, year=ks.launched.dt.year)ks.head()
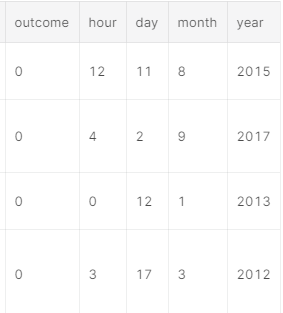
- 转换文字特征
category, currency, country为数字
from sklearn.preprocessing import LabelEncodercat_features = ['category','currency','country']encoder = LabelEncoder()encoded = ks[cat_features].apply(encoder.fit_transform)encoded.head(10)
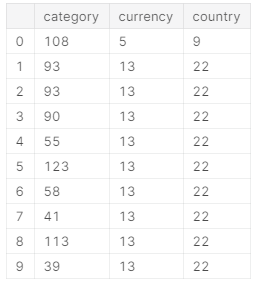
- 将选择使用的特征合并在一个数据里
X = ks[['goal', 'hour', 'day', 'month', 'year', 'outcome']].join(encoded)X.head()
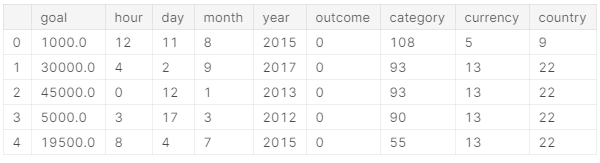
4. 数据集切片
- 数据切片,按比例分成训练集、验证集、测试集(0.8,0.1,0.1)
- 更高级的简单做法
sklearn.model_selection.StratifiedShuffleSplit
valid_ratio = 0.1valid_size = int(len(X)*valid_ratio)train = X[ : -2*valid_size]valid = X[-2*valid_size : -valid_size]test = X[-valid_size : ]
需要关注下,label 在每个数据集中的占比是否接近
for each in [train, valid, test]: print("Outcome fraction = {:.4f}".format(each.outcome.mean())) Outcome fraction = 0.3570Outcome fraction = 0.3539Outcome fraction = 0.3542
5. 训练
- 使用LightGBM模型进行训练
feature_cols = train.columns.drop('outcome')dtrain = lgb.Dataset(train[feature_cols], label=train['outcome'])dvalid = lgb.Dataset(valid[feature_cols], label=valid['outcome'])param = { 'num_leaves': 64, 'objective': 'binary'}param['metric'] = 'auc'num_round = 1000bst = lgb.train(param, dtrain, num_round, valid_sets=[dvalid], early_stopping_rounds=10, verbose_eval=False) 6. 预测
- 对测试集进行预测
from sklearn import metricsypred = bst.predict(test[feature_cols])score = metrics.roc_auc_score(test['outcome'], ypred)print(f"Test AUC score: {score}") 下一篇:
转载地址:https://michael.blog.csdn.net/article/details/106203925 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
逛到本站,mark一下
[***.202.152.39]2024年04月29日 18时45分25秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
xss-labs详解(下)11-20
2019-04-30
攻防世界web进阶区ics-04详解
2019-04-30
Linux png转jpg (convert命令)
2019-04-30
CodeForces - 456C Boredom (dp)
2019-04-30
CodeForces - 1042B Vitamins (思维)
2019-04-30
ACM 2013 长沙区域赛 Collision (几何)
2019-04-30
ACM 2014 鞍山区域赛 E - Hatsune Miku (dp)
2019-04-30
反向传播&梯度下降 的直观理解程序(numpy)
2019-04-30
ACM 2017 北京区域赛 J-Pangu and Stones(区间dp)
2019-04-30
java常用类 String面试题
2019-04-30
四线触摸屏原理
2019-04-30
C/C++如何返回一个数组/指针
2019-04-30
腾讯AI语音识别API踩坑记录
2019-04-30
java.net.BindException: 无法指定被请求的地址
2019-05-01
svn服务器安装
2019-05-01
spark 笔记1
2019-05-01
shell dirname basename
2019-05-01
未来已至,5G加持下的云游戏将走向何方?
2019-05-01
计算机网络 —— 网络层 1.
2019-05-01
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 311869551 位访客
访问时间: 2024-05-08 02:11:49
访问IP: 3.149.214.32
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版