数据结构--散列表 Hash Table
发布日期:2021-07-01 03:39:43
浏览次数:2
分类:技术文章
本文共 7117 字,大约阅读时间需要 23 分钟。
文章目录
- 1. 散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表。
- 2. 散列函数,设计的基本要求
- 散列函数计算得到的散列值是一个非负整数( 因为数组下标从0开始)
- 如果 key1 = key2,那 hash(key1)== hash(key2)
- 如果 key1 != key2,那 hash(key1)!= hash(key2)
第3条是很难完全满足的,不满足称之,散列冲突。
- 3. 散列冲突 解决方法:
- 开放寻址法 a.线性探测
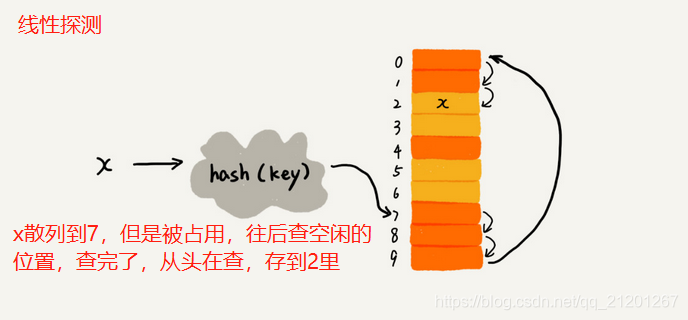
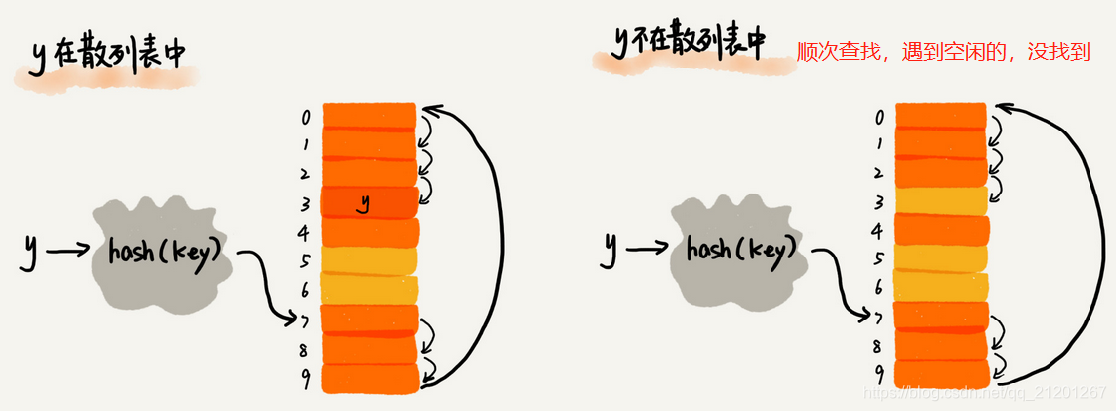
 线性探测法,当空闲位置越来越少时,几乎要遍历整个散列表,接近O(n)复杂度 b. 二次探测:每次的步长是 1, 2, 4, 8, 16,… c. 双重散列:使用多个散列函数,先用第一个,如果位置被占,再用第二个散列函数。。。直到找到空闲位置 不管哪种方法,空闲位置不多了,冲突概率会大大提高,尽量保证有一定比例的空闲(用装载因子表示,因子越大,空位越少,冲突越多,散列表性能下降)
线性探测法,当空闲位置越来越少时,几乎要遍历整个散列表,接近O(n)复杂度 b. 二次探测:每次的步长是 1, 2, 4, 8, 16,… c. 双重散列:使用多个散列函数,先用第一个,如果位置被占,再用第二个散列函数。。。直到找到空闲位置 不管哪种方法,空闲位置不多了,冲突概率会大大提高,尽量保证有一定比例的空闲(用装载因子表示,因子越大,空位越少,冲突越多,散列表性能下降) - 链表法(更常用的解决冲突的办法)
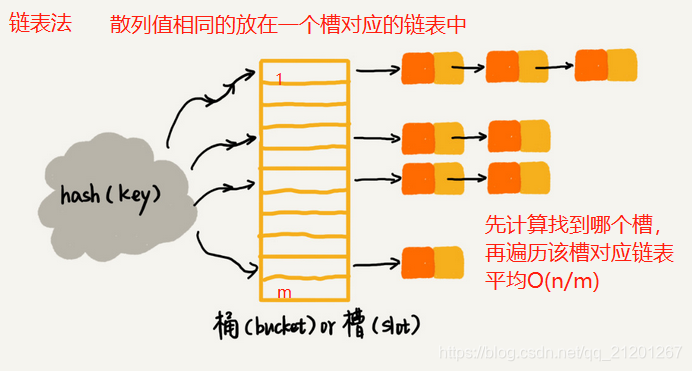
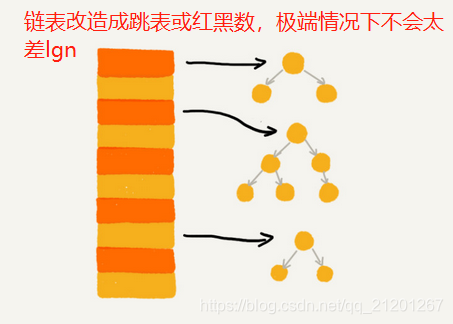
- 4. 如何设计散列函数 a. 散列函数的设计不能太复杂。过于复杂的散列函数,势必会消耗很多计算时间,也就间接的影响到散列表的性能。 b. 散列函数生成的值要尽可能随机并且均匀分布,这样才能避免或者最小化散列冲突,即便出现冲突,散列到每个槽里的数据也会比较平均,不会出现某个槽内数据特别多的情况。 c. 装载因子超过阈值,自动扩容,避免累积到最后一次性搬移数据,分批多次搬移,O(1)复杂度 d. 数据量比较小,装载因子小的时候,适合采用开放寻址法 e. 基于链表的散列冲突处理方法比较适合存储大对象、大数据量的散列表,而且,比起开放寻址法,它更加灵活,支持更多的优化策略,比如用红黑树代替链表。
1.线性探测 哈希表代码
hashtable1.h
/** * @description: 哈希表,开放寻址--线性探测法 * @author: michael ming * @date: 2019/5/6 10:26 * @modified by: */#ifndef SEARCH_HASHTABLE1_H#define SEARCH_HASHTABLE1_H#includeenum KindOfItem { Empty, Active, Deleted};template struct HashItem{ DataType data; KindOfItem info; HashItem (KindOfItem i = Empty):info(i){ } HashItem (const DataType &d, KindOfItem i = Empty):data(d), info(i){ } int operator== (HashItem &a) { return data == a.data; } int operator!= (HashItem &a) { return data != a.data; }};template class hashtable1{ private: HashItem *ht; //散列表数组 int TableSize; //散列表长度 int currentSize; //当前表项个数 int deletedSize; //删除标记的元素个数public: hashtable1 (int m) { TableSize = m; ht = new HashItem [TableSize]; currentSize = 0; deletedSize = 0; } ~hashtable1 () { delete [] ht; } int hash(const DataType &newData) const { return newData%TableSize; //留余数法 } int find(const DataType &x) const; int find_de(const DataType &x) const; //当有deleted标记的元素时,插入函数调用此查找 int insert(const DataType &x); int delete_elem(const DataType &x); void print() const { for(int i = 0; i < TableSize; ++i) { std::cout << ht[i].data << " " << ht[i].info << "->"; } std::cout << std::endl; } int isInTable(const DataType &x) { int i = find(x); return i >= 0 ? i : -1; } DataType getValue(int i) const { return ht[i].data; }};#endif //SEARCH_HASHTABLE1_H
hashtable1.cpp
/** * @description: 哈希表,开放寻址--线性探测法 * @author: michael ming * @date: 2019/5/6 10:26 * @modified by: */#include "hashtable1.h"templateint hashtable1 ::find(const DataType &x) const{ int i = hash(x); int j = i; while(ht[j].info == Deleted || (ht[j].info == Active && ht[j].data != x)) //说明存在冲突 { j = (j+1)%TableSize; //用解决冲突的方法继续查找(开放定址法) if(j == i) return -TableSize; //遍历整个散列表,未找到 } if(ht[j].info == Active) return j; //找到,返回正值 else return -j; //没找到,返回负值}template int hashtable1 ::find_de(const DataType &x) const //当有deleted标记的元素时,插入函数调用此查找{ int i = hash(x); int j = i; while(ht[j].info == Active) //说明存在冲突 { j = (j+1)%TableSize; //用解决冲突的方法继续查找(开放定址法) if(j == i) return -TableSize; //遍历整个散列表,没有空位 } return j; //返回标记为Empty或者Deleted的位置}template int hashtable1 ::insert(const DataType &x){ int i = find(x); if(i > 0) return 0; //元素x已存在 else if(i != -TableSize && !deletedSize) //元素x不存在,且散列表未满(且没有deleted标记) { ht[-i].data = x; //元素赋值 ht[-i].info = Active; //占用了,标记一下 currentSize++; return 1; } else if(i != -TableSize && deletedSize) //元素x不存在,且散列表未满(且有deleted标记) { int j = find_de(x); if(j >= 0) { if(ht[j].info == Deleted) deletedSize--; ht[j].data = x; //元素赋值 ht[j].info = Active; //占用了,标记一下(删除标记改成占用标记 ) currentSize++; return 1; } else return 0; } else return 0;}template int hashtable1 ::delete_elem(const DataType &x){ int i = find(x); if(i >= 0) { ht[i].info = Deleted; //找到了要删除的,标记删除 currentSize--; deletedSize++; return 1; } else return 0;}
hashtable1_test.cpp 测试程序
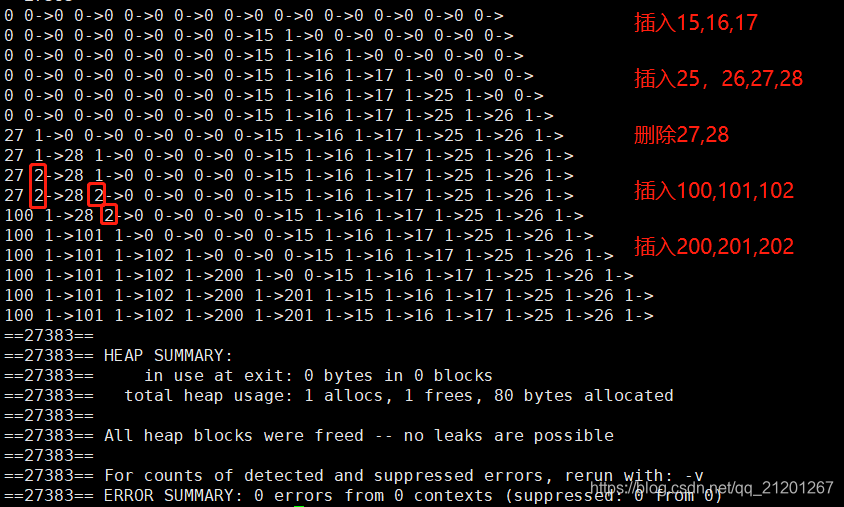
/** * @description: * @author: michael ming * @date: 2019/5/6 10:42 * @modified by: */#include "hashtable1.cpp"#includeint main(){ hashtable1 ht1(10); ht1.print(); for(int i = 15; i < 18; ++i) { ht1.insert(i); ht1.print(); } for(int i = 25; i < 29; ++i) { ht1.insert(i); ht1.print(); } for(int i = 27; i < 29; ++i) { ht1.delete_elem(i); ht1.print(); } for(int i = 100; i < 103; ++i) { ht1.insert(i); ht1.print(); } for(int i = 200; i < 203; ++i) { ht1.insert(i); ht1.print(); } if(ht1.isInTable(109) >= 0) std::cout << ht1.getValue(ht1.isInTable(109)); return 0;}
测试结果:(data,标记位)标记 empty = 0,active = 1, deleted = 2
2.拉链法 哈希表代码
linkedHash.h
/** * @description: 拉链法散列表 * @author: michael ming * @date: 2019/5/6 17:56 * @modified by: */#ifndef SEARCH_LINKEDHASH_H#define SEARCH_LINKEDHASH_H#includetemplate struct linkedNode //链表节点{ DataType data; linkedNode *next; linkedNode():next(NULL){ } linkedNode(const DataType &d):next(NULL), data(d){ }};template class linkedList //链表{ public: linkedNode *head; linkedList() { head = new linkedNode (); //表头哨兵 } ~linkedList() { delete head; }};template class linkedHash{ private: linkedList *htList; //散列表链表数组 int bucket; //散列表桶个数public: linkedHash (int m):bucket(m) { htList = new linkedList [bucket] (); } ~linkedHash () { for(int i = 0; i < bucket; ++i) { linkedNode *p = htList[i].head->next, *q = p; while(q != NULL) { p = q; q = q->next; delete p; } } delete [] htList; } int hash(const DataType &newData) const { return newData%bucket; //留余数法 } linkedNode * find(const DataType &x) const { int i = hash(x); linkedNode *p = htList[i].head->next, *q = htList[i].head; while(p && p->data != x) { q = p; p = p->next; } return q; //返回找到元素的前一个节点,或者没有找到,返回最后一个元素 } linkedNode * insert(const DataType &x) { int i = hash(x); linkedNode *p = htList[i].head, *q = p; while(q != NULL) { p = q; q = q->next; } p->next = new linkedNode (x); return p->next; } void delete_elem(const DataType &x) { linkedNode *q = find(x), *p; if(q->next) { p = q->next; q->next = q->next->next; delete p; } } void print() const { for(int i = 0; i < bucket; ++i) { std::cout << i << "[ ]"; linkedNode *p = htList[i].head->next; while(p) { std::cout << p->data << "->"; p = p->next; } std::cout << std::endl; } std::cout << "----------------------" << std::endl; }};#endif //SEARCH_LINKEDHASH_H
linkedHash_test.cpp 测试程序
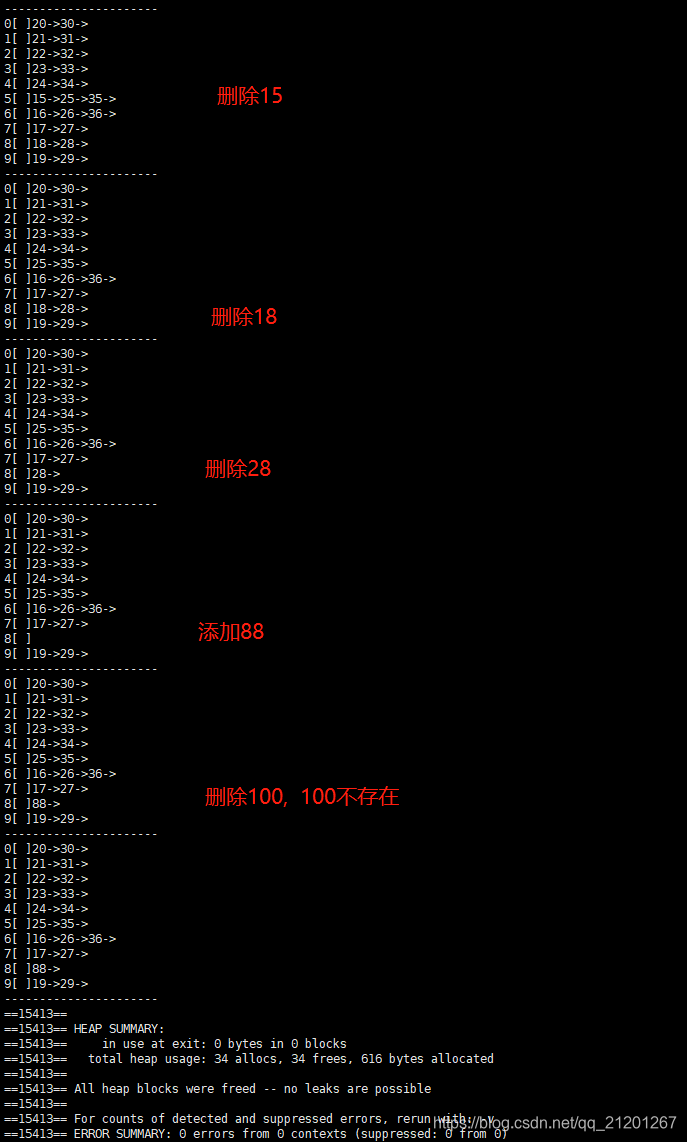
/** * @description: 拉链法散列表 测试 * @author: michael ming * @date: 2019/5/6 17:57 * @modified by: */#include "linkedHash.h"int main(){ linkedHash ht2(10); for(int i = 15; i < 37; ++i) { ht2.insert(i); ht2.print(); } ht2.delete_elem(15); ht2.print(); ht2.delete_elem(18); ht2.print(); ht2.delete_elem(28); ht2.print(); ht2.insert(88); ht2.print(); ht2.delete_elem(100); ht2.print(); return 0;} 测试结果:
转载地址:https://michael.blog.csdn.net/article/details/89816008 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
路过,博主的博客真漂亮。。
[***.116.15.85]2024年04月23日 03时11分23秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
【学习笔记】Android Activity
2019-04-30
location区段
2019-04-30
linux内存的寻址方式
2019-04-30
how2heap-double free
2019-04-30
how2heap-fastbin_dup_consolidate
2019-04-30
tf keras SimpleRNN源码解析
2019-04-30
MyBatisPlus简单入门(SpringBoot)
2019-04-30
攻防世界web进阶区web2详解
2019-04-30
xss-labs详解(上)1-10
2019-04-30
xss-labs详解(下)11-20
2019-04-30
攻防世界web进阶区ics-04详解
2019-04-30
sql注入总结学习
2019-04-30
Linux png转jpg (convert命令)
2019-04-30
vscode git
2019-04-30
CodeForces - 456C Boredom (dp)
2019-04-30
CodeForces - 1042B Vitamins (思维)
2019-04-30
ACM 2013 长沙区域赛 Collision (几何)
2019-04-30
ACM 2014 鞍山区域赛 E - Hatsune Miku (dp)
2019-04-30
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 311756943 位访客
访问时间: 2024-05-07 17:06:35
访问IP: 3.139.82.23
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版