Pytorch 神经网络训练过程
发布日期:2021-07-01 03:35:11
浏览次数:2
分类:技术文章
本文共 2955 字,大约阅读时间需要 9 分钟。
文章目录
1. 定义模型
import torchimport torch.nn as nnimport torch.nn.functional as Fclass Net_model(nn.Module): def __init__(self): super(Net_model, self).__init__() self.conv1 = nn.Conv2d(1,6,5) # 卷积 # in_channels, out_channels, kernel_size, stride=1, # padding=0, dilation=1, groups=1, # bias=True, padding_mode='zeros' self.conv2 = nn.Conv2d(6,16,5) self.fc1 = nn.Linear(16*5*5, 120) # FC层 self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.conv1(x) x = F.relu(x) x = F.max_pool2d(x, (2,2)) x = self.conv2(x) x = F.relu(x) x = F.max_pool2d(x, 2) x = x.view(-1, self.num_flat_features(x)) # 展平 x = self.fc1(x) x = F.relu(x) x = self.fc2(x) x = F.relu(x) x = self.fc3(x) return x def num_flat_features(self, x): size = x.size()[1:] # 除了batch 维度外的维度 num_features = 1 for s in size: num_features *= s return num_featuresmodel = Net_model()print(model)
输出:
Net_model( (conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1)) (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) (fc1): Linear(in_features=400, out_features=120, bias=True) (fc2): Linear(in_features=120, out_features=84, bias=True) (fc3): Linear(in_features=84, out_features=10, bias=True))
1.1 绘制模型
from torchviz import make_dotvis_graph = make_dot(model(input),params=dict(model.named_parameters()))vis_graph.view()
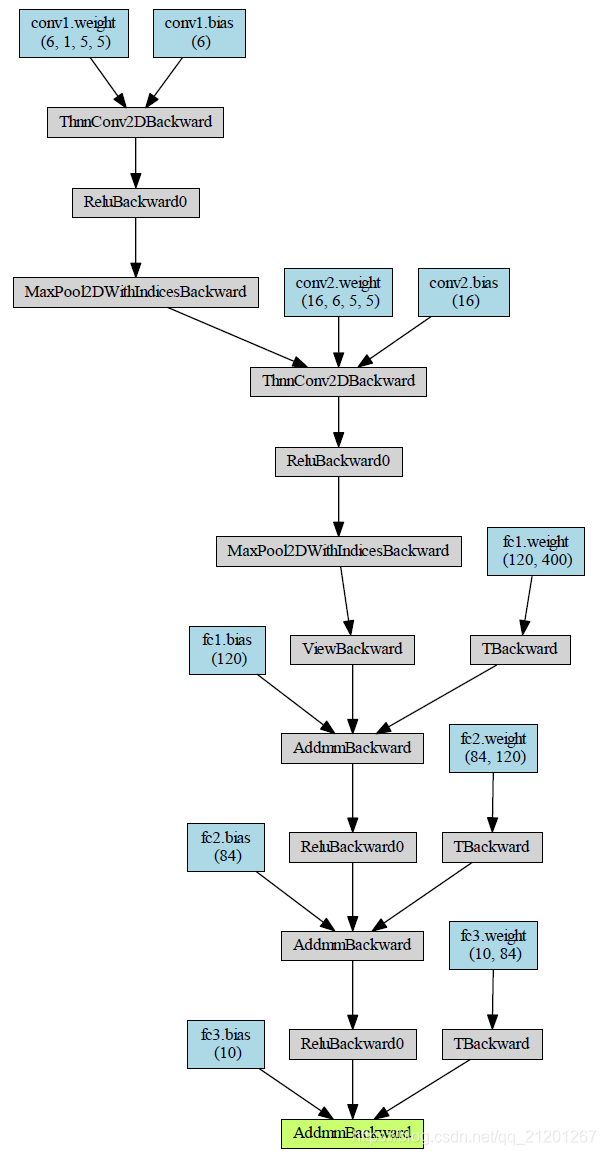
1.2 模型参数
params = list(model.parameters())print(len(params))for i in range(len(params)): print(params[i].size())
输出:
10torch.Size([6, 1, 5, 5])torch.Size([6])torch.Size([16, 6, 5, 5])torch.Size([16])torch.Size([120, 400])torch.Size([120])torch.Size([84, 120])torch.Size([84])torch.Size([10, 84])torch.Size([10])
2. 前向传播
input = torch.randn(1,1,32,32)out = model(input)print(out)
输出:
tensor([[-0.1100, 0.0273, 0.1260, 0.0713, -0.0744, -0.1442, -0.0068, -0.0965, -0.0601, -0.0463]], grad_fn=)
3. 反向传播
# 清零梯度缓存器model.zero_grad()out.backward(torch.randn(1,10)) # 使用随机的梯度反向传播
4. 计算损失
output = model(input)target = torch.randn(10) # 举例用target = target.view(1,-1) # 形状匹配 outputcriterion = nn.MSELoss() # 定义损失类型loss = criterion(output, target)print(loss)# tensor(0.5048, grad_fn=)
- 测试
.zero_grad()清零梯度缓存作用
model.zero_grad()print(model.conv1.bias.grad)loss.backward()print(model.conv1.bias.grad)
输出:
tensor([0., 0., 0., 0., 0., 0.])tensor([-0.0067, 0.0114, 0.0033, -0.0013, 0.0076, 0.0010])
5. 更新参数
learning_rate = 0.01for f in model.parameters(): f.data.sub_(f.grad.data*learning_rate)
6. 完整简洁代码
criterion = nn.MSELoss() # 定义损失类型import torch.optim as optimoptimizer = optim.SGD(model.parameters(), lr=0.1)# 优化目标,学习率# 循环执行以下内容 训练optimizer.zero_grad() # 清空梯度缓存output = model(input) # 输入,输出,前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数
转载地址:https://michael.blog.csdn.net/article/details/111696080 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关注你微信了!
[***.104.42.241]2024年04月12日 07时43分43秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
多用户与多租户的区别
2019-05-01
Python自动化运维 - day14 - JavaScript基础
2019-05-02
oracle保存小数点前为"0"的问题
2019-05-02
linux sar 命令详解
2019-05-02
LINUX 使用管道实现无需落地文件GZIP压缩
2019-05-02
pure-ftp 启用虚拟账户的问题
2019-05-02
ipvsadm 安装配置
2019-05-02
linux下nc的使用
2019-05-02
sed学习---字符替换
2019-05-02
Linux shell脚本的字符串截取
2019-05-02
linux和windows下mysql密码怎样清空!
2019-05-02
mysql logs-slave-updates (A -> B -> C)
2019-05-02
关于Java中split方法对空字符串处理问题
2019-05-02
mysql JDBC URL参数解析
2019-05-02
数据库复习(4)
2019-05-02
C# TextBox输入密码显示星号(*)
2019-05-02
1小时点击量破千万!阿里巴巴首发:MySQL高级调优笔记!全是技术重点
2019-05-02
这个GItHub上的Java项目开源了 2021最全的Java架构面试复习指南
2019-05-02
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 311729505 位访客
访问时间: 2024-05-07 14:41:19
访问IP: 18.190.217.134
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版