本文共 10518 字,大约阅读时间需要 35 分钟。
目录
看了几天的机器学习,发现还是一件蛮有意思的事情,这次主要总结一些评价指标的相关内容。我觉得总结的挺不错,因为自己真的是发现理解这几个概念了。
一、评价指标
评价指标主要有以下几种,后面会逐一对这些进行分析
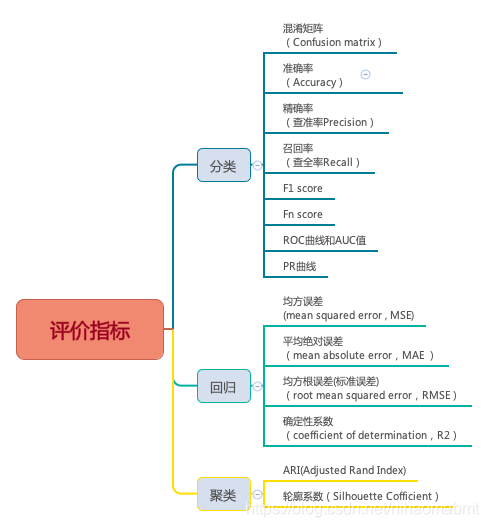
二、混淆矩阵(Confusion Matrix)
1.简单介绍
混淆矩阵又称为误差矩阵,用来总结分类模型预测结果的情形。可以很清晰的看出多个类别是否混淆,其中对角线就是做出正确预测的分类,其他的就是发生了误判的分类。
混淆矩阵的每一行表示一个实际类别,每一列表示一个预测类别。
通常有两种形式,一种就是二分类,另外一种就是多分类。
这就是一个二分类的混淆矩阵

下面这个就是一个多分类的混淆矩阵
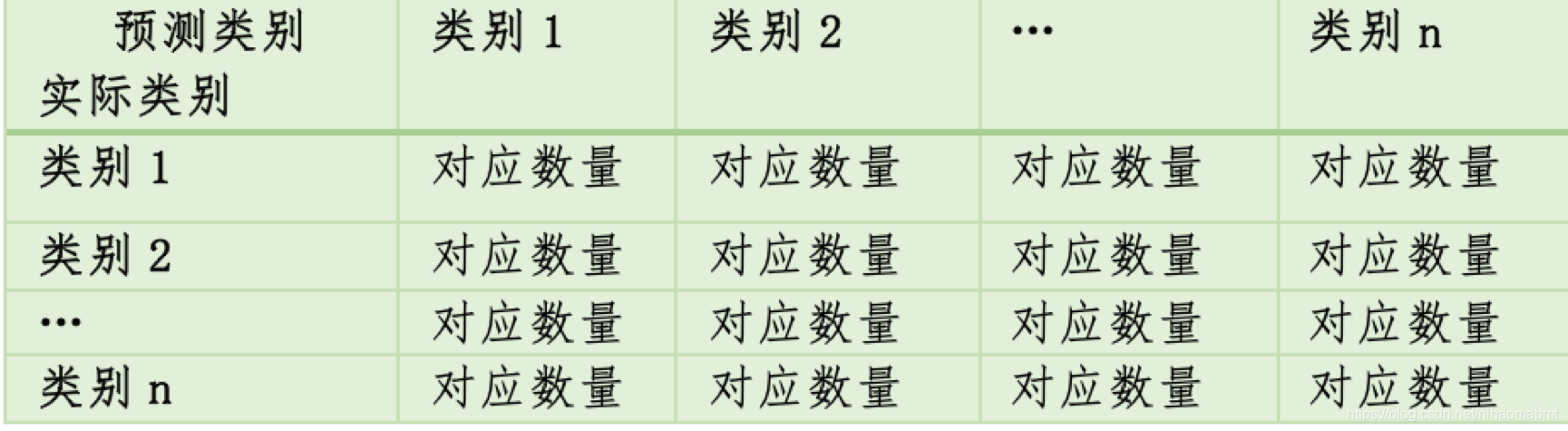
2.二分类混淆矩阵
二分类混淆矩阵主要就是为了对分类模型中的正类和负类的判断情况。每一行代表实际类别,每一列代码预测类别
| 预测类别 实际类别 | Positive | Negative |
| True | True Positive(TP) | False Negative(FN) |
| False | False Positive(FP) | True Negative(TN) |
TP(True Positive):指的是实际上为正类,预测也为正类,预测正确
TN(True Negative):指的是实际上为负类,预测也为负类,预测正确
FN(False Negative):指的是实际上是正类,预测成负类,预测错误(我们最终的目标就是得到正类的样本的情况,所以这也被称为漏报率)
FP(False Positive):值得是实际上是负类,预测成正类,预测错误(也被称为误报率)。
当有了预测样本和实际样本就可以通过sklearn的confusion_matrix可以得到这个混淆矩阵。
sklearn.metrics.confusion_matrix(y_true, y_pred, labels=None, sample_weight=None)
其中参数说明:
| 参数 | 含义 |
| y_true | 实际样本分类 |
| y_pred | 预测样本分类 |
| labels | 是一个集合类型的参数,给出的类别,通过这个类别来生成混淆矩阵,在通俗一点就是,就是该集合就是我们生成的混淆矩阵对应的x轴和y轴对应的标签顺序。对应一个二分类来说,传入[正类,负类],就会按照对应正类和负类的值进行统计正类和负类的个数;同样对应一个多分类来说,传入[类别1,类别2,类别3.....],就会按照对应的类别1,类别2,类别3.....分别统计对应的个数。 |
| sample_weight | 样本权重,n为矩阵,n为样本类别 |
我们举一个实例来说明这个混淆矩阵。我们有一个预测恶性肿瘤的分类模型,
实际样本为 [0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0]
预测样本为 [1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1]
1表示恶性肿瘤(正类),0表示良性肿瘤(负类),通过实际样本和预测样本我们得到混淆矩阵为
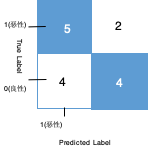
从上面统计结果中可以看到:
TP = 5 :实际为恶性肿瘤,预测为恶性肿瘤
TN = 4 : 实际为良性肿瘤,预测为良性肿瘤
FP = 4 :实际为良性肿瘤,预测为恶性肿瘤(吓死人,浪费金钱和时间)
FN = 2 :实际为恶性肿瘤,预测为良性肿瘤 (误诊,耽误治疗)
利用Python从样本来得到这个混淆矩阵,代码如下
y_pred = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1]y_true = [0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0]#y_true 真实类#y_pred 预测类print("confusion_matrix: ")#labels=[1,0]的顺序决定最后的1为正类还是负类matrix = confusion_matrix(y_true,y_pred,labels=[1,0])print(matrix)print("TP:{}".format(matrix[0][0]))print("TN:{}".format(matrix[1][1]))print("FN:{}".format(matrix[0][1]))print("FP:{}".format(matrix[1][0])) 得到Python的输出为:
confusion_matrix: [[5 2] [4 4]]TP:5TN:4FN:2FP:4
3.多类别混淆矩阵
简单在看一个运行多分类混淆矩阵的实例,有一个判断是蚂蚁、鸟、还是猫的分类模型。
实际样本为:["cat", "ant", "cat", "cat", "ant", "bird", "cat", "ant", "bird"]
预测样本为:["ant", "ant", "cat", "cat", "ant", "cat", "bird", "ant", "cat"]
根据上面的样本可以得出对应的混淆矩阵为:
| 预测类别实际类别 | ant | bird | cat |
| ant | 3 | 0 | 0 |
| bird | 0 | 0 | 2 |
| cat | 1 | 1 | 2 |
利用Python的confusion_matrix来看我们统计的是否正确,Python代码如下:
y_true = ["cat", "ant", "cat", "cat", "ant", "bird", "cat", "ant", "bird"]y_pred = ["ant", "ant", "cat", "cat", "ant", "cat", "bird", "ant", "cat"]print(confusion_matrix(y_true, y_pred, labels=["ant", "bird", "cat"]))
得到Python的输出为:
mul confusion_matrix: [[3 0 0] [0 0 2] [1 1 2]]
三、准确率(Accuracy)
再将下面几个概念的时候,先拿简单的二分类模型来说明下。主要就是对上面提到的混淆矩阵中的TP、TN、FP、FN在对应这不同样本分类的比例关系。
准确率就是所有的样本中被正确分类的样本。
1.二分类的混淆矩阵
对于二分类混淆矩阵通俗点来说:预测正确的分类占所有样本的比例,也就是对角线上的样本占所有样本的比例。对应着数学公式为:
![]()
对应这Python中的
sklearn.metrics.accuracy_score(y_true, y_pred, normalize=True, sample_weight=None)
其中参数说明:
| 参数 | 含义 |
| y_true | 实际样本分类 |
| y_pred | 预测样本分类 |
| normalize | 返回正确分类的比例,默认的为true |
| sample_weight | 样本权重,n为矩阵,n为样本类别 |
对应着在第二部分的混淆矩阵中对应的那个恶性肿瘤的实例计算准确率的结果如下:
Accurary = (5+4)/15 = 0.6
Python代码为:
print("accuracy_score: {:.5}".format(accuracy_score(y_true, y_pred))) 对应的输出结果为:
accuracy_score: 0.6
2.多分类混淆矩阵
对于多类混淆矩阵中的准确率的计算公式为:
![]()
对应着第二部分提到的多分类的混淆矩阵来看,对应的准确率的计算结果如下:
Accuracy = (3+2)/9 = 0.55556
对应得Python的代码如下:
print("accuracy_score: {:.5}".format(accuracy_score(y_true, y_pred))) 对应的输出结果为:
accuracy_score: 0.55556
四、精确率(Precision)
精确率,也称为查准率,主要指的是在所有的分类结果中某一个类别的样本中,被正确分类样本所占的比例。
1.二分类的混淆矩阵
对于二分类混淆矩阵通俗点来说:在预测为正类的样本中,预测正确的样本所占的比例。对应的数学公式为:
![]()
对应Python中的
sklearn.metrics.precision_score(y_true, y_pred, labels=None, pos_label=1, average=’binary’, sample_weight=None)
其中参数说明
| 参数 | 含义 |
| y_true | 实际样本分类 |
| y_pred | 预测样本分类 |
| labels | 是一个集合类型的参数,给出的类别,通过这个类别来生成混淆矩阵,在通俗一点就是,就是该集合就是我们生成的混淆矩阵对应的x轴和y轴对应的标签顺序。对应一个二分类来说,传入[正类,负类],就会按照对应正类和负类的值进行统计正类和负类的个数;同样对应一个多分类来说,传入[类别1,类别2,类别3.....],就会按照对应的类别1,类别2,类别3.....分别统计对应的个数。 |
| pos_label | 指定正类的,仅仅适用于average=binary的情况。默认为None,只有当数据标签为{0,1}或{-1,1}的数据的时候才能默认 |
| average | 字符串,多类别或者多标签的时候需要该参数。 'binary':默认值,二分类,有pos_label指定的类的结果 'micro':统计全局TP和FP来计算 'macro':计算每个标签的未加权均值(不考虑不平衡) 'weighted':计算每个标签等加权均值(考虑不平衡) 'samples':计算每个实例找出其均值 None,每个类别的分数将会返回 |
| sample_weight | 样本权重,n为矩阵,n为样本类别 |
对应着在第二部分的混淆矩阵中对应的那个恶性肿瘤的实例计算准确率的结果如下:
Precision = 5/(5+4) = 0.55556
Python代码为:
print("precision_score: {:.5}".format(precision_score(y_true,y_pred))) 对应的输出结果为:
precision_score: 0.55556
2.多分类混淆矩阵
在多类别的混淆矩阵中该精确率的计算公式就是:某一类别被正确分类的样本数占被预测成该样本数的比例关系,

对应着第三部分中提到的多类混淆矩阵中,拿cat的精确率进行举例:
![]()
对于该第三部分提到的混淆矩阵的实例中的cat的精确率为:
Precision = 2/(0+2+2) =0.5
我们可以看到在Python的precision_score函数中,有一个average的参数来决定输出对应的精确率的不同,我们先简单的输出所有类别的精确率:
print("precision_score average=None : ")print(precision_score(y_true, y_pred, average=None)) 对应的Python 输出为:
precision_score average=None : [0.75 0. 0.5 ]
我们可以看到对应的cat的精确率也是0.5
五、召回率 (Recall)
主要指的是在某一类别被正确分类的样本数占实际样本数的比例。主要看的是查的全不全
1.二分类的混淆矩阵
对于二分类混淆矩阵通俗点来说:在预测为正类样本中占实际样本数的比例。对应的数学公式为:
![]()
对应的Python的函数为
sklearn.metrics.recall_score(y_true, y_pred, labels=None, pos_label=1,average='binary',sample_weight=None)
其中参数同precision_score,不在单独介绍。
对应着在第二部分的混淆矩阵中对应的那个恶性肿瘤的实例计算召回率的结果如下:
Recall = 5/(5+2) = 0.71429
Python代码为:
print("recall_score: {:.5}".format(recall_score(y_true, y_pred))) 对应的输出结果为:
recall_score: 0.71429
2.多分类混淆矩阵
在多类别的混淆矩阵中该精确率的计算公式就是:某一类别被正确分类的样本数占实际上该样本数的比例关系,
![]()
对应着第三部分中提到的多类混淆矩阵中,拿cat的召回率进行举例:

对于该第三部分提到的混淆矩阵的实例中的cat的召回率为:
Precision = 2/(1+1+2) =0.5
我们可以看到在Python的precision_score函数中,有一个average的参数来决定输出对应的精确率的不同,我们先简单的输出所有类别的精确率:
print("recall_score average=None")print(recall_score(y_true, y_pred, average=None)) 对应的Python 输出为:
recall_score average=None[1. 0. 0.5]
我们可以看到对应的cat的召回率也是0.5。
3.对比精确率和召回率
对比精确率和召回率,精确率(Precision)是看的被正确分类的样本占预测之后的对应的分类样本的比例,而召回率(Recall)是被正确分类的样本占实际的对应的分类样本比例。
六、 F1-Score和Fn-Score
1.F1-Score
F1-Score为精确率和召回率的调和均值。计算公式为:
![]()
对应的Python的函数为:
sklearn.metrics.f1_score(y_true, y_pred, labels=None, pos_label=1, average='binary', sample_weight=None)
参数说明见上面 precision_score
对应着第二部分的二分类矩阵的Python的代码如下:
print("f1_score: {:.5}".format(f1_score(y_true, y_pred))) 输出最后的结果为:
f1_score: 0.625
对应第二部分的多分类矩阵的Python代码如下:
print("f1_score average=None")print(f1_score(y_true, y_pred, average=None)) 对应的输出结果为:
f1_score average=None[0.85714286 0. 0.5 ]
2.Fn-Score
召回率的重要程度是精确率的n倍。当n为1的时候,即F1-Score
![]()
当β=2时,即F2-Score,表示Recall的影响要大于Precision;
当β=0.5时,即F0.5-Score,表示Recall的影响要小于Precision
七、ROC(Receiver Operating Characteristic)曲线和AUC(Area Under Curve)分数
首先针对二分类器来看下ROC曲线
1.几个概念
(1)真正类率TPR(True Positive Rate)
又称为灵敏度,判断为正确的正类样本中占整个实际正类样本的个数比例。对应的公式为:
![]()
(2)负正类率FPR(False Positive Rate)
误判断为正类的样本数(即实际为负类,预测成了正类)占整个实际负类样本的个数比例。对应的公式为:
![]()
(3)正负类率FNR(False Negative Rate)
误判断为负类的样本数(即实际为正类,预测成了负类)占整个实际正类样本的个数比例。对应的公式为:
![]()
(4)真负类率TNR(True Negative Rate)
判断正确的负类样本数占整个负类样本个数的比例,对应的公式为:
![]()
从上面的几个定义上来看,这几个概念都是预测的样本分类与实际样本数进行的比例。
2.ROC曲线
更直观的去比较两个或者多个分类器的好坏。
ROC曲线的横轴为FPR,纵轴为TPR。
![]()
![]()
ROC曲线上有四个点和一条线:
(1)第一个点(0,1)即FPR=0,TPR=1,也就是FP=0,FN=0:非常完美的一个分类器,所有的分类都分类正确;
(2)第二个点(1,0)即FPR=1,TPR=0,也就是TN=0,TP=0:最糟糕的分类器,所有的分类都判断错误;
(3)第三个点(1,1)即FPR=1,TPR=1,也就是TN=0,FN=0:该分类器预测的样本全是正类样本;
(4)第四个点(0,0)即FPR=0,TPR=0,也就是FP=0,TP=0:该分类器预测的样本全是负类样本;
(5)一条线y=x即FPR=0.5,TPR=0.5:表示该分类器 预测的样本一半是正类样本,一半是负类样本。
ROC曲线越接近左上角,说明该分类器的性能越好。当实际样本集中的数据出现正负样本数不平衡的时候,ROC曲线基本上保持不变。
对应的Python的函数为:
sklearn.metrics.roc_curve(y_true,y_score,pos_label=None,sample_weight=None, drop_intermediate=True)
| 参数 | 含义 |
| y_true | 实际的样本数据 |
| y_score | 预测的样本数据,可以是数据标签(即预测的样本数据值),也可以是概率值,与y_true一致的数组 |
| pos_label | 指定正类的。默认为None,只有当数据标签为{0,1}或{-1,1}的数据的时候才能默认 |
| sample_weight | 样本权重,n为矩阵,n为样本类别 |
| drop_intermediate | 是否放弃不出现在ROC曲线上的次优阀值 |
返回值有三个:FPR、TPR和threshold(阀值)返回的每个为一维数组。
简单的在说下阀值的这个概念。假设一个阀值为0.8,大于这个值的样本为正类,小于这个值的样本为负类。如果阀值减到0.5,那么就有更多的实例被识别为正类,也就是提高了被识别为正类的比例,即提高了TPR,但同时也提高了更多的负类样本被误识别为正类样本,提高了FPR。
而这个roc_curve函数返回的一维数组threshold,就是对预测值排序之后的列表,排序从大到小。
每个ROC曲线上的每个点对应一个threshold,而对于一个分类器,每个threshold下会有一个TPR和FPR。当threshold最大时,即TPR和FPR最小,即ROC曲线的原点位置,TPR=0,FPR=0,此时TP=0,FP=0;当threshold最小时即TPR和FPR值最大,即ROC曲线的(1,1)位置。我们可以看到threshold和TPR、FPR成反比关系。随着threshold的增加,TPR和FPR减小,ROC上的点向左下角移动。
(1)y_score为样本数据
对应的第二部分提到的二分类的混淆矩阵中对应的实例中的FPR、TPR和threshold对应的 Python代码如下:
print("ROC的FPR TPR Threshold : ")#print(roc_curve(y_true, y_pred, pos_label=1))print(roc_curve(y_true, y_pred, pos_label=1)[0])print(roc_curve(y_true, y_pred, pos_label=1)[1])print(roc_curve(y_true, y_pred, pos_label=1)[2]) 对应的输出如下:
ROC的FPR TPR Threshold : [0. 0.5 1. ][0. 0.71428571 1. ][2 1 0]
也就是返回三个阀值:
- threshold=2的时候, 也就是所有>=2的均为正类样本,显然FPR=0,TPR=0,此时预测结果中没有任何正类样本;
- threshold=1的时候, 也就是所有>=1的均为正类样本,FPR=0.5,TPR=0.71428571
- threshold=0的时候, 也就是所有>=0的均为正类样,本FPR=1,TPR=1,此时预测结果中均为正类样本
(2)y_score为概率值
yy_true = [1, 1, 2, 2]yy_scores = [0.1, 0.4, 0.35, 0.8]print("ROC 的 y_score为概率 FPR TPR Threshold : ")print(roc_curve(yy_true, yy_scores, pos_label=1)[0])print(roc_curve(yy_true, yy_scores, pos_label=1)[1])print(roc_curve(yy_true, yy_scores, pos_label=1)[2]) 对应的Python输出为:
ROC 的 y_score为概率 FPR TPR Threshold : [0. 0.5 0.5 1. 1. ][0. 0. 0.5 0.5 1. ][1.8 0.8 0.4 0.35 0.1 ]
与为样本数据的情况一样,具体的不在多介绍 。
ROC曲线还可以来计算均值平均精度(mean average precision)。可以通过改变阀值来选择最好的结果时得到平均精度。
3.AUC分数
AUC分数就是ROC曲线下面的面积,该面积越大,意味着分类器效果越好。显然面积不可能超过1.
由于ROC曲线并不能清晰说明哪个分类器效果更好,而AUC作为一个数值,对应着AUC的值越大,说明这个分类器效果更好。
由于ROC曲线一般都会在y=x之上,所以AUC分数的取值范围在0.5~1之间。
对应的Python的函数为:
sklearn.metrics.auc(x, y, reorder=False)
其中参数含义
| 参数 | 含义 |
| x | ROC曲线的x坐标,即FPR |
| y | ROC曲线的y坐标,即TPR |
| recorder | True:假设在关系的情况下,曲线是上升的,就像ROC曲线,如果不上升,则是错误的。 默认为false |
对应的Python代码如下:
fpr = roc_curve(y_true, y_pred, pos_label=1)[0];print(fpr)tpr = roc_curve(y_true, y_pred, pos_label=1)[1]print(tpr)print("auc: {:.5}".format(auc(fpr, tpr))) 对应的运行结果如下:
auc: 0.60714
当然在sklearn中也提供一个直接根据预测值和实际值来求AUC值的方法
roc_auc_score(y_true, y_score, average="macro", sample_weight=None, max_fpr=None)
上面的几个运行结果都是对应着二分类器来说的,至于多分类器后面在找资料去查看。
八、PR(Precision Recall)曲线
1.PR曲线

表现的是Precision和Recall之间的关系。
PR曲线横轴为Recall,纵轴为Precision。
![]()
![]()
PR曲线越往右上角,性能越好。PR曲线对样本比例比较敏感,当分类器中样本的数据不平衡的时候,会产生很大的变化。
2.ROC曲线和PR曲线对比
在正负样本都足够的情况下,ROC曲线足够反映出分类器的判断能力。但是在正负样本极度不平衡的情况下,PR曲线会比ROC曲线更敏感。主要分为两种情况:
(1)正样本数远大于负样本数,PR曲线和ROC曲线差别不大
(2)正样本数远小于负样本数,PR曲线会更敏感,会产生很大的变化
所以,可以通过ROC曲线来对比两个或多个分类器的优良,然后根据PR曲线来衡量在正负样本数极度不平衡的情况下的性能,从而对模型进行改进。
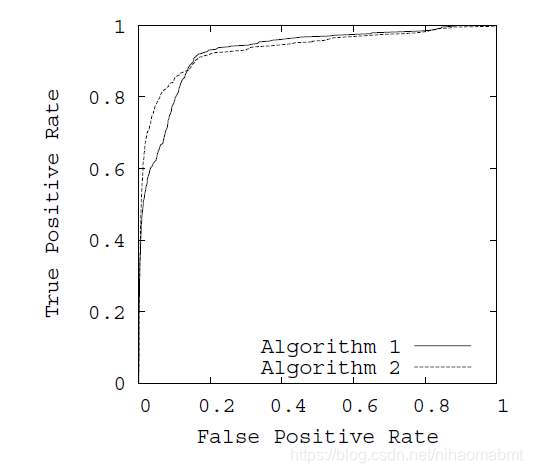
下面看一个ROC曲线和PR曲线来看两个模型的性能
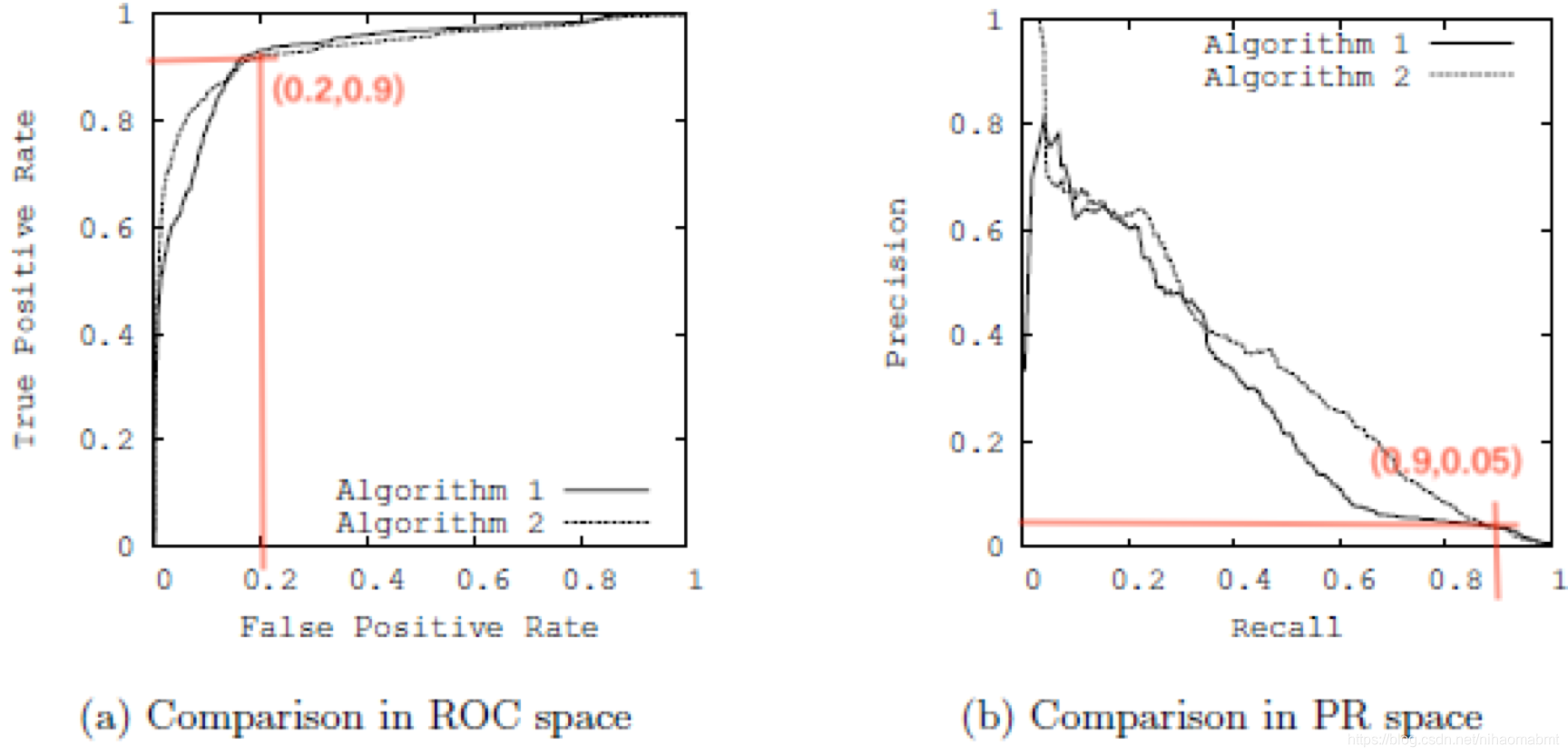
从图a中可以看出,分类器1和1都非常接近左上角,应该还是不错的两个分类器,但是对应着b图,两个分类器离右上角还有点距离,说明这两个分类器需要在进行优化,也就是说明现在的样本出现了极度不平衡。
从图a中找一个点(0.2,0.9)即FPR=0.2,TPR=0.9。由于ROC曲线的横轴为FPR,纵轴为TPR,PR曲线横轴为Recall,纵轴为Precision,而FRP的定义恰好于Recall的定义一致,也就是ROC曲线的横轴恰好为PR曲线的纵轴,所以找到b图对应的(0.9,0.05)点,即Recall=0.9,Precision=0.05。根据这几个参数的计算公式可以得到
![]()
假设实际样本正类样本数为100个(即TP+FN=100):
(1)根据TPR=0.9,可以得到预测为正类的样本数TP=90;
(2)根据Precision=0.05,可以得到把负类预测为正类的的样本数(即误判为正类的样本数)FP=1710;
(3)根据FPR=0.2,可以得到实际负类为样本数FP+TN=8550;
从上面的计算过程中可以看出,实际正类样本数为100,而实际负类样本数为8550,正负样本出现了极度不平衡。所以ROC曲线判断的该分类器已经很不错了,但是PR曲线却能够更有效的体现该分类器的缺点。
九、总结
这篇博文写下来,发现之前理解不好的概念,也都很清晰了,我觉得这个写的还可以,欢迎大家指正里面有问题的地方。对于回归和聚类提到的评价指标,后面会再继续分析。
加油!
转载地址:https://blog.csdn.net/nihaomabmt/article/details/102741743 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
