本文共 2943 字,大约阅读时间需要 9 分钟。
文章目录
1. 拓扑距离
这里简单讲下hadoop的网络拓扑距离的计算。
在大数量的情景中,带宽是稀缺资源,如何充分利用带宽,完美的计算代价开销以及限制因素都太多。hadoop给出了这样的解决方案: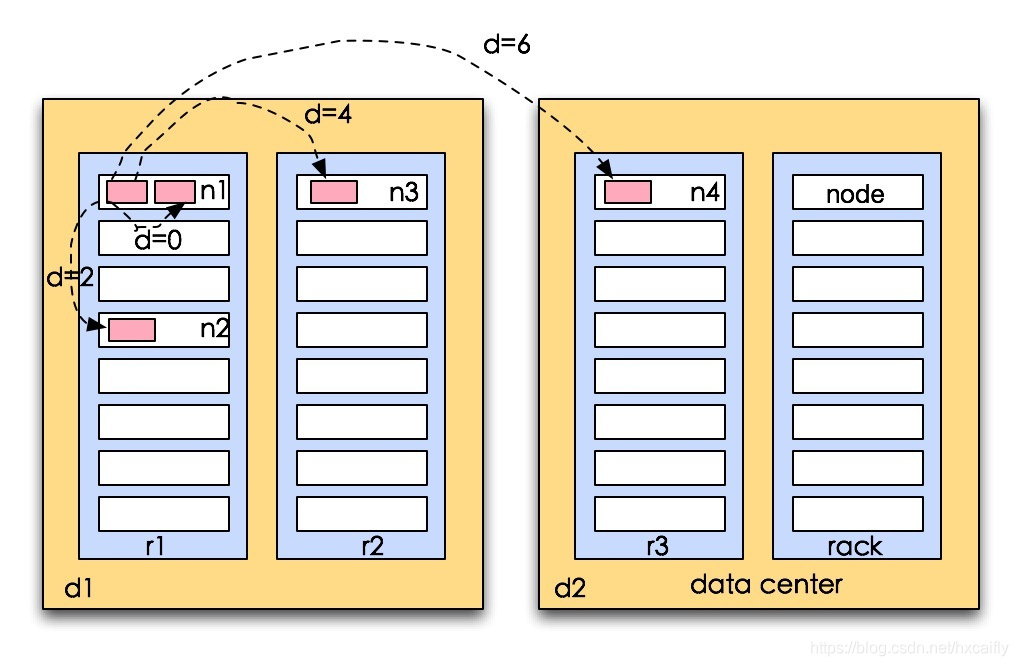 计算两个节点间的间距,采用最近距离的节点进行操作,如果你对数据结构比较熟悉的话,可以看出这里是距离测量算法的一个实例。
计算两个节点间的间距,采用最近距离的节点进行操作,如果你对数据结构比较熟悉的话,可以看出这里是距离测量算法的一个实例。 如果用数据结构表示的话,这里可以表示为tree,两个节点的距离计算就是寻找公共祖先的计算。
在现实情况下比较典型的情景如下,tree结构的节点由数据中心data center,这里表示为d1,d2,机架rack,这里表示为r1,r2,r3,还有服务器节点node,这里表示为n1,n2,n3,n4
1.distance(d1/r1/n1,d1/r1/n1)=0 (相同节点) 2.distance(d1/r1/n1,d1/r1/n2)=2 (相同机架不同节点) 3.distance(d1/r1/n1,d1/r2/n3)=4 (相同数据中心不同机架) 4.distance(d1/r1/n1,d2/r3/n4)=6 (不同数据中心)2.副本存放
先来定义一下,namenode节点选择一个datanode节点去存储block副本得过程就叫做副本存放,这个过程的策略其实就是在可靠性和读写带宽间得权衡。那么我们来看两个极端现象:
- 把所有的副本存放在同一个节点上,写带宽是保证了,但是这个可靠性是完全假的,一旦这个节点挂掉,数据就全没了,而且跨机架的读带宽也很低。
- 所有副本打散在不同的节点上,可靠性提高了,但是带宽有成了问题。
我们来讲下hadoop默认的方案:
3. 把第一副本放在和客户端同一个节点上,如果客户端不在集群中,那么就会随即选一个节点存放。 4. 第二个副本会在和第一个副本不同的机架上随机选一个 5. 第三个副本会在第二个副本相同的机架上随机选一个不同的节点 6. 剩余的副本就完全随机节点了。如果重复因子是3的话,就会形成下图这样的网络拓扑:
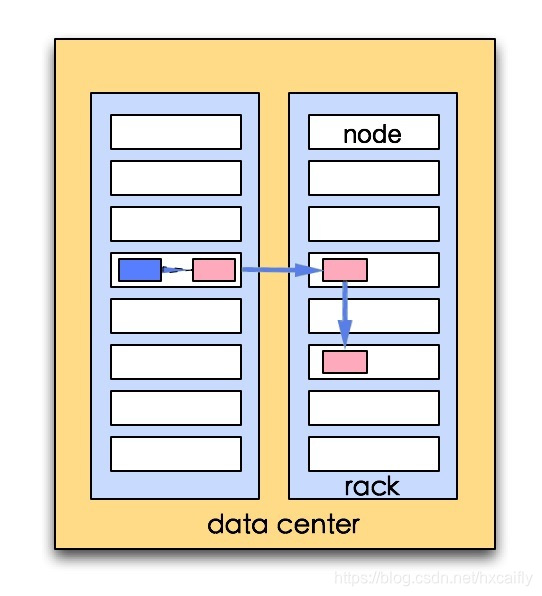
- 可靠性:block存储在两个机架上
- 写带宽:写操作仅仅穿过一个网络交换机
- 读操作:选择其中得一个机架去读
- block分布在整个集群上
3. HDFS中的block、packet、chunk
很多博文介绍HDFS读写流程上来就直接从文件分块开始,其实,要把读写过程细节搞明白前,你必须知道block、packet与chunk。下面分别讲述。
1. block
这个大家应该知道,文件上传前需要分块,这个块就是block,一般为128MB,当然你可以去改,不顾不推荐。因为块太小:寻址时间占比过高。块太大:Map任务数太少,作业执行速度变慢。它是最大的一个单位。
2. packet
packet是第二大的单位,它是client端向DataNode,或DataNode的PipLine之间传数据的基本单位,默认64KB。
3. chunk
chunk是最小的单位,它是client向DataNode,或DataNode的PipLine之间进行数据校验的基本单位,默认512Byte,因为用作校验,故每个chunk需要带有4Byte的校验位。所以实际每个chunk写入packet的大小为516Byte。由此可见真实数据与校验值数据的比值约为128 : 1。(即64*1024 / 512)
例如,在client端向DataNode传数据的时候,HDFSOutputStream会有一个chunk buff,写满一个chunk后,会计算校验和并写入当前的chunk。之后再把带有校验和的chunk写入packet,当一个packet写满后,packet会进入dataQueue队列,其他的DataNode就是从这个dataQueue获取client端上传的数据并存储的。同时一个DataNode成功存储一个packet后之后会返回一个ack packet,放入ack Queue中。
4. HDFS写流程
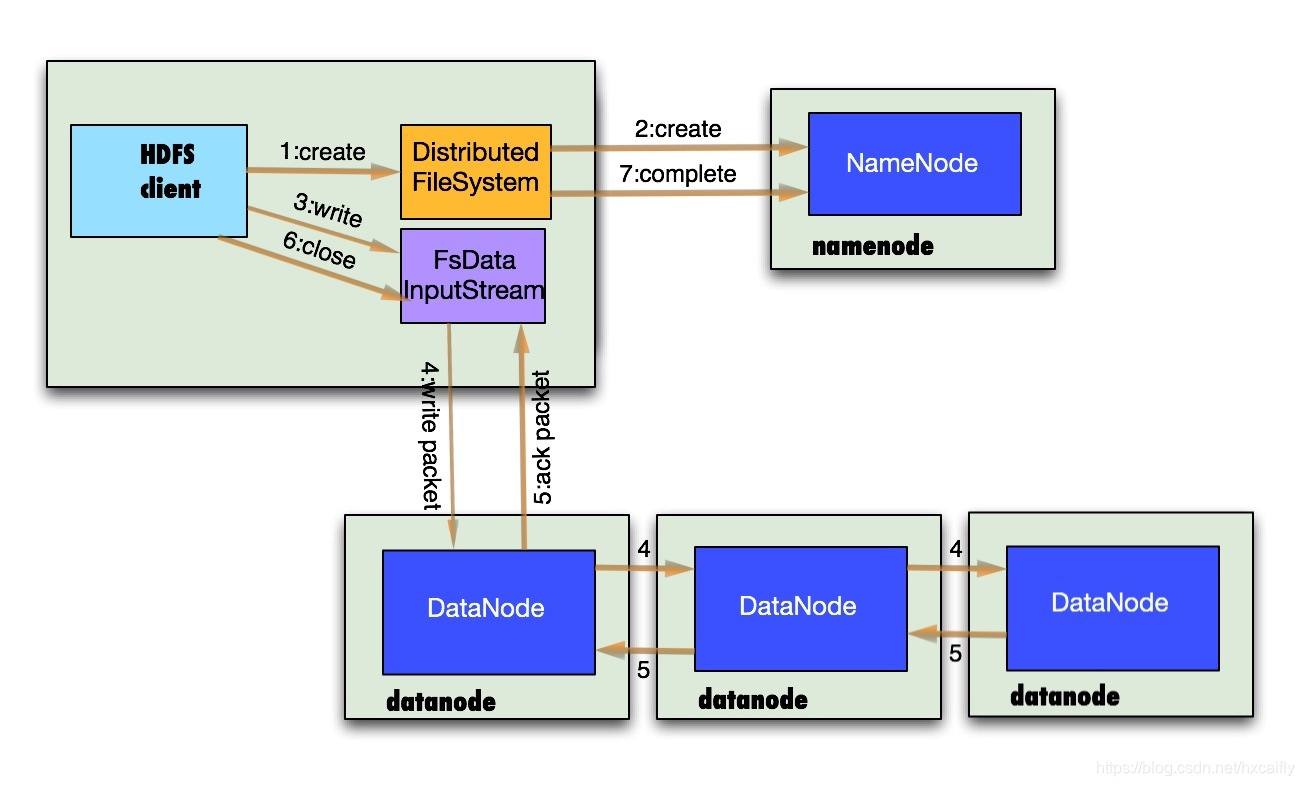
- 客户端向NameNode发出写文件请求。
- 检查是否已存在文件、检查权限。若通过检查,直接先将操作写入EditLog,并返回输出流对象。 (注:WAL,write ahead log,先写Log,再写内存,因为EditLog记录的是最新的HDFS客户端执行所有的写操作。如果后续真实写操作失败了,由于在真实写操作之前,操作就被写入EditLog中了,故EditLog中仍会有记录,我们不用担心后续client读不到相应的数据块,因为在第5步中DataNode收到块后会有一返回确认信息,若没写成功,发送端没收到确认信息,会一直重试,直到成功)、
- client端按128MB的块切分文件,生成block。
- client将NameNode返回的分配的可写的DataNode列表和Data数据一同发送给最近的第一个DataNode节点,此后client端和NameNode分配的多个DataNode构成pipeline管道,client端向输出流对象中写数据。client每向第一个DataNode写入一个packet,这个packet便会直接在pipeline里传给第二个、第三个…DataNode。 (注:并不是写好一个块或一整个文件后才向后分发) 。
- 每个DataNode写完一个块后,会返回确认信息。 (注:并不是每写完一个packet后就返回确认信息,个人觉得因为packet中的每个chunk都携带校验信息,没必要每写一个就汇报一下,这样效率太慢。正确的做法是写完一个block块后,对校验信息进行汇总分析,就能得出是否有块写错的情况发生)
- 写完数据,关闭输输出流。
- 发送完成信号给NameNode。 (注:发送完成信号的时机取决于集群是强一致性还是最终一致性,强一致性则需要所有DataNode写完后才向NameNode汇报。最终一致性则其中任意一个DataNode写完后就能单独向NameNode汇报,HDFS一般情况下都是强调强一致性)
5. HDFS读流程
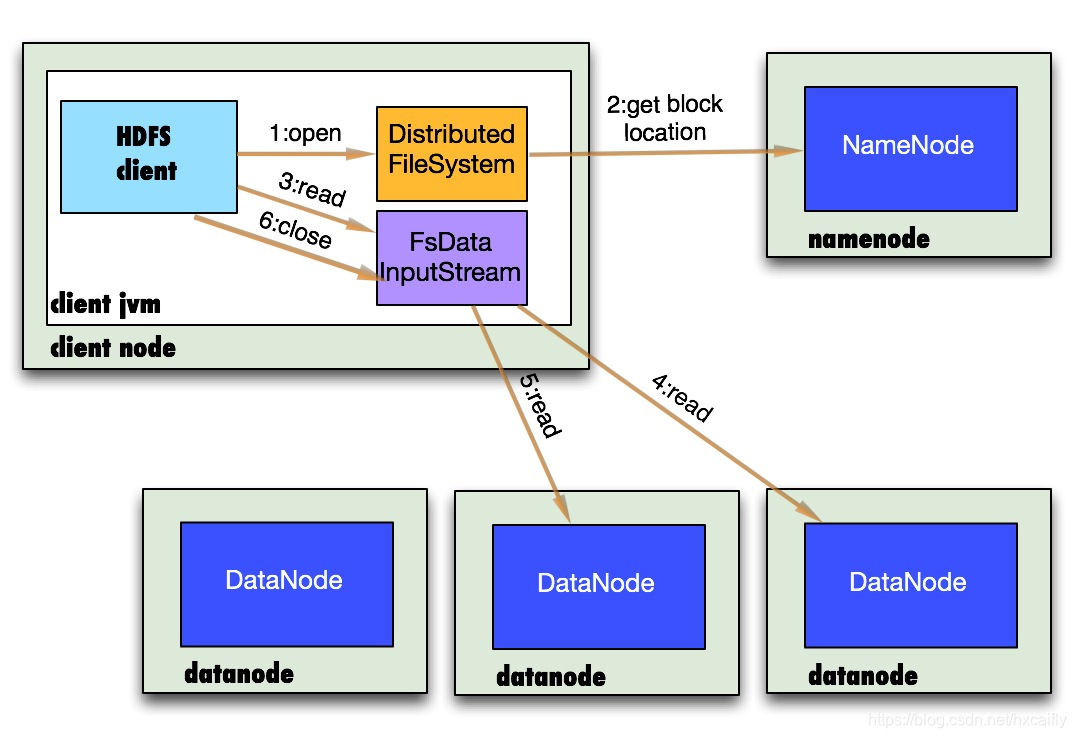
- client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
- 就近挑选一台datanode服务器,请求建立输入流 。
- DataNode向输入流中中写数据,以packet为单位来校验。
- 关闭输入流。
6. 读写过程,数据完整性如何保持?
通过校验和。因为每个chunk中都有一个校验位,一个个chunk构成packet,一个个packet最终形成block,故可在block上求校验和。
HDFS 的client端即实现了对 HDFS 文件内容的校验和 (checksum) 检查。当客户端创建一个新的HDFS文件时候,分块后会计算这个文件每个数据块的校验和,此校验和会以一个隐藏文件形式保存在同一个 HDFS 命名空间下。当client端从HDFS中读取文件内容后,它会检查分块时候计算出的校验和(隐藏文件里)和读取到的文件块中校验和是否匹配,如果不匹配,客户端可以选择从其他 Datanode 获取该数据块的副本。
转载地址:https://blog.csdn.net/hxcaifly/article/details/87973352 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
