本文共 5053 字,大约阅读时间需要 16 分钟。
mysql 高可用性
没有放之四海而皆准的方案,具体使用哪种高可用性解决方案依赖于以下几点:
1.可用性需求级别
2.部署的应用的种类
3.你的环境所接受的最佳实践
mysql的高可用性可以归结为三个范畴:
1.数据冗余 --99.9%
2.集群&虚拟系统 --99.99%
3.无共享的,物理备份集群 --99.999%
3个范畴成本递增,可靠性也递增
Table 16.1 Feature Comparison of MySQL HA Solutions
Requirement
MySQL Replication
MySQL Cluster
Availability
Platform Support
All Supported by MySQL Server (http://www.mysql.com/support/supportedplatforms/database.html)
All Supported by MySQL Cluster (http://www.mysql.com/support/supportedplatforms/cluster.html)
Automated IP Failover
No
Depends on Connector and Configuration
Automated Database Failover
No
Yes
Automatic Data Resynchronization
No
Yes
Typical Failover Time
User / Script Dependent
1 Second and Less
Synchronous Replication
No, Asynchronous and Semisynchronous
Yes
Shared Storage
No, Distributed
No, Distributed
Geographic redundancy support
Yes
Yes, via MySQL Replication
Update Schema On-Line
No
Yes
Scalability
Number of Nodes
One Master, Multiple Slaves
255
Built-in Load Balancing
Reads, via MySQL Replication
Yes, Reads and Writes
Supports Read-Intensive Workloads
Yes
Yes
Supports Write-Intensive Workloads
Yes, via Application-Level Sharding
Yes, via Auto-Sharding
Scale On-Line (add nodes, repartition, etc.)
No
Yes
使用zfs复制
1.通过zfs命令可以创建传输回滚快照。通过不断的创建传输回滚,可以实现类似drdb的同步机制
2.重用命令有zfs snapshot,zfs list, zfs send, zfs recv, zfs restore, zfs set readonly=on
3.zfs send scratchpool@snap1 |ssh id@host pfexec zfs recv -F slavepool 命令创建快照并将快照结果作为pipe的输入,输出到另一台机器并在令一台机器执行recv操作恢复快照。这样就实现了同步功能
4.使用脚本决定你的同步时间,failover时间
使用memcached
Figure 16.2 memcached Architecture Overview
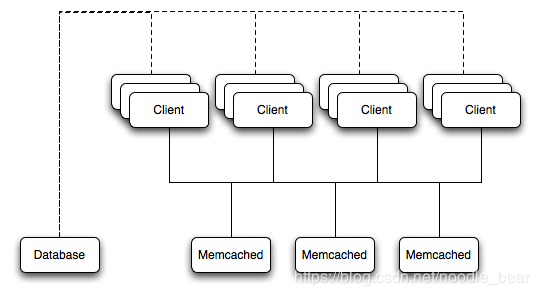
Figure 16.3 memcached Hash Selection
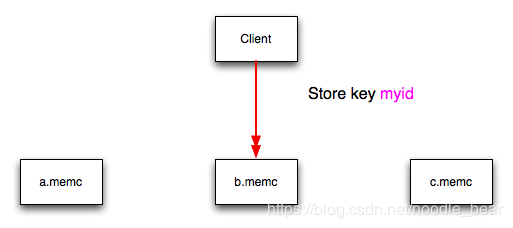
Figure 16.4 memcached Hash Selection with New memcached instance
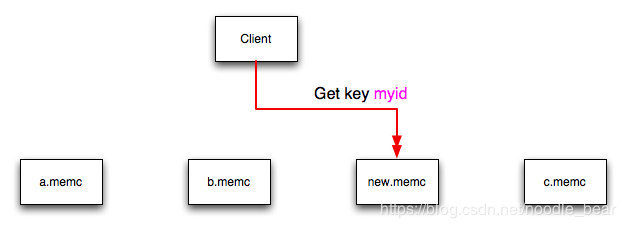
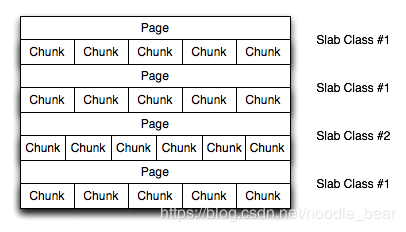
Figure 16.5 Memory Allocation in memcached
memcached线程优化:
0.编译时打开thread implementation
1.封装了线程处理函数,这个封装提供了基础保护,保护相同的全局变量不需要再次更新,即子线程继承了父线程中的全局变量
2.每个线程使用自己的libevent实例
3.单线程监听tcp端口,rr算法派遣到处理线程,之后此连接的都由该处理线程处理,即实现了连接和线程的绑定,防止线程切换影响性能
4.对于udp,所有线程采用抢占方式,没有抢到的线程ignore掉该请求
5.7版本新增:
1. 增加了一个线程池来减小开销增加性能
2. 线程池解决了每个连接一个线程模型的几个问题:
在高并发模型下,太多线程堆栈导致cpu缓存的是最没有用的数据,线程池保证线程栈适用于最小cpu缓存记步
太多的并发线程导致线程上下文切换开销高,也会给操作系统作业调度带来挑战,线程池在mysql内部级别控制活动的线程总数,对mysql运行的host也更加恰当
并发数太多增大线程间的资源传输,在innodb这种线程太多增大获取mutex的时间,线程池控制了并发环境下同时开始传输的线程数
3. 线程池只在mysql企业版才有,社区版是没有的
4. 需要内核版本2.6.9及以上
线程池的实现:
1. 一个库文件包含了线程池的核心和INFORMATION_SCHEMA 数据库中的几个表
2. INFORMATION_SCHEMA 中的表命名为TP_THREAD_STATE, TP_THREAD_GROUP_STATE, 以及TP_THREAD_GROUP_STATS,这些表提供线程池所有的操作
3. 和线程池相关的有一些系统变量,线程处理器变量在成功加载线城池插件时动态加载,其他线城池插件相关变量只有主动enable后才生效的有:
thread_pool_algorithm: 当前线程调度算法
thread_pool_high_priority_connection: 优先级,涉及如何调度会话执行
thread_pool_prio_kickup_timer: 线程池把一个低优先级任务移动到高优先级队列的等待时间
thread_pool_max_unused_threads: 允许的最大睡眠线程的个数
thread_pool_size: 线程池中线程的数量,这是线程池性能的最重要参数
thread_pool_stall_limit: 线程被认为已经stalled的时间
线程池安装:
插件库文件需要放置在mysql plugin目录下(该目录由名为plugin_dir的系统变量指定),如果有需要可以在服务器启动时添加这个环境变量
数据库插件名为thread _pool(linux e.g. thread_pool.so)
在启动数据库服务时加参数--plugin-load使能,也可以加入配置文件:
[mysqld] plugin-load=thread_pool.so
等效于:
[mysqld] plugin-load=thread_pool=thread_pool.so;tp_thread_state=thread_pool.so;tp_thread_group_state=thread_pool.so;tp_thread_group_stats=thread_pool.so
为了更详细还可以:
[mysqld] plugin-load-add=thread_pool=thread_pool.so plugin-load-add=tp_thread_state=thread_pool.so plugin-load-add=tp_thread_group_state=thread_pool.so plugin-load-add=tp_thread_group_stats=thread_pool.so
如果需要可以只加载插件而不包含表:
[mysqld] plugin-load=thread_pool=thread_pool.so
检查安装成功:
mysql> SELECT PLUGIN_NAME, PLUGIN_STATUS FROM INFORMATION_SCHEMA.PLUGINS -> WHERE PLUGIN_NAME LIKE 'thread%' OR PLUGIN_NAME LIKE 'tp%'; +-----------------------+---------------+ | PLUGIN_NAME | PLUGIN_STATUS | +-----------------------+---------------+ | thread_pool | ACTIVE | | TP_THREAD_STATE | ACTIVE | | TP_THREAD_GROUP_STATE | ACTIVE | | TP_THREAD_GROUP_STATS | ACTIVE | +-----------------------+---------------+
如果这些插件状态都是active,那么thread_pool已经生效了
线程池操作:
1. 线程池包含多个线程组,每个线程组管理一组客户端连接。每当连接建立时,线程池把他们按照rr算法分配给线程组
2. 一个组的最大线程数是4K(有些系统上是4095,那个1被内部使用了)
3. 线程池分离开线程和连接,因此线程和连接之间不再有固定联系。这个和默认的线程处理模型不通,默认的线程处理模型在连接建立时为每个连接分配一个线程,两者一一对应
4. 线程池尽力去保证同一时间一个组里只有一个线程在运行,但是有时临时的允许多个线程同时运行以便达到最大性能。它工作算法按照一下的行为模式:
每个组有一个监听线程监听从分配给这个组的连接发来的声明。当声明到达,线程组或者立即执行或者将其排队:
如果当前声明是唯一声明且没有其他排队的声明且没有正在运行的声明则立即执行
只要不能呢个立即执行就将其排队
如果立即执行发生,则执行被监听线程执行(这以为着此时组里没有线程在监听)。如果该声明执行的快,执行线程转为监听线程。否则,线程池认为该执行已经稳定了并且启动另一个线程进行监听。为了保证没有线程因长期执行的声明足赛,线程池有一个后台线程监测线程组的状态
通过使用监听线程执行,声明可以立即执行,因此如果执行动作很快结束,没有必要创建额外线程。这就保证了最少的并发线程最高效执行任务
当线程池插件启动时,它为没有个组创建一个监听线程,插入后台线程。额外线程按需创建
thread_pool_stall_limit系统变量界定了“很快结束”的含义。默认时间是60ms,最大可以设置为6s。这个参数可配置以保证你在服务器负载上获得一个平衡。这个值越短线程启动的越快,并且对解决死锁问题更好。这个值越长对需要长时间运行的、负载比较大的声明越好,这样做避免一个声明在执行时有太多的新声明与它竞争
线程池聚焦于限制运行时间短的声明的并发。这声明执行达到stall time前,它阻止其他声明与其竞争。如果执行时间超过了stall time,它允许继续启动其他声明。这样,线程池尽力保证每个线程组不会超过一个短时间运行的声明,尽管长时间执行的有很多。设计者不希望让长时间运行的声明阻止其他声明的执行,因为长时间执行的执行时间是不可预知的。例如在复制的主节点上,有一个发送binarylog event的线程会一直跑
一个声明遇到I/O操作或用户级别的锁(row lock或table lock)时变为阻塞态。这种阻塞可能引发线程池不可用,所以线程池提供了一个回调,执行线程通过回调通知线程池可以立即启动一个新线程处理其他声明了。当阻塞线程返回时,线程池允许它立即重新执行
线程池包含两个队列,一个高优先级队列和一个低优先级队列。传输过程的第一个声明进到低优先级队列。任何接下来的声明进入高优先级。通过thread_pool_high_priority_connection系统变量可以设置为所有声明都进入高优先级队列
转载地址:https://blog.csdn.net/weixin_32141627/article/details/115846538 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
