NLP项目工作流程
参考 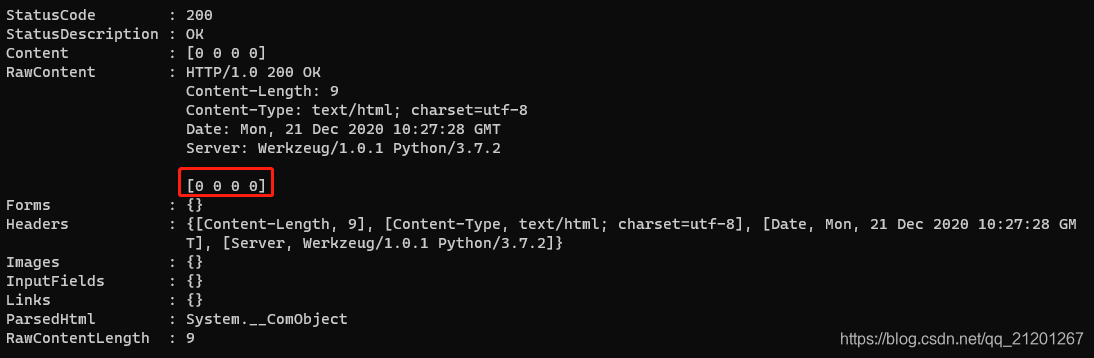
发布日期:2021-07-01 03:34:57
浏览次数:2
分类:技术文章
本文共 4132 字,大约阅读时间需要 13 分钟。
文章目录
使用这篇文章的数据()进行学习。
1. 谷歌Colab设置
-
新建笔记本

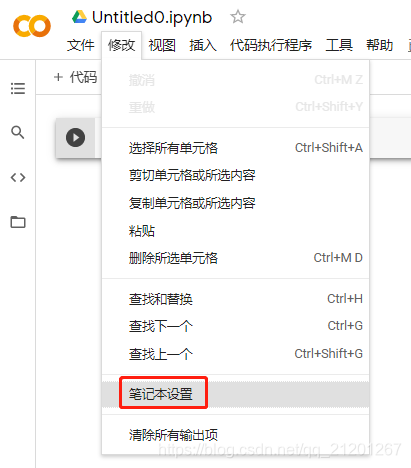
-
设置
-
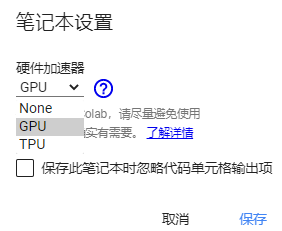
选择 GPU/TPU 加速计算
-
测试 GPU 是否分配
import tensorflow as tftf.test.gpu_device_name()
输出:
/device:GPU:0
- 上传数据至谷歌云硬盘,并在Colab中加载
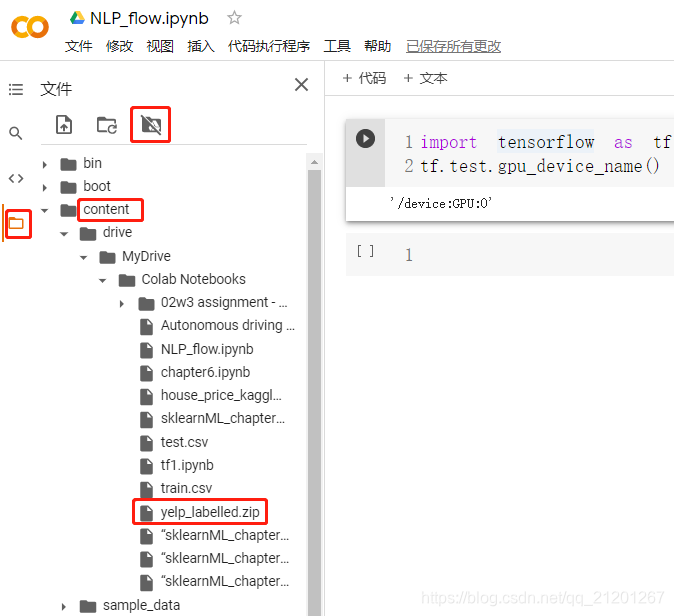


- 解压数据

2. 编写代码
import numpy as npimport pandas as pddata = pd.read_csv("yelp_labelled.txt", sep='\t', names=['sentence', 'label'])data.head() # 1000条数据# 数据 X 和 标签 ysentence = data['sentence'].valueslabel = data['label'].values# 训练集 测试集拆分from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(sentence, label, test_size=0.2, random_state=1)#%%max_features = 2000# 文本向量化from keras.preprocessing.text import Tokenizertokenizer = Tokenizer(num_words=max_features)tokenizer.fit_on_texts(X_train) # 训练tokenizerX_train = tokenizer.texts_to_sequences(X_train) # 转成 [[ids...],[ids...],...]X_test = tokenizer.texts_to_sequences(X_test)vocab_size = len(tokenizer.word_index)+1 # +1 是因为index 0, 0 不对应任何词,用来padmaxlen = 50# pad 保证每个句子的长度相等from keras.preprocessing.sequence import pad_sequencesX_train = pad_sequences(X_train, maxlen=maxlen, padding='post')# post 尾部补0,pre 前部补0X_test = pad_sequences(X_test, maxlen=maxlen, padding='post')#%%embed_dim = 256hidden_units = 64from keras.models import Model, Sequentialfrom keras.layers import Dense, LSTM, Embedding, Bidirectional, Dropoutmodel = Sequential()model.add(Embedding(input_dim=max_features,output_dim=embed_dim, input_length=maxlen))model.add(Bidirectional(LSTM(hidden_units)))model.add(Dropout(0.3))model.add(Dense(1, activation='sigmoid')) # 二分类sigmoid, 多分类 softmaxmodel.compile(optimizer='adam', loss='binary_crossentropy',metrics=['accuracy'])model.summary()from keras.utils import plot_modelplot_model(model, show_shapes=True, to_file='model.jpg') # 绘制模型结构到文件#%%history = model.fit(X_train,y_train,batch_size=64, epochs=100,verbose=2,validation_split=0.1)# verbose 是否显示日志信息,0不显示,1显示进度条,2不显示进度条loss, accuracy = model.evaluate(X_train, y_train, verbose=1)print("训练集:loss {0:.3f}, 准确率:{1:.3f}".format(loss, accuracy))loss, accuracy = model.evaluate(X_test, y_test, verbose=1)print("测试集:loss {0:.3f}, 准确率:{1:.3f}".format(loss, accuracy))# 绘制训练曲线from matplotlib import pyplot as pltimport pandas as pdhis = pd.DataFrame(history.history)loss = history.history['loss']val_loss = history.history['val_loss']acc = history.history['accuracy']val_acc = history.history['val_accuracy']plt.plot(loss, label='train Loss')plt.plot(val_loss, label='valid Loss')plt.title('Training and Validation Loss')plt.legend()plt.grid()plt.show()plt.plot(acc, label='train Acc')plt.plot(val_acc, label='valid Acc')plt.title('Training and Validation Acc')plt.legend()plt.grid()plt.show()#%%model.save('trained_model.h5')import picklewith open('trained_tokenizer.pkl','wb') as f: pickle.dump(tokenizer, f)# 下载到本地from google.colab import filesfiles.download('trained_model.h5')files.download('trained_tokenizer.pkl') 3. flask 微服务
- 以下内容不懂,抄一遍
编写 app.py
# Flaskimport pickleimport numpy as npfrom keras.preprocessing.sequence import pad_sequencesfrom keras.models import load_modeldef load_var(): global model, tokenizer model = load_model('trained_model.h5') model.make_predict_function() with open('trained_tokenizer.pkl','rb') as f: tokenizer = pickle.load(f)maxlen = 50def process_txt(text): x = tokenizer.texts_to_sequences(text) x = pad_sequences(x, maxlen=maxlen, padding='post') return x#%%from flask import Flask, request, jsonifyapp = Flask(__name__)@app.route('/')def home_routine(): return "hello NLP!"#%%@app.route("/prediction",methods=['POST'])def get_prediction(): if request.method == 'POST': data = request.get_json() x = process_txt(data) prob = model.predict(x) pred = np.argmax(prob, axis=-1) return str(pred)#%%if __name__ == "__main__": load_var() app.run(debug=True) # 上线阶段应该为 app.run(host=0.0.0.0, port=80) - 运行
python app.py - windows cmd 输入:
Invoke-WebRequest -Uri 127.0.0.1:5000/prediction -ContentType 'application/json' -Body '["The book was very poor", "Very nice", "bad, oh no", "i love you"]' -Method 'POST'
返回预测结果:
4. 打包到容器
- 后序需要用 Docker 将 应用程序包装到容器中
5. 容器托管
- 容器托管到网络服务,如 AWS EC2 实例
转载地址:https://michael.blog.csdn.net/article/details/111387027 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
路过按个爪印,很不错,赞一个!
[***.219.124.196]2024年04月27日 01时30分28秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
linux下安装jenkins+git+python
2019-05-01
解决uiautomatorviewer中添加xpath的方法
2019-05-01
性能测试的必要性评估以及评估方法
2019-05-01
Spark学习——利用Mleap部署spark pipeline模型
2019-05-01
Oracle创建表,修改表(添加列、修改列、删除列、修改表的名称以及修改列名)
2019-05-01
使用redis实现订阅功能
2019-05-01
对称加密整个过程
2019-05-01
java内存模型
2019-05-01
volatile关键字
2019-05-01
Servlet_快速入门
2019-05-01
Request_继承体系
2019-05-01
前端权限控制:获取用户信息接口构造数据
2019-05-01
七牛云存储:断点续传
2019-05-01
字节流复制文本文件【应用】
2019-05-01
私钥加密私钥解密
2019-05-01
锁的释放流程-ReentrantLock.unlock
2019-05-01
Java判断字符串是否为数字(浮点类型也包括)
2019-05-01
ubuntu opencv-python 安装很慢问题
2019-05-01
MySQL5.7版本修改了my.ini配置文件后mysql服务无法启动问题
2019-05-01
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 311982975 位访客
访问时间: 2024-05-08 11:06:28
访问IP: 3.15.219.217
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版