
1.正则表达式使用的特殊符号和字符
1.0 最常见的符号和字符,如下图:


这里,反义指的是反义词的意思。如 \w匹配任何数字或者字母, \W 匹配非字母且非数字的字符
1.1 用"|" 匹配多个正则表达式模式
"|"即管道符号,表示或的操作,意思是选择被管道符号分隔开的多个表达式中的一个。"或"操作有时也被叫做“联合”,或者“逻辑或”。下面是例子:

1.2 匹配任意一个单个的字符 "."
"." 匹配除换行符外的任意一个单个字符,无论字母、数字,还是除换行符以外的空白符("\t" "\r"等)、可打印字符、不可打印字符等等,都可匹配。若要匹配 . 本身,则需加一个反斜杠转义。

1.3 从字符串的开头、结尾、单词边界开始匹配 ("^" "$" "\b" "\B")
"^"或者"\A"从字符串开始匹配;"$" 或者"\Z" 从字符串结尾开始匹配。若要匹配这两个字符本身,也需要用转义 "\"
"\b" 匹配的模式是单词边界,意思是它匹配的正则模式一定在单词(单词可理解为"\w"所能匹配的字符集合)的开头,无论这个单词在一行的起始处还是在字符串中间。"\B"只匹配出现在单词中间的模式(即不在单词的边界)

1.4 方括号"[]"用来匹配某个特定的单字符。使用方括号的正则表达式匹配方括号里的任意一个字符:
对仅有单个字符的正则表达式,方括号和或操作等价,比如我们想匹配"a"、"b"中的一个;但是若我们想匹配"ab"和"cd"中的一个时,则不能选择[abcd],只能选"ab|cd"
另外,方括号除匹配单个字符外,还支持"-"连接的字符范围,如[A-Z]代表所有大写字母,[a-z]代表小写字母,[0-9]代表十进制数字。若左方块括号之后的第一个字符是"^",则表示不匹配方括号里的任何字符。
1.5 使用闭包操作符实现重复匹配
"*"号匹配它左边的正则表达式出现0次或0次以上的情况,"+"号匹配它左边的正则式出现1次或更多次的情况,而"?"号匹配它左边的正则式出现0次或1次的情况。对于花括号"{}",花括号里若是单个值,如"{N}",则表示匹配出现N次的情况;若是逗号隔开的一对值,如"{M, N}",则表示匹配出现M次到N次的情况。同样,反斜线转义后则匹配符号本身。

2. 正则表达式和python语言
2.1 re模块的核心函数和方法
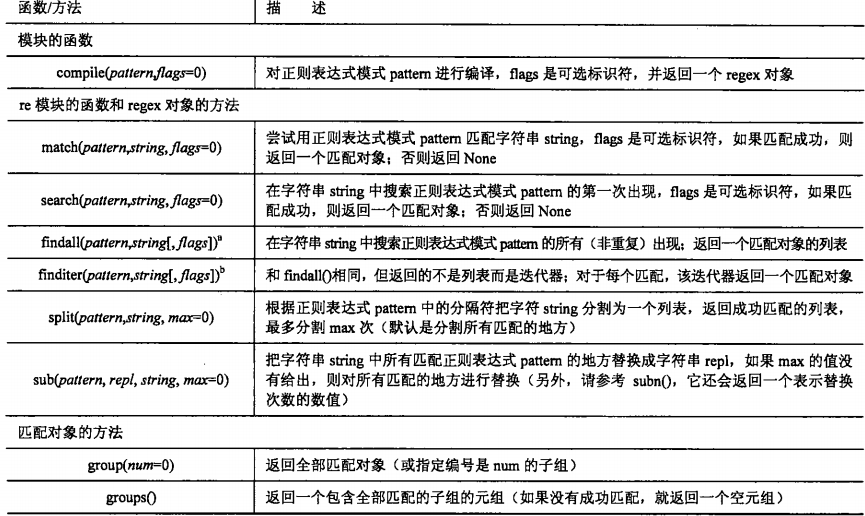
2.2 用 match() 匹配字符串
match() 函数试图从字符串的开始对字符串进行匹配,匹配成功的话返回一个匹配对象,否则返回None。匹配对象的 group() 方法可以用来显示成功的匹配。
当模式匹配成功时调用匹配对象的 group() 方法会显示成功的匹配

当模式匹配失败时,返回None,此时调用 group() 方法会报错:
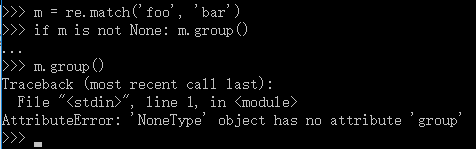
if 语句就是为了防止出现 AttributeError 的情形
另外,即使字符串比正则模式长,也可能匹配成功,只要模式是从字符串的开头开始匹配的:
>>> m = re.match('foo', 'food on the table')>>> m.group()'foo' 也可以省略中间过程,直接返回结果:
>>> re.match('foo', 'food on the table').group()'foo' 当匹配不成功时,同样会引发 AttributeError
2.3 用 search() 搜索字符串
search() 与march() 工作方式一样,不同之处在于 search() 会搜索(从左至右搜索)字符串中模式首次出现的位置,如果搜索到则匹配成功,返回匹配对象,否则返回None。参看下面的例子。
>>> m = re.match('foo', 'seafood')>>> if m is not None: m.group()... >>> >>> # 无返回结果,说明匹配不成功。但 'foo' 确实在 'seafood'中,此时就是search() 的用处>>> m = re.search('foo', 'seafood') # 使用search()>>> if m is not None: m.group()...'foo' 2.4 运用特殊字符和符号的正则表达式使用案例
2.4.1 匹配多个字符串(|)

2.4.2 匹配任意单个字符
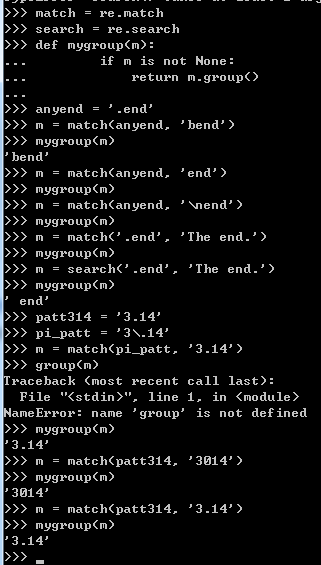
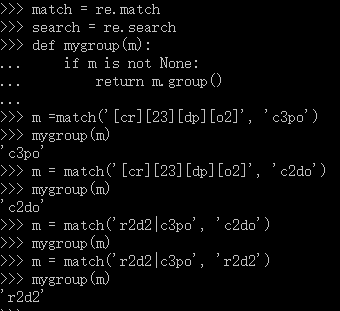
2.4.3 创建字符集合 []
下面的例子进一步说明 "|"和"[]"的区别
2.4.4 group() 和groups()
通过例子来理解 group() 和groups()

如上例,group() 通常用来显示所有匹配,也可用来获取个别匹配的子组。groups()方法则可以获得一个包含所有匹配的子组的元组。下面通过子组的排列组合,更透彻的理解二者。


2.4.5 匹配字符串开头、结尾或单词边界
^ $ \b 主要用于search()而不是match(),因为match()总是从字符串开头匹配

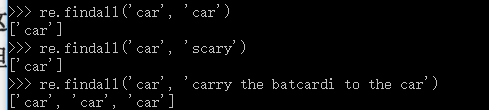
2.4.6 findall()
findall()匹配方式类似于search(),不同之处在于前者总是返回一个列表,若没有找到匹配部分返回空列表,找到匹配部分则返回所有匹配部分的列表,从左到右的顺序排列。
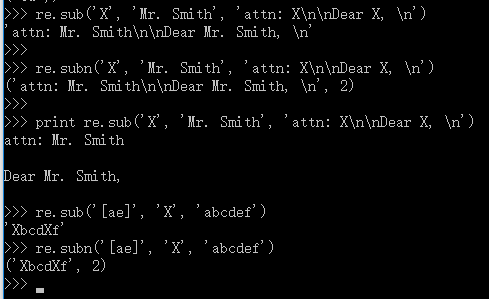
2.4.7 subn()和sub()
sub()和sub()都用于搜索替换,将某字符串中匹配正则表达式模式的部分进行替换,用来替换的部分通常是一个字符串,或者是一个返回字符串的函数。subn()还返回一个表示替换次数的数字,替换后的字符串和表示替换次数的数字作为一个元组的元素返回
2.4.8 split()
re模块的split()方法类似字符串的split()方法,前者根据正则表达式模式分割字符串,后者根据固定的字符串分割,故前者更灵活。另外,还可以设置一个参数来限制分割的次数。
若分隔符没有使用由特殊符号组成的正则表达式匹配,那么re.split()和string.split()执行过程是一样的

3. 正则表达式示例
A. 生成用于正则表达式练习的数据
#!/usr/bin/env pythonfrom random import randint, choicefrom string import lowercasefrom sys import maxintfrom time import ctimef = open(r"E:\code\Core Python Programming\15\data.txt", 'w')doms = ('com', 'edu', 'net', 'org', 'gov')datas = []for i in range(randint(5, 10)): dtint = randint(0, maxint-1) dtstr = ctime(dtint) shorter = randint(4, 7) em = '' for j in range(shorter): em += choice(lowercase) longer = randint(shorter, 12) dn = '' for j in range(longer): dn += choice(lowercase) eachline = '%s::%s@%s.%s::%d-%d-%d' % (dtstr, em, dn, choice(doms), dtint, shorter, longer) datas.append(eachline) print eachline f.writelines(eachline+'\n')f.close()data = datas[randint(0, len(datas)-1)] B.匹配、提取时间戳中有关星期的数据。用正则表达式"^Mon|^Tue|^Wed|^Thu|^Fri|^Sat|^Sun",或者只用一个 ^符号,将星期字符串归为一组:"^(Mon|Tue|Wed|Thu|Fri|Sat|Sun) "

这里也可以发现,未分组时 gropu(1) 会报错
C. 限制更松的情况:匹配以三个数字或者字母组成的字符为开头的字符串:"^\w{3}" 或者 "^(\w{3})",后者是分组的情况

如上,当把匹配模式的{3}写在括号里面时,表示匹配三个连续的、由字母或数字组成的字符,再把这三个字符视为一个组。但如果把{3}挪到括号外面时,含义就变成三个连续的、单个数字或字母的字符。
D. 通过匹配末尾的三个整型来加深理解match() 和 search(),这里用search()明显更方便。用match则需注意贪婪模式。

如上,在使用 search()搜索时没有问题,在匹配时,即使考虑到分组、考虑到要匹配整行数据,取得的结果仍是不正确,原因就在于正则表达式默认是贪婪模式。贪婪/贪心模式是指,正则表达式中含通配字符时,在从左到右的取值时,会尽量抓取满足匹配的最长字符串。解决办法是用非贪婪操作符 "?",问号放在?、*、+后面,表示要求正则表达式匹配的字符越少越好。

用搜索 search()可以只获取中间的那个整型部分:

