本文共 5931 字,大约阅读时间需要 19 分钟。
目录
需要分析的问题
有一些泰坦尼克的数据集,里面的数据的特征包括了姓名、票的类别、存活、乘坐班、年龄、登录、目的地、房间、票、船和性别。我们看下大体的数据集内容如下:
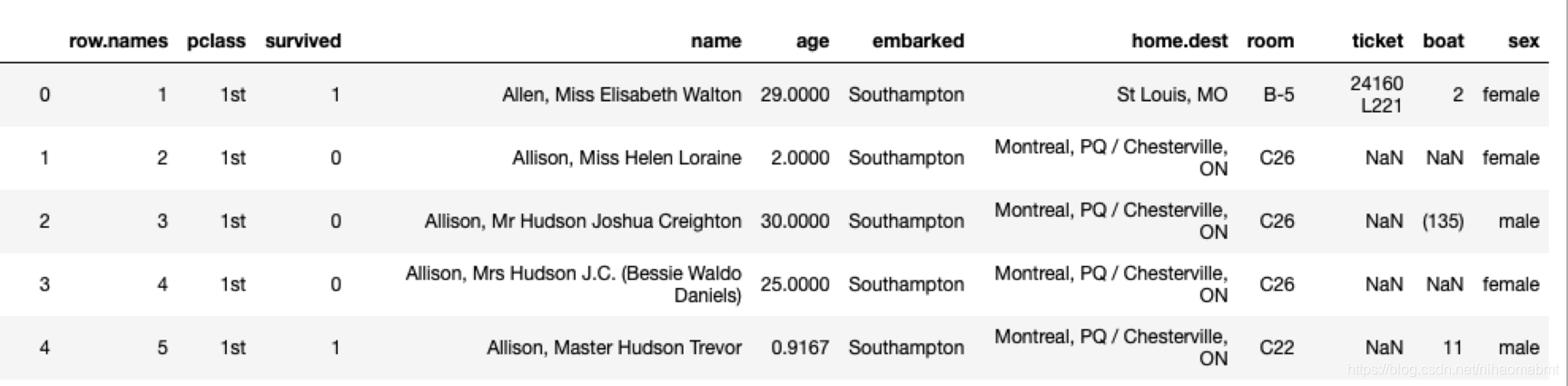
pclass :社会阶层的代表:(1st,2 st,3 st)
其中这些数据集中年龄数据存在缺失。
我们在分析该问题的时候,首要的第一步就是要选好特征值和目标值,我们要挑选哪些特征对判断乘客能够生存有影响。像姓名、目的地、房间号这些信息根本不会对是否生存产生影响,会想电影中,当时在逃生的时候,头等舱的乘客优先登船,妇女小孩优先登船,所以年龄(age)、票的类型(pclass)、性别(sex)对是否生存有关键影响,那么我们就先把年龄(age)、票的类型(pclass)、性别(sex)作为特征,目标值显示就是是否能够生存(surived)。
流程分析
流程分析主要包括下面几步:
(1)获取数据,显然要导入pandas,来读取本地的txt的内容,代码如下:
titanic = pd.read_csv("tree_titanic.txt") 我们输出里面的数据集的内容就是:
(2)数据处理
- 准备好特征值和目标值
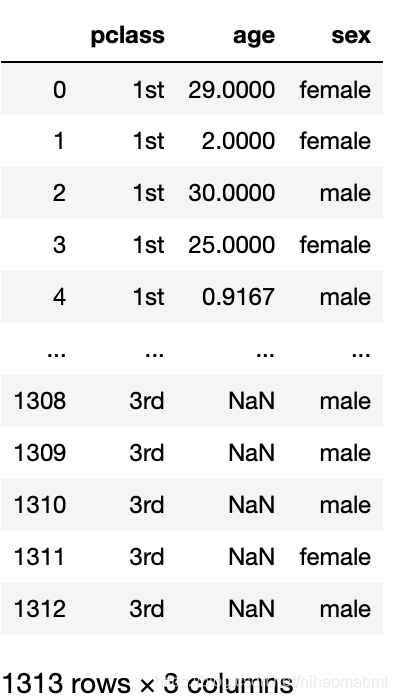
刚才我们分析的特征值和目标值为年龄(age)、票的类型(pclass)、性别(sex)、是否生存(surived),那我们这里的操作就是从数据集中选出这些列对应的内容,代码如下:
# (2)数据处理 - 需要进行挑选特征值和目标值 x = titanic[["pclass", "age", "sex"]] y = titanic["survived"]
输出下x和y的内容如下:

- 缺失值处理
我们从x的输出的内容看到,有些age的数据是缺失的,那么我们这边就用所有年龄的平均值来补充这里的数据,代码如下:
# (2)数据处理 - 因为年龄数据有缺失,则需要进行填充:采用年龄的平均值进行补充 x["age"].fillna(x["age"].mean(), inplace=True)
输出x的内容如下:
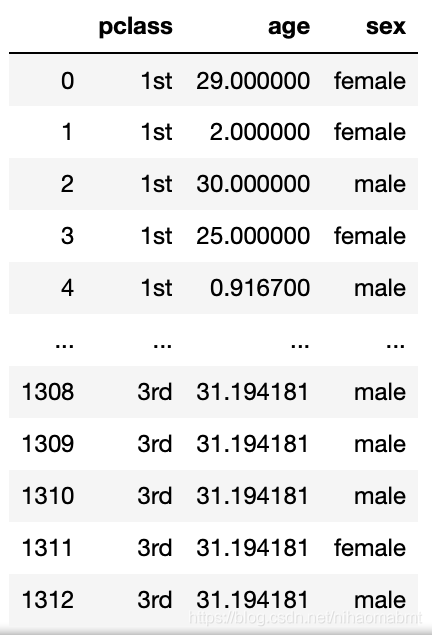
很明显后面的这些age的数据已经用年龄的平均值进行补充。
- 转换字典
由于里面的sex对应的特征值为female和male,是非数值数据,那么我们在转换这个数据的时候想到采用one-hot编码的形式,那么就需要采用特征工程中的字典抽取DictVectorizer,对sex的数据进行转换成数值数据,因为在DictVectorizer在转换的时候需要的是字典类型的数据,那么我们现在就需要把上面得到的x转换成字典类型,代码如下:
# (2)数据处理 - 转换成字典,然后进行特征工程的字典抽取 x = x.to_dict(orient="records")
输出转换之后的数组中的前5个的内容如下:
[{'pclass': '1st', 'age': 29.0, 'sex': 'female'}, {'pclass': '1st', 'age': 2.0, 'sex': 'female'}, {'pclass': '1st', 'age': 30.0, 'sex': 'male'}, {'pclass': '1st', 'age': 25.0, 'sex': 'female'}, {'pclass': '1st', 'age': 0.9167, 'sex': 'male'}] (3)划分数据集
就是将数据划分为训练集和测试集,代码如下:
# (3)划分训练集、测试集 x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
(4)特征工程 – 字典特征抽取
# (4)特征工程-进行字典特征抽取 transfer = DictVectorizer() x_train = transfer.fit_transform(x_train) x_test = transfer.transform(x_test)
(5)决策树预估器流程
先不设置各种参数来看下结果
classifier = DecisionTreeClassifier() classifier.fit(x_train, y_train) y_predict = classifier.predict(x_test) print("测试结果为:\n", (y_predict == y_test)) (6)模型评估
# (6)模型评估 score = classifier.score(x_test,y_test) print("准确度为: ", score) 准确度如下:
准确度为: 0.7811550151975684
(7)决策树可视化
由于通过特征工程之后,特征已经发生变化,但是完全可以从transfer获取特征。
# (7)可视化 export_graphviz(classifier, out_file="/Users/j1/Documents/机器学习/code/machinelearning/estimator/tree_titanic.dot", feature_names=transfer.get_feature_names())
不在贴决策树的图,图片太大了。
(8)交叉验证
我们刚才没有设置决策树的参数,其实我们可以通过交叉验证的方式来设置树的max_depth。
#(5)训练模型 classifier = DecisionTreeClassifier() param = {"max_depth": range(2,50, 1)} classifier = RandomizedSearchCV(classifier, param_distributions=param, cv=8) classifier.fit(x_train, y_train) y_predict = classifier.predict(x_test) print("测试结果为:\n", y_predict == y_test) print("最好预估器为:\n", classifier.best_estimator_) # (6)模型评估 score = classifier.score(x_test,y_test) print("准确度为: ", score) 我们看下输出的结果为:
最好预估器为: DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=6, max_features=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, presort=False, random_state=None, splitter='best')准确度为: 0.7811550151975684
我们看下通过交叉验证的时候,得到的max_depth为6.我有点搞不清楚的地方是,这里的通过交叉验证的classifier为什么不能直接可视化,会抛出异常
Traceback (most recent call last): File "/Users/j1/Documents/机器学习/code/machinelearning/estimator/tree_titanic.py", line 57, intree() File "/Users/j1/Documents/机器学习/code/machinelearning/estimator/tree_titanic.py", line 51, in tree export_graphviz(classifier, out_file="/Users/j1/Documents/机器学习/code/machinelearning/estimator/tree_titanic.dot", feature_names=transfer.get_feature_names()) File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/sklearn/tree/export.py", line 757, in export_graphviz check_is_fitted(decision_tree, 'tree_') File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/sklearn/utils/validation.py", line 914, in check_is_fitted raise NotFittedError(msg % {'name': type(estimator).__name__})sklearn.exceptions.NotFittedError: This RandomizedSearchCV instance is not fitted yet. Call 'fit' with appropriate arguments before using this method.
整体代码如下:
import pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.feature_extraction import DictVectorizerfrom sklearn.tree import DecisionTreeClassifier, export_graphvizfrom sklearn.model_selection import RandomizedSearchCVdef tree(): # (1)获取数据 titanic = pd.read_csv("tree_titanic.txt") # "row.names","pclass","survived","name","age","embarked","home.dest","room","ticket","boat","sex" print(titanic.head()) # (2)数据处理 - 需要进行挑选特征值和目标值 x = titanic[["pclass", "age", "sex"]] y = titanic["survived"] print("特征:\n", x.head()) # (2)数据处理 - 因为年龄数据有缺失,则需要进行填充:采用年龄的平均值进行补充 x["age"].fillna(x["age"].mean(), inplace=True) # (2)数据处理 - 转换成字典,然后进行特征工程的字典抽取 x = x.to_dict(orient="records") print("转换成字典之后的特征:\n", x) # (3)划分训练集、测试集 x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22) # (4)特征工程-进行字典特征抽取 transfer = DictVectorizer() x_train = transfer.fit_transform(x_train) x_test = transfer.transform(x_test) print("特征工程之后的训练集的特征:\n", x_train) print("特征:\n", transfer.get_feature_names()) #(5)训练模型 classifier = DecisionTreeClassifier() param = {"max_depth": range(2,50, 1)} #classifier = RandomizedSearchCV(classifier, param_distributions=param, cv=8) classifier.fit(x_train, y_train) y_predict = classifier.predict(x_test) print("测试结果为:\n", y_predict == y_test) # print("最好预估器为:\n", classifier.best_estimator_) # (6)模型评估 score = classifier.score(x_test,y_test) print("准确度为: ", score) # (7)可视化 export_graphviz(classifier, out_file="/Users/j1/Documents/机器学习/code/machinelearning/estimator/tree_titanic.dot", feature_names=transfer.get_feature_names()) return Noneif __name__ == '__main__': tree()
总结
似乎对于整个流程有一点点感觉了,有好多东西还需要自己去学习,加油
转载地址:https://blog.csdn.net/nihaomabmt/article/details/103382995 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
