本文共 3725 字,大约阅读时间需要 12 分钟。
爬虫的爬取步骤:
- 准备好我们所需要的代理IP(代理IP的获取方法见:)
- 首先url是必要的
- 利用url进行爬取
- 将爬取爬取到的信息进行整合
- 保存到本地
具体的步骤:
- 利用代理IP和requests.get()语句获取网页
- BeautifulSoup()解析网页(BeautilfulSoup的功能可以参照这个)
- find_all()找到相应的标签
- 用.get_text()获取标签中的内容
- urlretrieve()将图片下载到本地(如果是文字直接保存到本地文件中即可)
代码示例:
headers = { "User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" } #获取随机ip proxies = get_random_ip(ip_list) req = requests.get(url=url,headers=headers,proxies=proxies) soup = BeautifulSoup(req.text,'lxml') targets_url_1 = soup.find('figure') targets_url = soup.find_all('noscript') 完整代码:
这是一份爬取知乎图片的教程代码,其中涉及的代理ip文件()
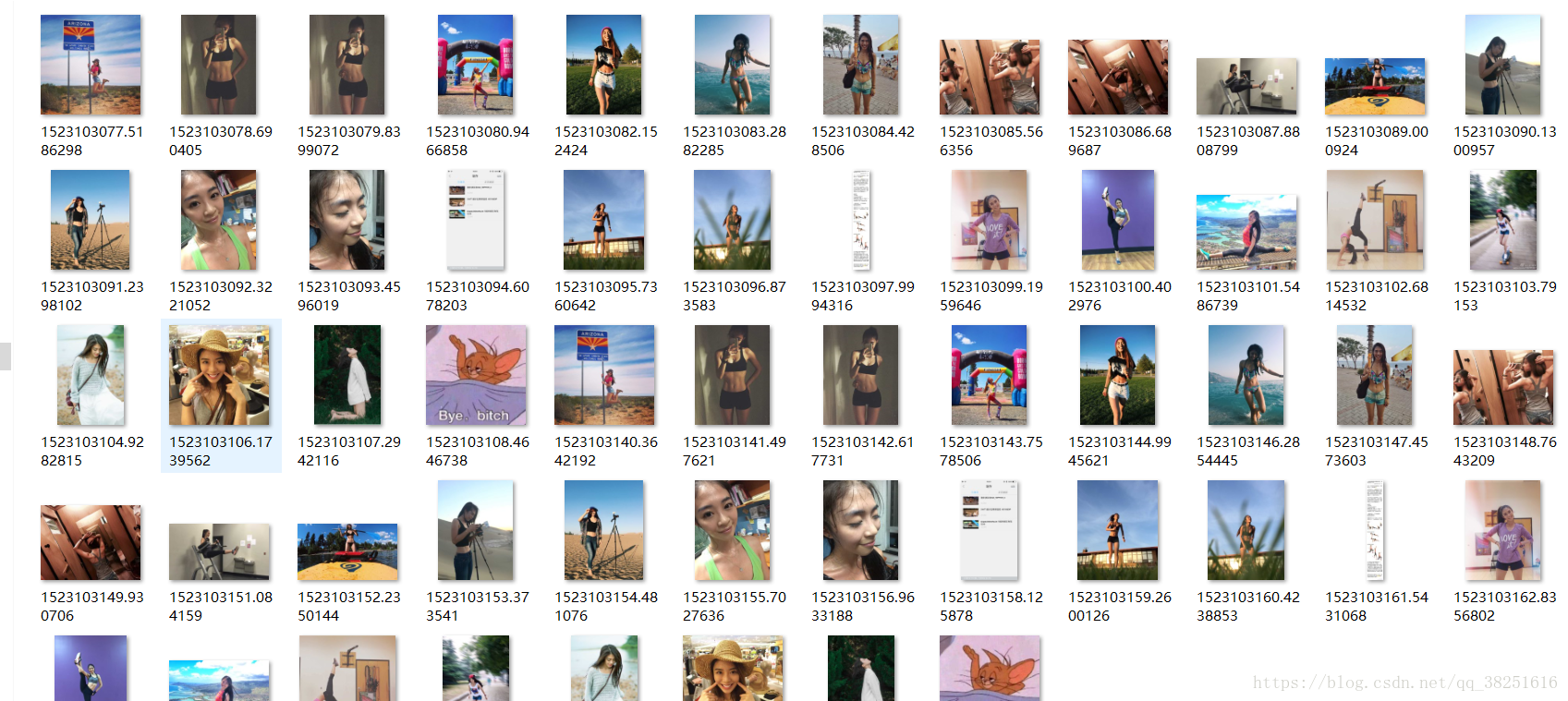
import requests,random,os,timefrom bs4 import BeautifulSoup from urllib.request import urlretrieve #获取IP列表并检验IP的有效性 def get_ip_list(): f=open('IP.txt','r') ip_list=f.readlines() f.close() return ip_list #从IP列表中获取随机IP def get_random_ip(ip_list): proxy_ip = random.choice(ip_list) proxy_ip=proxy_ip.strip('\n') proxies = {'https': proxy_ip} return proxies def get_picture(url,ip_list): headers = { "User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36" } #获取随机ip proxies = get_random_ip(ip_list) req = requests.get(url=url,headers=headers,proxies=proxies) soup = BeautifulSoup(req.text,'lxml') targets_url_1 = soup.find('figure') targets_url = soup.find_all('noscript') #保存图片链接 list_url = [] for each in targets_url: list_url.append(each.img.get('src')) for each_img in list_url: #判断文件夹(图库)是否存在,若不存在则创建文件夹 if '图库' not in os.listdir(): os.makedirs('图库') #下载图片 proxies = get_random_ip(ip_list) picture = '%s.jpg' % time.time() req = requests.get(url=each_img,headers=headers,proxies=proxies) with open('图库/{}.jpg'.format(picture),'wb') as f: f.write(req.content) #每爬取一张图片暂停一秒防止ip被封 time.sleep(1) print('{}下载完成!'.format(picture)) def main(): ip_list = get_ip_list() url = 'https://www.zhihu.com/question/22918070' get_picture(url,ip_list) if __name__ == '__main__': main() 成功后的截图:
爬虫简介:
爬虫简介:(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。网络爬虫始于一张被称作种子的统一资源地址(URL)列表。当网络爬虫访问这些统一资源定位器时,它们会甄别出页面上所有的超链接,并将它们写入一张“待访列表”,即所谓爬行疆域。此疆域上的URL将会被按照一套策略循环来访问。如果爬虫在执行的过程中复制归档和保存网站上的信息,这些档案通常储存,使他们可以较容易的被查看。阅读和浏览他们存储的网站上并即时更新的信息,这些被存储的网页又被称为“快照”。越大容量的网页意味着网络爬虫只能在给予的时间内下载越少部分的网页,所以要优先考虑其下载。高变化率意味着网页可能已经被更新或者被取代。一些服务器端软件生成的URL(统一资源定位符)也使得网络爬虫很难避免检索到重复内容。(摘自:)
爬虫分析:通过代码访问网页,将页面内容保存到本地。url是爬虫识别网页的重要标识,通过requests.get(url)获取网页的HTML代码,在通过BeautifulSoup解析HTML文件获取我们需要的内容,find()/find_all()是beautifulSoup的两个重要方法。
知识点补充:
关于爬虫中的headers:在使用python爬虫爬取数据的时候,经常会遇到一些网站的反爬虫措施,一般就是针对于headers中的User-Agent,如果没有对headers进行设置,User-Agent会声明自己是python脚本,而如果网站有反爬虫的想法的话,必然会拒绝这样的连接。而修改headers可以将自己的爬虫脚本伪装成浏览器的正常访问,来避免这一问题。
关于爬虫中的IP/proxies:在User Agent设置好后,还应该考虑一个问题,程序的运行速度是很快的,如果我们利用一个爬虫程序在网站爬取东西,一个固定IP的访问频率就会很高,这不符合人为操作的标准,因为人操作不可能在几ms内,进行如此频繁的访问。所以一些网站会设置一个IP访问频率的阈值,如果一个IP访问频率超过这个阈值,说明这个不是人在访问,而是一个爬虫程序。所以在我们需要爬取大量数据时,一个不断更换ip的机制是必不可少的,我代码中的IP.txt文件就是为这一机制准备的。
关于BeautifulSoup:简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。
- Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
- Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
- Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
BeautifulSoup的安装:
pip install beautifulsoup4关于BeautifulSoup的更多介绍,可以参考:
转载地址:https://mtyjkh.blog.csdn.net/article/details/79842583 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
