本文共 3172 字,大约阅读时间需要 10 分钟。
re模块
想在python中使用正则表达式,可以使用re模块来辅助筛选。
1.findall
查找数据中所有符合条件的数值,最后的结果以列表形式输出。(贪婪匹配)
import reres = re.findall('l', 'hello') # ['l', 'l'] 2.finditer
功能与findall一致,不过最后以迭代器形式输出。
import reres = re.finditer('l', 'hello')# 3.search
查找数据中符合条件的数值,查找到一个就直接停止。(非贪婪匹配)
search输出形式为迭代器,span表示目标在数据中的坐标位置,可以用group方法只输出数据。
import reres = re.search('a', 'abcabc')# res.group() # a 4.match
判断头部是否匹配条件,只匹配头部。
match输出形式也是迭代器,但头部匹配不成立的情况下会输出None
import reres = re.match('a', 'balance') # None 5.compile
compile可以提前制作一个正则表达式,需要时直接提用,节约代码空间
import reobj = re.compile('a')res = re.findall(obj, 'abcabc') # 相当于把条件用变量的形式输入 re模块的特殊功能
1.分组
给判断条件中的字符添加括号,就是给条件分组。所有字符都会参与匹配,但是输出时优先显示分组内的字符。
import reres = re.findall('abc', 'abcabcabcabc')# ('abc', 'abc', 'abc', 'abc')res1 = re.findall('a(b)c', 'abcabcabcabc')# ('b', 'b', 'b', 'b') 2.别名
别名就是给分组取名,输出时如果写了别名优先输出对应的分组。
取名方式为在括号内输入?p<组名>
import reres = re.search('a(?P b)(?P c)','abcabcabcabc')print(res.group('id'))print(res.group('name')) 网络爬虫简介
网络爬虫就是从计算机到互联网上获取信息,除了自主上网获取信息外,还可以使用代码获取网页上的信息。
第三方模块下载
在python中自带第三方模块的下载与导入。
使用命令提示符
pip解释器版本名 install 模块名pip3.10 install requests
执行之后等待下载进度完成即导入成功。
注意:第三方模块导入之后无法跨版本使用,只能在安装的版本调用。
默认的下载地址为国外网站,也可以手动更改成国内网站
pip3.10 install 模块名 -i 源地址
部分国内下载地址
清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/ 中国科学技术大学 :http://pypi.mirrors.ustc.edu.cn/simple/ 华中科技大学:http://pypi.hustunique.com/ 豆瓣源:http://pypi.douban.com/simple/ 腾讯源:http://mirrors.cloud.tencent.com/pypi/simple 华为镜像源:https://repo.huaweicloud.com/repository/pypi/simple/使用pycharm
打开pycharm左上角的file / setting,选中左侧的project:文件名,在这里会显示当前解释器安装的所有模块目录。
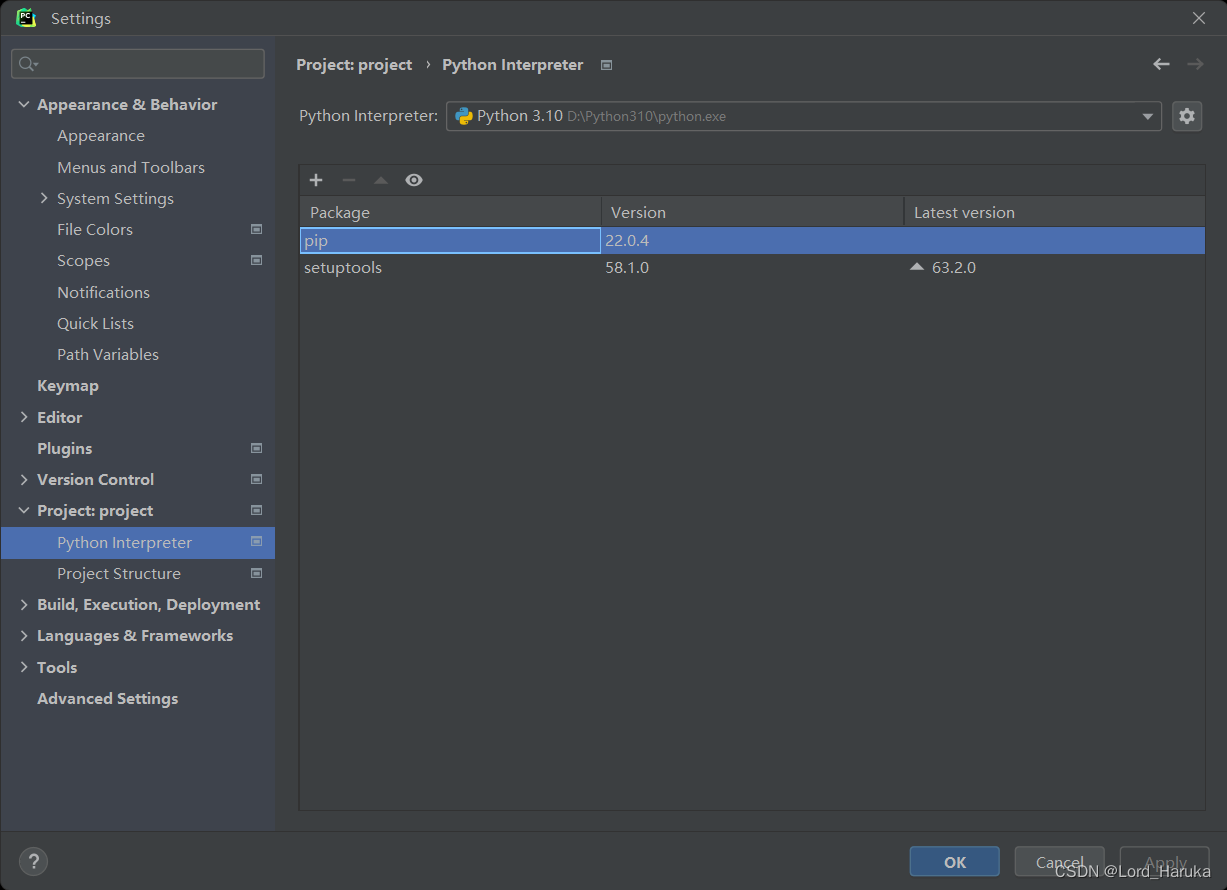
然后点击任意模块进入下载界面,在上面搜索栏输入模块名,选中之后点击左下角的install即可自动下载和导入模块。
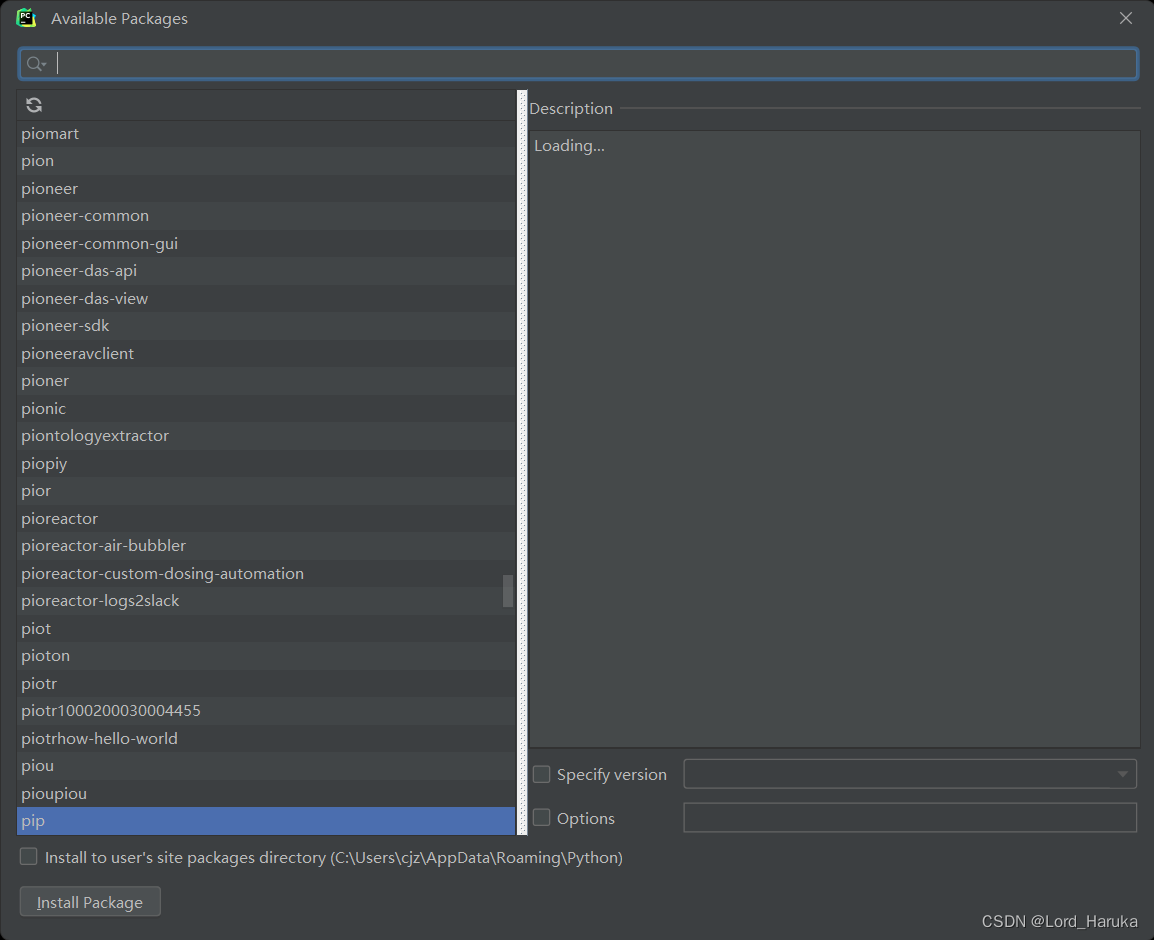
使用requests模块获取信息
1.获取网址及信息
网页本身由代码构成,所有信息都可以在代码上赋值到本地。
本次例子由
import requestsres = requests.get('网址') # 相当于在浏览器输入网址print(res.content) # 获取页面bytes类型的数据print(res.text) # 获取解码之后的数据,相当于在网页按f12查看源代码with open(r'hn.html','wb') as f: #为了避免每次执行都要从网络上下载数据,可以先保存到本地 f.write(res.content) 2.读取数据
import re,requestwith open(r'hn.html', 'r', encoding='utf8') as f: # 读取页面数据 data = f.read()company_name_list = re.findall('(.*?)
', data)#获取所有的分公司名称company_addr_list = re.findall("(.*?)
", data)#获取所有的分公司地址print(company_addr_list)company_email_list = re.findall("(.*?)
", data)#获取所有的分公司邮箱print(company_email_list)company_phone_list = re.findall("(.*?)
", data)#获取所有的分公司电话print(company_phone_list) 3.整合打包信息
res = zip(company_name_list, company_addr_list, company_email_list, company_phone_list)#将获得的信息按照上述名称分组
4.格式化输出
for i in res: print(""" 公司名称:%s 公司地址:%s 公司邮箱:%s 公司电话:%s """ % i)# ('红牛杭州分公司', '杭州市上城区庆春路29号远洋大厦11楼A座', '310009', '0571-87045279/7792') openpyxl模块
openpyxl模块是python中用于操控链接excel表格的模块之一,openpyxl相比其他使用excel的模块操作更加简单。
1.创建excel文件
from openpyxl import Workbook # 导入模块wb = Workbook() #创建文件wb1 = wb.create_sheet('成绩表') #创建表wb.save(r'111.xlsx') #将文件命名为括号内字符并保存 2.写入数据
方式一:坐标
将位置填写在括号内
wb1['A1'] = '信息'
方式二:cell
wb1.cell(row=3, column=2, value='信息')
方式三:append
使用append时会以一次一行的方式添加数据,如果没有数据输入可以用None代替。
wb1.append(['username','password','age','gender','hobby'])wb1.append(['jason1',123,18,'male','read'])wb1.append(['jason2',123,18,'male','read'])
转载地址:https://blog.csdn.net/Lord_Haruka/article/details/125896413 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
