博客2-部分容器以及泛型
发布日期:2022-02-17 02:39:50
浏览次数:27
分类:技术文章
本文共 5013 字,大约阅读时间需要 16 分钟。
容器以及泛型
代码主要都是从马士兵课上看的打下来,写个博客加深下理解。
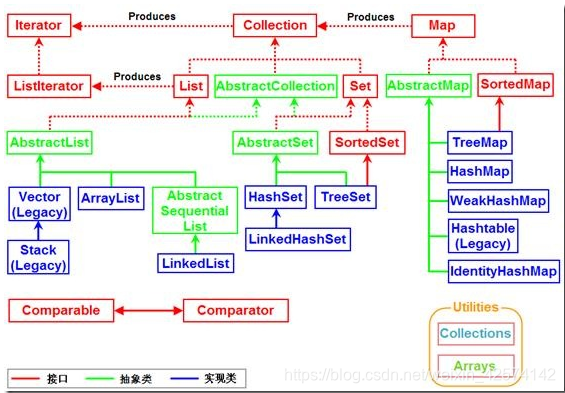 看到个博客觉得这个图非常好 https://blog.csdn.net/weixin_42574142/article/details/87125363
看到个博客觉得这个图非常好 https://blog.csdn.net/weixin_42574142/article/details/87125363
public class Name implements Comparable{ private String firstName,lastName; public Name(String firstName,String lastName){ this.firstName=firstName; this.lastName=lastName; } public String getFirstName(){return firstName;} public String getLastName(){return lastName ;} public String toString(){return firstName+" " +lastName;} @Override public boolean equals(Object o) { if (this == o) return true; if (!(o instanceof Name)) return false; Name name = (Name) o; return firstName.equals(name.firstName) && lastName.equals(name.lastName); } @Override public int hashCode() { return firstName.hashCode(); } public int compareTo(Object o){ Name n = (Name) o; int lastCmp= lastName.compareTo(n.lastName); return(lastCmp!=0 ? lastCmp : firstName.compareTo(n.firstName)); }} 先写一个name类过一会儿使用。
重写equals的时候记得重写hash,因为参与equals函数的字段,也必须都参与hashCode 的计算我们先写一个
import java.util.*;public class Test1{ public static void main(String[] args) { Set a = new HashSet(); Set b = new HashSet(); a.add("hello"); a.add("String "); a.add(new Name("zhang","san")); a.add(new Name("zhang","san")); a.add(new Integer(9)); System.out.println(a); }} 输出结果
[String , 9, hello, zhang san]
我们可以看出来hashset是无序无重复的
import java.util.Collection;import java.util.HashSet;import java.util.Iterator;public class Test{ public static void main(String[] args) { Collection c =new HashSet(); c.add(new Name("f3","l1")); c.add(new Name("f2","l2")); c.add(new Name("f1","l3")); c.add(new Name("f4","l4")); Iterator i =c.iterator(); while(i.hasNext()){ Name n =(Name )i.next(); System.out.println(n.getFirstName()); } }} 在这里我们使用了Iterator
什么是Iterator(迭代器)? 迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。Java中的Iterator功能比较简单,并且只能单向移动:
(1) 使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:iterator()方法是java.lang.Iterable接口,被Collection继承。
(2) 使用next()获得序列中的下一个元素。
(3) 使用hasNext()检查序列中是否还有元素。
(4) 使用remove()将迭代器新返回的元素删除。
总而言之就是我们可以通过Iterator访问我们容器里面的元素并且可以更改,由最上图可以知道所有容器都有个Iterator接口 输出结果f1f2f3f4
import java.util.*;public class Test3{ public static void main(String[] args) { List a=new LinkedList(); a.add(new Name("zhangsan","o")); a.add(new Name("wangwu","h")); a.add(new Name("lier","g")); a.add(new Name("xiaowang","q")); System.out.println(a); Collections.sort(a); System.out.println(a); }} list类分为LinkedList(有点链表的意思)和ArrayList(基本上就是数组)和Vector(类似于C++的动态数组)
list类里面就有排序的方法,再也不用自己写了,直接调用就完事儿 建议查下api文档,截图到markdown太麻烦import java.util.*;public class Test1 { public static void main(String[] args) { Map m1 = new HashMap(); Map m2 = new TreeMap();// m1.put("one",new Integer(1)); m1.put("one",1);// m1.put("two",new Integer(2)); m1.put("two",2);// m1.put("three",new Integer(3)); m1.put("three",3);// m2.put("A",new Integer(1)); m2.put("A",1);// m2.put("B",new Integer(2)); m2.put("B",2); System.out.println(m1.size()); System.out.println(m1.containsKey("one")); System.out.println(m2.containsValue(new Integer(1))); if(m1.containsKey("two")){// int i = ((Integer)m1.get("two")).intValue(); int i=(Integer)m1.get("two"); System.out.println(i); } Map m3 = new HashMap(m1); m3.putAll(m2); System.out.println(m3); }} map就是一个索引一个值,我们可以通过索引就可以找到这个值。
在这里大家都看到为什么没有用m2.put("B",new Integer(2)); 这个就要感谢我们的自动打包了,既减轻了程序负担,看起来也更加清晰。
import java.util.*;public class Test2{ public static void main(String[] args) { List c =new ArrayList (); c.add("aaa"); c.add("bbb"); c.add("ccc"); for(int i=0;i c2 =new HashSet (); c2.add("aaa");c2.add("bbb");c2.add("ccc"); for (Iterator it =c2.iterator();it.hasNext();){ String s=it.next(); System.out.println(s); } }} 在这里我们使用了泛型,虽然还没体现出优点。但介绍一下
1.性能好 对值类型使用非泛型集合类,在把值类型转换为引用类型,和把引用类型转换为值类型时,需要进行装箱和拆箱操作。装箱和拆箱的操作很容易实现,但是性能损失较大。假如使用泛型,就可以避免装箱和拆箱操作。 2、类型安全与ArrayList类一样,如果使用对象,可以在这个集合中添加任意类型。
可以让编译检查你装的是不是你想要的参数import java.util.*;public class Test16{ public static void main(String[] args) { Map m1 = new HashMap (); m1.put("one",1); m1.put("two",2); m1.put("three",3); System.out.println(m1.size()); System.out.println(m1.containsKey("one")); if(m1.containsKey("two")){ int i=m1.get("two"); System.out.println(i); } }} 这是上面Map的一个例子当我们用了泛型以后就一下子简介多了。
这一次使用了markdown排版,比上次舒服多了
转载地址:https://blog.csdn.net/qq_39814938/article/details/106086497 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
路过按个爪印,很不错,赞一个!
[***.219.124.196]2024年04月03日 00时12分30秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
LeetCode-122. 买卖股票的最佳时机 II(Goland实现)
2019-04-27
LeetCode-136. 只出现一次的数字(Goland实现)
2019-04-27
go-递归实现二叉树的三种排序方式(前序、中序、后序)【详细】
2019-04-27
LeetCode-409. 最长回文串(Goland实现)
2019-04-27
LeetCode-LCP 18. 早餐组合(Goland实现)
2019-04-27
C++从入门到进阶近100本书推荐电子书pdf
2019-04-28
蓝桥杯 - [2014年第五届真题]分糖果(模拟)
2019-04-28
蓝桥杯 - [2013年第四届真题]大臣的旅费(DFS)
2019-04-28
蓝桥杯 - [2013年第四届真题]带分数(全排列)
2019-04-28
蓝桥杯 - [2013年第四届真题]幸运数(模拟)
2019-04-28
蓝桥杯 - [2013年第四届真题]横向打印二叉树(排序二叉树)
2019-04-28
蓝桥杯 - [历届试题]网络寻路(枚举)
2019-04-28
牛客网 - [中南林业科技大学第十一届程序设计大赛]兑换零钱(背包问题)
2019-04-28
HDU - Robberies(01背包)
2019-04-28
HDU - 最大报销额(01背包|贪心)
2019-04-28
HDU - Coins(完全背包)
2019-04-28
JXFCZX — 砝码称重1(DFS+背包)
2019-04-28
JXFCZX — 质数和分解(完全背包)
2019-04-28
JXFCZX — 花店橱窗(动态规划)
2019-04-28
JXFCZX — 逃亡的准备(多重背包)
2019-04-28
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 308138544 位访客
访问时间: 2024-04-26 20:36:30
访问IP: 3.17.128.129
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版