本文共 3125 字,大约阅读时间需要 10 分钟。
前言
在开发途中,我们经常听到ASCII,UTF8,unicode,ISO-8859-1(别名LATIN1)及其它一些编码方式。搞懂他们的关系,可能又有新的发现。
ASCII码
每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说:一个字节一共可以用来表示256种不同的状态。
上个世纪60年代,美国制定了一套字符编码,英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码.具体关系请查看《》
128位ASCII码设计之初是给印机用的,其字符主要分为二类
- 控制字符:又名非打印字符, ASCII 表上的数字 0–31 分配给了控制字符,用于控制像打印机等一些外围设备。例如,12 代表换页/新页功能。此命令指示打印机跳到下一页的开头。
- 打印字符:数字 32–126 分配给了能在键盘上找到的字符,当您查看或打印文档时就会出现。注:十进制32代表空格 ,十进制数字 127 代表 DELETE 命令。
LATIN1
又名ISO-8859-1。英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。因此有些地区将其扩展为256位,latin1就是其中一种。其0x00-0xFF格式:
- 0x00-0x7F:完成向下兼ASCIl
- 0x80-0x9F:自定义的控制字符(非)
- 0xA0-0xFF:自定义的打印字符
Unicode
世界上存在着多种编码方式(如 Latin1),同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码.
如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是Unicode,这是一种所有符号的编码。Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号.《》,其0-127位也是ASCIl。
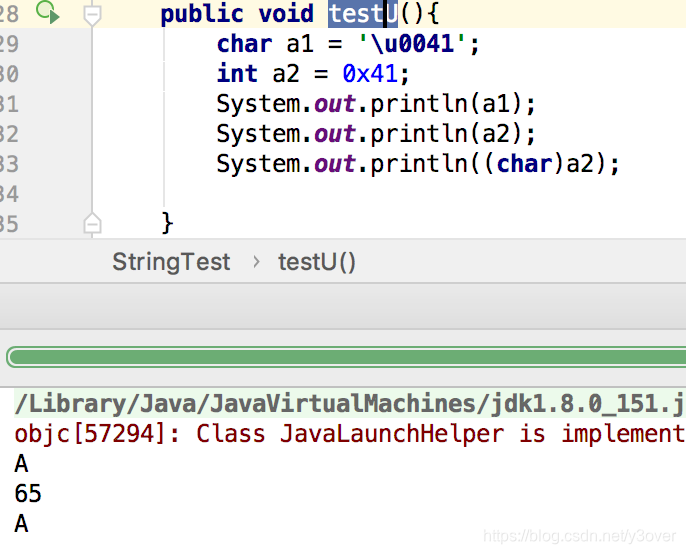
Unicode编码的字符表示以“\u”开头 综合上述2点得出,\u0041 = (char)0x41
UTF-8
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储.
比如,汉字"严"的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
如果按上述方式存储会存在问题
- 第一个问题是,如何才能区别Unicode和ASCII?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?
- 第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
UTF-8就是在互联网上使用最广的一种Unicode的实现方式。UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。其编码规则很简单,只有二条:
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
- 对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制) --------------------±-------------------------------------------- 0000 0000-0000 007F | 0xxxxxxx 0000 0080-0000 07FF | 110xxxxx 10xxxxxx 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
下面,还是以汉字"严"为例,演示如何实现UTF-8编码。
- 已知"严"的unicode是4E25(100111000100101)
- 根据上表,可以发现4E25处在第三行的范围内(0000 0800-0000 FFFF)
- 因此"严"的UTF-8编码需要三个字节,即格式是"1110xxxx 10xxxxxx 10xxxxxx"。
- 然后,从"严"的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。
- 这样就得到了,“严"的UTF-8编码是"11100100 10111000 10100101”
- 转换成十六进制就是E4B8A5。
UTF-16
utf-16是字符编码表的另一种实现方式。其以16位无符号整数为单位(表示最少占用2字节)。但是,中文有近 8 万个字符,而 1 个 16 位长的码元最大值仅是 65535(0xffff),所以超过一半的不常用中文字符被定义为扩展字符,这些字符需要用 2 个 16 位长的码元表示。
- 对于统一编码U < 0x10000的字符,utf-16直接表示。
- 对于统一编码>= 0x10000,我们先计算 U’ = U – 0x10000,然后将 U’ 写成二进制形式:yyyy yyyy yyxx xxxx xxxx,U 的 UTF-16 编码(二进制)就是:【110110yyyyyyyyyy,110111xxxxxxxxxx】。
ps: 为什么 U’ 可以被写成 20 个二进制位?Unicode 的最大码位是 0x10FFFF,减去 0x10000 后,U’ 的最大值是0xFFFFF.也就是20位。
所以用2个字节表示还多出32-20=12位。也就是【110110,110111】 为什么选用110110,110111?
Unicode 编码的设计者将0xD800-0xDFFF保留下来,并称为代理区(Surrogate):
| D800-DBFF | High Surrogates | 高位替代 |
|---|---|---|
| DC00-DFFF | Low Surrogates | 低位替代 |
只要字符属于这两区域,就说明这字符是不完整的,要2字符表示。
高位替代就是指这个范围的码位是两个WORD的UTF-16编码的第一个WORD。
低位替代就是指这个范围的码位是两个WORD的UTF-16编码的第二个WORD。
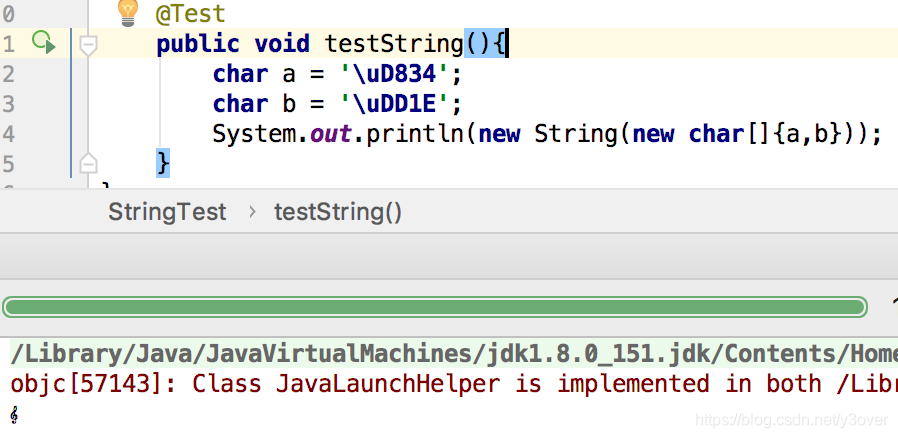
下面,还是以字符"𝄞"为例,演示如何实现UTF-16编码。
- 已知"𝄞"的unicode是0001D11E
- 0001D11E > 10000, 算出 u’ = D11E
- D11E的二进制是:110100 0100011110
- 这样就得 “𝄞"的UTF-16编码是"11011000001101001101110100011110”
- 转换成十六进制就是d834dd1e。
ps: jdk中的char就是用utf-16进制表示的
UTF-32
utf-16是字符编码表的另一种实现方式.其以32位无符号整数为单位.因为其对每个字符都使用4字节,就空间而言,是非常没有效率的。超过2字节的字符非常罕见,使得UTF-32通常会是其它编码的二到四倍。
总结
作为Unicode的存储方式UTF-8是否可以替换为《》的方式做为实现。
主要参考
《》
《》 《》转载地址:https://blog.csdn.net/y3over/article/details/112546972 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
