本文共 2291 字,大约阅读时间需要 7 分钟。
作为一款致力于成为数字化企业「最强大脑」的服务,高效高弹性的架构设计、简单易用的操作、强大的功能和澎湃的数据处理和分析能力,能够帮助我们解决与数据准备、数据管理、数据仓库、大数据和AI等方面有关的很多挑战。
我们将通过《数据“科学家”必读》系列文章带领大家全面体验Azure Synapse Analysis。本系列共分为六期内容,本篇是其中的第三期:
-
;
-
;
-
Azure Synapse Analysis与Azure Function服务的配合使用;
-
通过增量数据CDC对Azure Synapse Analysis中的数据进行更新;
-
借助Azure Data Factory工具实现数据处理水线的自动化操作;
-
借助Synapse Link的一键同步省略ETL过程,实现最新数据的直接访问。

在上一期内容中,我们已经介绍了如何通过Cosmos DB的ChangeFeed功能将OLTP数据向下游的OLAP系统快速、高效的增量同步。本期,我们将介绍如何借助Azure Functions实现ChangeFeed的增量数据抽取逻辑。
首先,回顾一下整个架构:
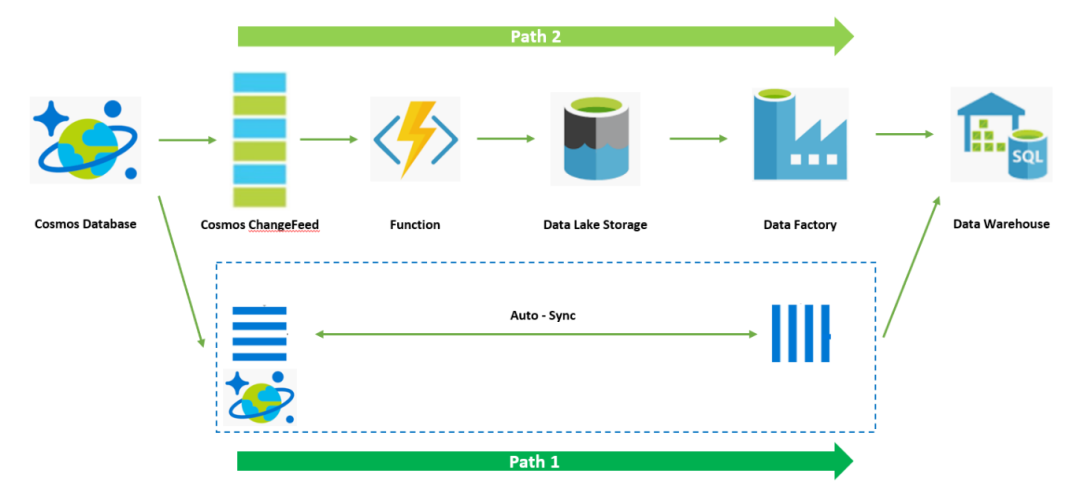
上一期我们曾经提到,借助Azure Functions服务可以简化整个逻辑的代码开发,Azure Functions服务中原生已经内置了很多与Azure其他服务原生集成的连接器,可以帮助客户实现与上下游服务的对接,用户无需关注连接器的实现,通过框架的调用,就可以直接通过对象访问到上下游服务中的数据,进而只需要关注业务逻辑即可。
Cosmos DB也在Azure Functions的支持之中,并且内置的连接器也是ChangeFeed实现的。用户可以直接开箱即用地实现ChangeFeed数据读取,无需自己维护抽取逻辑代码。Azure Functions原生支持的连接器如下:
| Type | 1.x | 2.x and higher1 | Trigger | Input | Output |
|---|---|---|---|---|---|
| ✔ | ✔ | ✔ | ✔ | ✔ | |
| ✔ | ✔ | ✔ | ✔ | ✔ | |
| ✔ | ✔ | ✔ | ✔ | ||
| ✔ | ✔ | ✔ | ✔ | ||
| ✔ | ✔ | ✔ | ✔ | ||
| ✔ | ✔ | ✔ | ✔ | ||
| ✔ | ✔ | ✔ | |||
| ✔ | ✔ | ✔ | |||
| ✔ | ✔ | ||||
| ✔ | ✔ | ✔ | ✔ | ||
| ✔ | ✔ | ||||
| ✔ | ✔ | ✔ | |||
| ✔ | ✔ | ||||
| ✔ | ✔ | ✔ | ✔ | ||
| ✔ | ✔ | ✔ | |||
| ✔ | ✔ | ✔ | ✔ | ||
| ✔ | ✔ | ✔ | |||
| ✔ | ✔ | ✔ | ✔ | ||
| ✔ | ✔ | ✔ | |||
| ✔ | ✔ | ✔ |
接下来,就一起看看该如何通过Azure Functions实现ChangeFeed的增量数据抽取逻辑。
1、准备开发环境。建议使用Visual Studio Code,其内置的Azure Functions开发扩展可以方便开发。详情可参考。
2、创建Azure Functions项目。注意在选择Trigger部分请选择cosmos db。详情可参考。
3、准备function.json配置文件。function.json主要描述Function与上下游数据连接的参数,其中下述配置中type:cosmosDBTrigger部分定义了Cosmos的连接信息,databaseName和collectionName需要替换为前面创建的cosmos db的名称,leaseCollectionName是Functions用来维护租约和CheckPoint所需的。connectionStringSetting参见后续local.settings.json。type:blob部分定义了Function下游存储Data Lake的连接信息,其中path参数定义了Function抽取增量变化数据在Data Lake中的存储路径,connection参数参见后续local.settings.json。另外feedPollDelay参数表示Functions服务轮询ChangeFeed数据的间隔,其单位为毫秒,在演示中建议可设置为60000,实际根据数据水线处理时间和数据更新需求来决定。

4、准备local.settings.json。该配置文件中定义了在上述function.json中所引用的连接密钥参数,其中Cosmos_DOCUMENTDB和ChangeFeedResultStorage内分别填入Cosmos和Data Lake的连接字符串,这些信息可在门户中对应资源的Access信息部分获取。

5、准备业务逻辑代码init.py。init.py是Function函数被拉起后的entrypoint函数,我们将前面介绍的抽取ChangeFeed增量变化数据的代码逻辑定义其中,下述演示代码中通过调用documents和outputblob,借助Functions内置的连接器实现对上下游数据访问,无需再自己开发集成代码。用户只需要开发自己的数据处理逻辑即可,演示中是将增量变化数据转存到Data Lake存储中。
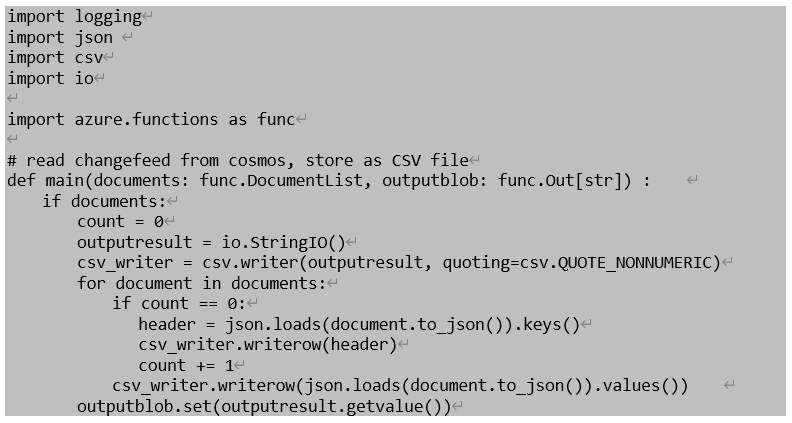
6、通过VS Code Functions本地调试工具进行测试,可以仿真通过前几期中介绍的数据插入函数在cosmos db内插入一些新的数据,然后在Data Lake中确认是否转存成功。详情可参考。
7、将Functions服务打包发布至Azure Functions服务中,上述开发测试均在本地完成,测试无误后将代码正式发布至Azure Functions服务。详情可参考。
至此,通过Azure Functions服务完成ChangeFeed读取及转存至Data Lake的操作已经顺利完成。整个Function代码中function.json中针对不同连接器的参数说明可参阅。
下一期,我们将介绍如何实现对所有这些CDC数据的ETL操作,敬请期待。
转载地址:https://microsoftchina.blog.csdn.net/article/details/108773467 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
