目录
众所周知,Redis 服务器是一个事件驱动程序。那么事件驱动对于 Redis 而言有什么含义?源码中又是如何实现事件驱动的呢?今天,我们一起来认识下 Redis 服务器的事件驱动。
对于 Redis 而言,服务器需要处理以下两类事件:
- 文件事件(file event):Redis 服务器通过套接字与客户端进行连接,而文件事件就是服务器对套接字操作的抽象。服务器与客户端的通信会产生相应的文件事件,而服务器则通过监听并处理这些事件来完成一系列的网络通信操作。
- 时间时间(time event):Redis 服务器中的一些操作(比如 serverCron 函数)需要在给定的时间点执行,而时间事件就是服务器对这类定时操作的抽象。
接下来,我们先来认识下文件事件。
1 文件事件
Redis 基于 Reactor 模式开发了自己的网络事件处理器,这个处理器被称为文件事件处理器(file event handler):
- 文件事件处理器使用 IO 多路复用程序来同时监听多个套接字,并根据套接字目前执行的任务来为套接字关联不同的事件处理器。
- 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时,与操作相对应的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
虽然文件处理器以单线程方式运行,但通过 IO 多路复用程序监听多个套接字,既实现了高性能的网络通信模型,又可以很好的与 Redis 服务器中其它同样以单线程运行的模块进行对接,保持了 Redis 内部单线程设计的简洁。
1.1 文件事件处理器的构成
图 1 展示了文件事件处理器的四个组成部分:
- 套接字;
- IO 多路复用程序;
- 文件事件分派器(dispatcher);
- 事件处理器;
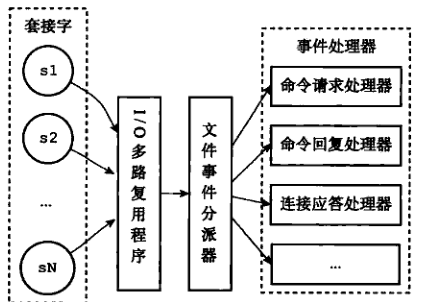
文件事件是对套接字的抽象。每当一个套接字准备好执行连接应答(accept)、写入、读取、关闭等操作时,就好产生一个文件事件。因为一个服务器通常会连接多个套接字,所以多个文件事件有可能会并发的出现。
而 IO 多了复用程序负责监听多个套接字,并向文件事件分派器分发那些产生事件的套接字。
尽管多个文件事件可能会并发的出现,但 IO 多路复用程序总是会将所有产生事件的套接字都放到一个队列里面,然后通过这个队列,以有序、同步的方式,把每一个套接字传输给文件事件分派器。当上一个套接字产生的事件被处理完毕之后(即,该套接字为事件所关联的事件处理器执行完毕),IO 多路复用程序才会继续向文件事件分派器传送下一个套接字。如图 2 所示:

文件事件分派器接收 IO 多路复用程序传来的套接字,并根据套接字产生的事件类型,调用相应的事件处理器。
服务器会为执行不同任务的套接字关联不同的事件处理器。这些处理器本质上就是一个个函数。它们定义了某个事件发生时,服务器应该执行的动作。
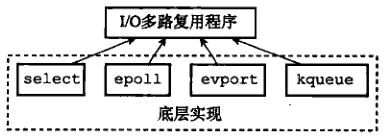
1.2 IO 多路复用程序的实现
Redis 的 IO 多路复用程序的所有功能都是通过包装常见的 select、epoll、evport 和 kqueue 这些 IO 多路复用函数库来实现的。每个 IO 多路复用函数库在 Redis 源码中都对应一个单独的文件,比如 ae_select.c、ae_poll.c、ae_kqueue.c 等。
由于 Redis 为每个 IO 多路复用函数库都实现了相同的 API,所以 IO 多路复用程序的底层实现是可以互换的,如图 3 所示:
Redis 在 IO 多路复用程序的实现源码中用 #include 宏定义了相应的规则,**程序会在编译时自动选择系统中性能最高的 IO 多路复用函数库来作为 Redis 的 IO 多路复用程序的底层实现,这保证了 Redis 在各个平台的兼容性和高性能。对应源码如下:
/* Include the best multiplexing layer supported by this system. * The following should be ordered by performances, descending. */#ifdef HAVE_EVPORT#include "ae_evport.c"#else #ifdef HAVE_EPOLL #include "ae_epoll.c" #else #ifdef HAVE_KQUEUE #include "ae_kqueue.c" #else #include "ae_select.c" #endif #endif#endif
1.3 事件的类型
IO 多路复用程序可以监听多个套接字的 ae.h/AE_READABLE 和 ae.h/AE_WRITABLE 事件,这两类事件和套接字操作之间有以下对应关系:
- 当服务器套接字变得可读时,套接字会产生 AE_READABLE 事件。此处的套接字可读,是指客户端对套接字执行 write、close 操作,或者有新的可应答(acceptable)套接字出现时(客户端对服务器的监听套接字执行 connect 操作),套接字会产生 AE_READABLE 事件。
- 当服务器套接字变得可写时,套接字会产生 AE_WRITABLE 事件。
IO 多路复用程序允许服务器同时监听套接字的 AR_READABLE 事件和 AE_WRITABLE 事件。如果一个套接字同时产生了两个事件,那么文件分派器会优先处理 AE_READABLE 事件,然后再处理 AE_WRITABLE 事件。简单来说,如果一个套接字既可读又可写,那么服务器将先读套接字,后写套接字。
1.4 文件事件处理器
Redis 为文件事件编写了多个处理器,这些事件处理器分别用于实现不同的网络通信需求。比如说:
- 为了对连接服务器的各个客户端进行应答,服务器要为监听套接字关联连接应答处理器。
- 为了接收客户端传了的命令请求,服务器要为客户端套接字关联命令请求处理器。
- 为了向客户端返回命令执行结果,服务器要为客户端套接字关联命令回复处理器。
- 当主服务器和从服务器进行复制操作时,主从服务器都需要关联复制处理器。
在这些事件处理器中,服务器最常用的是与客户端进行通信的连接应答处理器、命令请求处理器和命令回复处理器。
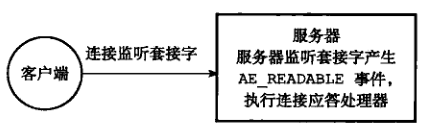
1)连接应答处理器
networking.c/acceptTcpHandle 函数是 Redis 的连接应答处理器,这个处理器用于对连接服务器监听套接字的客户端进行应答,具体实现为 sys/socket.h/accept 函数的包装。
当 Redis 服务器进行初始化的时候,程序会将这个连接应答处理器和服务器监听套接字的 AE_READABLE 事件关联。对应源码如下
# server.c/initServer.../* Create an event handler for accepting new connections in TCP and Unix * domain sockets. */for (j = 0; j < server.ipfd_count; j++) { if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE, acceptTcpHandler,NULL) == AE_ERR) { serverPanic( "Unrecoverable error creating server.ipfd file event."); }}... 当有客户端用 sys/scoket.h/connect 函数连接服务器监听套接字时,套接字就会产生 AE_READABLE 事件,引发连接应答处理器执行,并执行相应的套接字应答操作。如图 4 所示:
2)命令请求处理器
networking.c/readQueryFromClient 函数是 Redis 的命令请求处理器,这个处理器负责从套接字中读入客户端发送的命令请求内容,具体实现为 unistd.h/read 函数的包装。 当一个客户端通过连接应答处理器成功连接到服务器之后,服务器会将客户端套接字的 AE_READABLE 事件和命令请求处理器关联起来(networking.c/acceptCommonHandler 函数)。
当客户端向服务器发送命令请求的时候,套接字就会产生 AR_READABLE 事件,引发命令请求处理器执行,并执行相应的套接字读入操作,如图 5 所示:
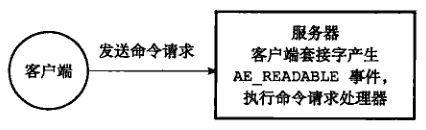
在客户端连接服务器的整个过程中,服务器都会一直为客户端套接字的 AE_READABLE 事件关联命令请求处理器。
3)命令回复处理器
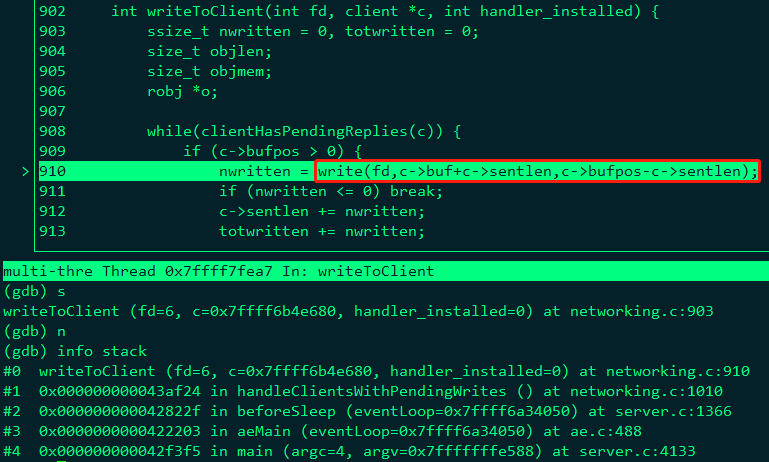
networking.c/sendReplToClient 函数是 Redis 的命令回复处理器,这个处理器负责将服务器执行命令后得到的命令回复通过套接字返回给客户端。 当服务器有命令回复需要发给客户端时,服务器会将客户端套接字的 AE_WRITABLE 事件和命令回复处理器关联(networking.c/handleClientsWithPendingWrites 函数)。
当客户端准备好接收服务器传回的命令回复时,就会产生 AE_WRITABLE 事件,引发命令回复处理器执行,并执行相应的套接字写入操作。如图 6 所示:
当命令回复发送完毕之后,服务器就会解除命令回复处理器与客户端套接字的 AE_WRITABLE 事件的关联。对应源码如下:
# networking.c/writeToClient...if (!clientHasPendingReplies(c)) { c->sentlen = 0; # buffer 缓冲区命令回复已发送,删除套接字和事件的关联 if (handler_installed) aeDeleteFileEvent(server.el,c->fd,AE_WRITABLE); /* Close connection after entire reply has been sent. */ if (c->flags & CLIENT_CLOSE_AFTER_REPLY) { freeClient(c); return C_ERR; }}... 1.5 客户端与服务器连接事件
之前我们通过 debug 的形式大致认识了客户端与服务器的连接过程。现在,我们站在文件事件的角度,再一次来追踪 Redis 客户端与服务器进行连接并发送命令的整个过程,看看在过程中会产生什么事件,这些事件又是如何被处理的。
先来看客户端与服务器建立连接的过程:
- 先启动我们的 Redis 服务器(127.0.0.1-8379)。成功启动后,服务器套接字(127.0.0.1-8379) AE_READABLE 事件正处于被监听状态,而该事件对应连接应答处理器。(
server.c/initServer())。 - 使用 redis-cli 连接服务器。这是,服务器套接字(127.0.0.1-8379)将产生 AR_READABLE 事件,触发连接应答处理器执行(
networking.c/acceptTcpHandler())。 - 对客户端的连接请求进行应答,创建客户端套接字,保存客户端状态信息,并将客户端套接字的 AE_READABLE 事件与命令请求处理器(
networking.c/acceptCommonHandler())进行关联,使得服务器可以接收该客户端发来的命令请求。
此时,客户端已成功与服务器建立连接了。上述过程,我们仍然可以用 gdb 调试,查看函数的执行过程。具体调试过程如下:
gdb ./src/redis-server(gdb) b acceptCommonHandler # 给 acceptCommonHandler 函数设置断点(gdb) r redis-conf --port 8379 # 启动服务器
另外开一个窗口,使用 redis-cli 连接服务器:redis-cli -p 8379
回到服务器窗口,我们会看到已进入 gdb 调试模式,输入:info stack,可以看到如图 6 所示的堆栈信息。

现在,我们再来认识命令的执行过程:
- 客户端向服务器发送一个命令请求,客户端套接字产生 AE_READABLE 事件,引发命令请求处理器(readQueryFromClient)执行,读取客户端的命令内容;
- 根据客户端发送命令内容,格式化客户端 argc、argv 等相关值属性值;
- 根据命令名称查找对应函数。
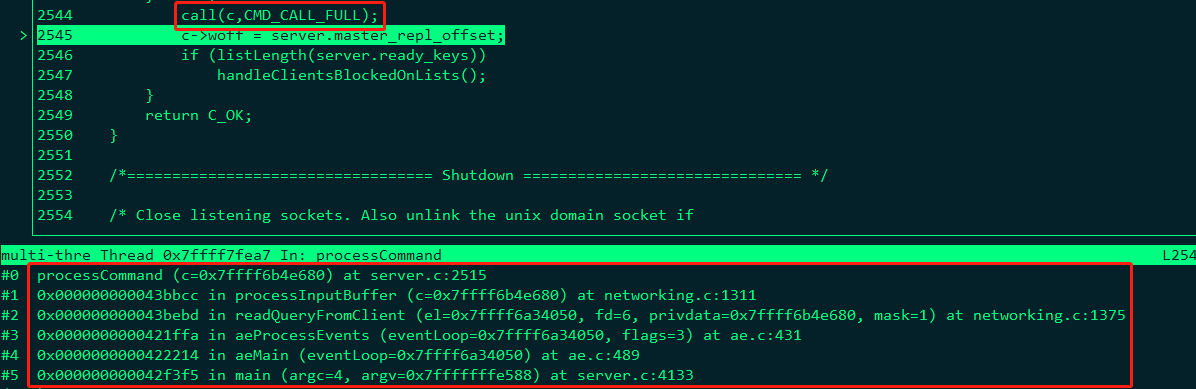
server.c/processCommad()中lookupCommand函数调用; - 执行与命令名关联的函数,获得返回结果,客户端套接字产生 。
server.c/processCommad()中call函数调用。 - 返回命令回复,删除客户端套接字与 AE_WRITABLE 事件的关联。
network.c/writeToClient()函数。
图 7 展示了命令执行过程的堆栈信息。图 8 则展示了命令回复过程的堆栈信息。
上一节我们一起认识了文件事件。接下来,让我们再来认识下时间事件。
2 时间事件
Redis 的时间时间分为以下两类:
- 定时时间:让一段程序在指定的时间之后执行一次。比如,让程序 M 在当前时间的 60 毫秒后执行一次。
- 周期性事件:让一段程序每隔指定时间就执行一次。比如,让程序 N 每隔 30 毫秒执行一次。
对于时间事件,数据结构源码(ae.h/aeTimeEvent):
/* Time event structure */typedef struct aeTimeEvent { long long id; /* time event identifier. */ long when_sec; /* seconds */ long when_ms; /* milliseconds */ aeTimeProc *timeProc; aeEventFinalizerProc *finalizerProc; void *clientData; struct aeTimeEvent *next;} aeTimeEvent; 主要属性说明:
- id:服务器为时间事件创建的全局唯一 ID。ID 号按从小到大的顺序递增。
- when_sec:秒精度的 UNIX 时间戳,记录了时间事件的到达时间。
- when_ms:毫秒精度的 UNIX 时间戳,记录了时间事件的到达时间。
- timeProc:时间事件处理器,对应一个函数。当时间事件发生时,服务器就会调用相应的处理器来处理事件。
时间事件进程执行的函数为 ae.c/processTimeEvents()。
此外,对于时间事件的类型区分,取决于时间事件处理器的返回值:
- 返回值是
ae.h/AE_NOMORE,为定时事件。该事件在到达一次后就会被删除; - 返回值不是
ae.h/AE_NOMORE,为周期事件。当一个周期时间事件到达后,服务器会根据事件处理器返回的值,对时间事件的 when_sec 和 when_ms 属性进行更新,让这个事件在一段时间之后再次到达,并以这种方式一致更新运行。比如,如果一个时间事件处理器返回 30,那么服务器应该对这个时间事件进行更新,让这个事件在 30 毫秒后再次执行。
2.1 时间事件之 serverCron 函数
持续运行的 Redis 服务器需要定期对自身的资源和状态进行检查和调整,从而确保服务可以长期、稳定的运行。这些定期操作由 server.c/serverCron() 函数负责执行。主要操作包括:
- 更新服务器的各类统计信息。比如时间、内存占用、数据库占用情况等。
- 清理数据库中的过期键值对。
- 关闭和清理连接失效的客户端。
- 尝试进行 AOF 或 RDB 持久化操作。
- 如果服务器是主服务器,对从 服务器进行定期同步。
- 如果处于集群模式,对集群进行定期同步和连接测试。
Redis 服务器以周期性事件的方式来运行 serverCron 函数,在服务器运行期间,每隔一段时间,serverCron 就会执行一次,直到服务器关闭为止。
关于执行次数,可参见 redis.conf 文件中的 hz 选项。默认为 10,表示每秒运行 10 次。
3 事件调度与执行
由于服务器同时存在文件事件和时间事件,所以服务器必须对这两种事件进行调度,来决定何时处理文件事件,何时处理时间事件,以及花多少时间来处理它们等等。
事件的调度和执行有 ae.c/aeProcessEvents() 函数负责。源码如下:
int aeProcessEvents(aeEventLoop *eventLoop, int flags){ int processed = 0, numevents; /* Nothing to do? return ASAP */ if (!(flags & AE_TIME_EVENTS) && !(flags & AE_FILE_EVENTS)) return 0; /* 首先判断是否存在需要监听的文件事件,如果存在需要监听的文件事件,那么通过IO多路复用程序获取 * 准备就绪的文件事件,至于IO多路复用程序是否等待以及等待多久的时间,依发生时间距离现在最近的时间事件确定; * 如果eventLoop->maxfd == -1表示没有需要监听的文件事件,但是时间事件肯定是存在的(serverCron()), * 如果此时没有设置 AE_DONT_WAIT 标志位,此时调用IO多路复用,其目的不是为了监听文件事件是否准备就绪, * 而是为了使线程休眠到发生时间距离现在最近的时间事件的发生时间(作用类似于unix中的sleep函数), * 这种休眠操作的目的是为了避免线程一直不停的遍历时间事件形成的无序链表,造成不必要的资源浪费 */ if (eventLoop->maxfd != -1 || ((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) { int j; aeTimeEvent *shortest = NULL; struct timeval tv, *tvp; /* 寻找发生时间距离现在最近的时间事件,该时间事件的发生时间与当前时间之差就是IO多路复用程序应该等待的时间 */ if (flags & AE_TIME_EVENTS && !(flags & AE_DONT_WAIT)) shortest = aeSearchNearestTimer(eventLoop); if (shortest) { long now_sec, now_ms; // 创建 timeval 结构 aeGetTime(&now_sec, &now_ms); tvp = &tv; /* How many milliseconds we need to wait for the next * time event to fire? */ long long ms = (shortest->when_sec - now_sec)*1000 + shortest->when_ms - now_ms; /* 如果时间之差大于0,说明时间事件到时时间未到,则等待对应的时间; * 如果时间间隔小于0,说明时间事件已经到时,此时如果没有 * 文件事件准备就绪,那么IO多路复用程序应该立即返回,以免 * 耽误处理时间事件*/ if (ms > 0) { tvp->tv_sec = ms/1000; tvp->tv_usec = (ms % 1000)*1000; } else { tvp->tv_sec = 0; tvp->tv_usec = 0; } } else { /* If we have to check for events but need to return * ASAP because of AE_DONT_WAIT we need to set the timeout * to zero */ if (flags & AE_DONT_WAIT) { tv.tv_sec = tv.tv_usec = 0; tvp = &tv; } else { /* Otherwise we can block */ tvp = NULL; /* wait forever */ } } // 阻塞并等等文件事件产生,最大阻塞事件由 timeval 结构决定 numevents = aeApiPoll(eventLoop, tvp); for (j = 0; j < numevents; j++) { // 处理所有已产生的文件事件 aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd]; int mask = eventLoop->fired[j].mask; int fd = eventLoop->fired[j].fd; int fired = 0; /* Number of events fired for current fd. */ int invert = fe->mask & AE_BARRIER; if (!invert && fe->mask & mask & AE_READABLE) { fe->rfileProc(eventLoop,fd,fe->clientData,mask); fired++; } /* Fire the writable event. */ if (fe->mask & mask & AE_WRITABLE) { if (!fired || fe->wfileProc != fe->rfileProc) { fe->wfileProc(eventLoop,fd,fe->clientData,mask); fired++; } } /* If we have to invert the call, fire the readable event now * after the writable one. */ if (invert && fe->mask & mask & AE_READABLE) { if (!fired || fe->wfileProc != fe->rfileProc) { fe->rfileProc(eventLoop,fd,fe->clientData,mask); fired++; } } processed++; } } /* Check time events */ if (flags & AE_TIME_EVENTS) // 处理所有已到达的时间事件 processed += processTimeEvents(eventLoop); return processed; /* return the number of processed file/time events */} 将 aeProcessEvents 函数置于一个循环里面,加上初始化和清理函数,就构成了 Redis 服务器的主函数 server.c/main()。以下是主函数的伪代码:
def main(): // 初始化服务器 init_server(); // 一直处理事件,直到服务器关闭为止 while server_is_not_shutdown(): aeProcessEvents(); // 服务器关闭,执行清理操作 clear_server()
从事件处理的角度来看,Redis 服务器的运行流程可以用流程图 1 来概括:
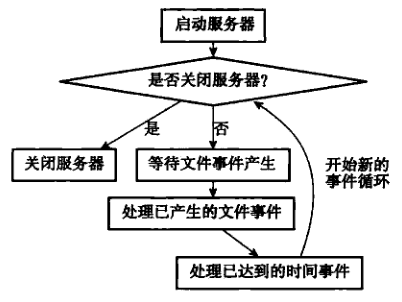
以下是事件的调度和执行规则:
- aeApiPoll 函数的最大阻塞事件由到达时间最接近当前时间的时间事件决定。这个方法既可以避免服务器对时间事件进行频繁的轮询,也可以确保 aeApiPoll 函数不会阻塞过长时间。
- 因为文件事件是随机出现的,如果等待并处理完一次文件事件之后,仍未有任何时间事件到达,那么服务器将再次等待并处理文件事件。随着文件事件的不断执行,时间会逐渐向时间事件所设置的到达时间逼近,并最终来到,这时服务器就可以开始处理到达的时间事件了。
- 对文件事件和时间事件的处理都是同步、有序、原子地执行。服务器不会中途中断事件处理,也不会对事件进行抢占。因此,不管是文件事件的处理器,还是时间事件的处理器,它们斗殴尽可能的减少程序的阻塞事件,并在有需要时主动让出执行权,从而降低事件饥饿的可能性。举个栗子,在命令回复处理器将一个命令回复写入到客户端套接字时,如果写入字节数超过了一个预设常量,命令回复处理器就会主动用 break 跳出写入循环,将余下的数据留到下次再写。另外,时间事件也会将非常耗时的持久化操作放到子线程或者子进程中执行。
- 因为时间事件在文件事件之后执行,并且事件之间不会出现抢占,所以时间事件的实际处理时间,通常会比时间事件设定的时间稍晚一些。
总结
- Redis 服务器是一个事件驱动程序,服务器处理的事件分为时间事件和文件事件两类。
- 文件事件是对套接字操作的抽象。**每次套接字变得可应答(acceptable)、可写(writable)或者可读(readable)时,相应的文件事件就会产生。
- 文件事件分为 AE_READABLE 事件(读事件)和 AE_WRITABLE 事件(写事件)两类。
- 时间事件分为定时事件和周期事件。定时事件只在指定时间执行一次,而周期事件则每隔指定时间执行一次。
- 服务器一般情况下只执行 serverCron 函数这一个周期性时间事件。
- 时间事件和文件事件之间是合作关系。服务器会轮流处理这两种事件,并且处理事件的过程中不会进行抢占。
