本文共 3921 字,大约阅读时间需要 13 分钟。
概述
一直以为 会写SQL, 是最实在的基础,会写SQL了,才会优化SQL,会优化SQL,才知道怎么设计表结构,进而设计更加精妙的业务类型, 业务类型就大致知道IO的大致规律。 从而知道更加复杂的架构模型。好了废话不多说,下面介绍下测试的几个小实验,主要关于SQL改写后效率的一些提升,大家在做sql改写时可以考虑下,基于业务考虑。。。
SQL 改写--with 子句
1、基础环境
drop table t_with; CREATE TABLE T_WITH AS SELECT ROWNUM ID, A.* FROM DBA_SOURCE A WHERE ROWNUM < 100001; SET autotrace traceonly SET linesize 1000
2、语句1
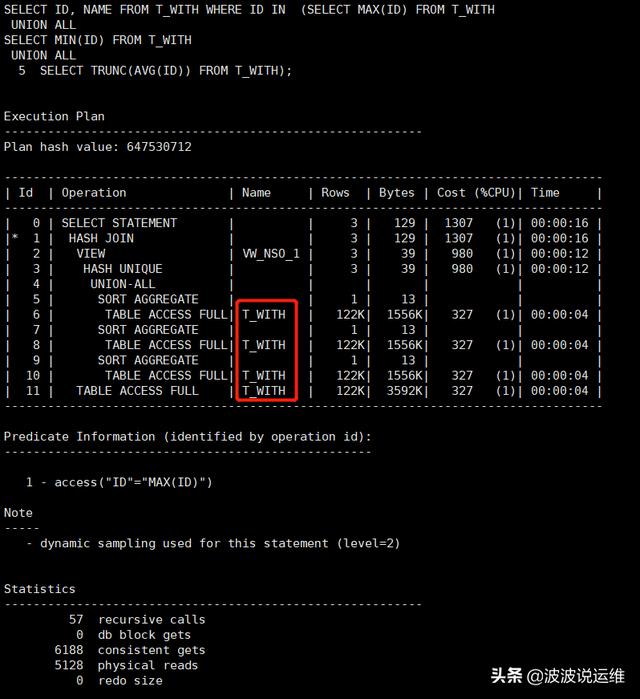
SELECT ID, NAME FROM T_WITH WHERE ID IN (SELECT MAX(ID) FROM T_WITH UNION ALL SELECT MIN(ID) FROM T_WITH UNION ALL SELECT TRUNC(AVG(ID)) FROM T_WITH);
3、语句2
WITH AGG AS (SELECT MAX(ID) MAX, MIN(ID) MIN, TRUNC(AVG(ID)) AVG FROM T_WITH) SELECT ID, NAME FROM T_WITH WHERE ID IN ( SELECT MAX FROM AGG UNION ALL SELECT MIN FROM AGG UNION ALL SELECT AVG FROM AGG);
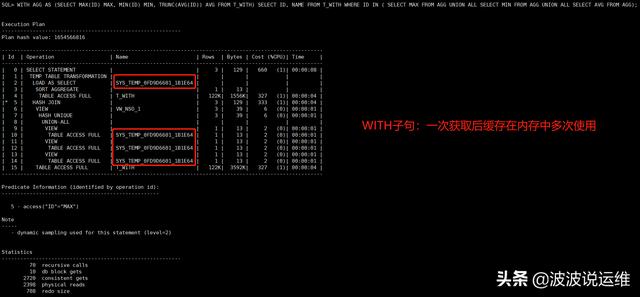
说明:用with改写后一张表不用去重复全扫。
SQL改写--insert all
1、环境准备:
drop table t1 purge; create table t1 as select * from dba_objects where 1=2; create table t2 as select * from dba_objects where 1=2; drop table t purge; create table t as select * from dba_objects;
2、普通的插入语句:
insert into t1 select * from t;insert into t2 select * from t;
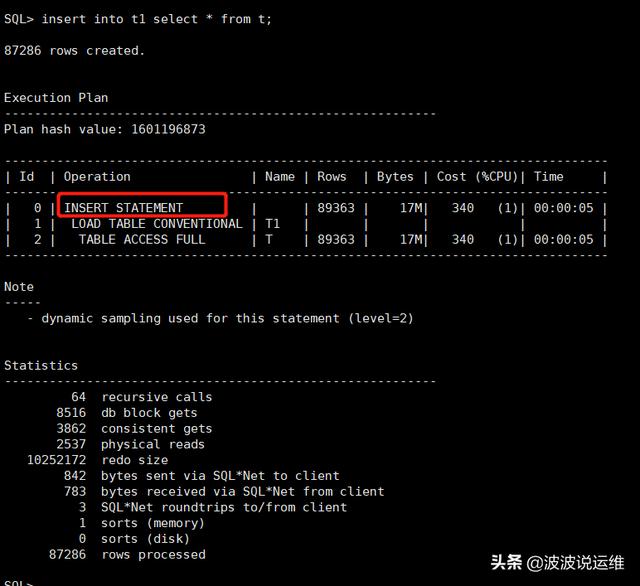
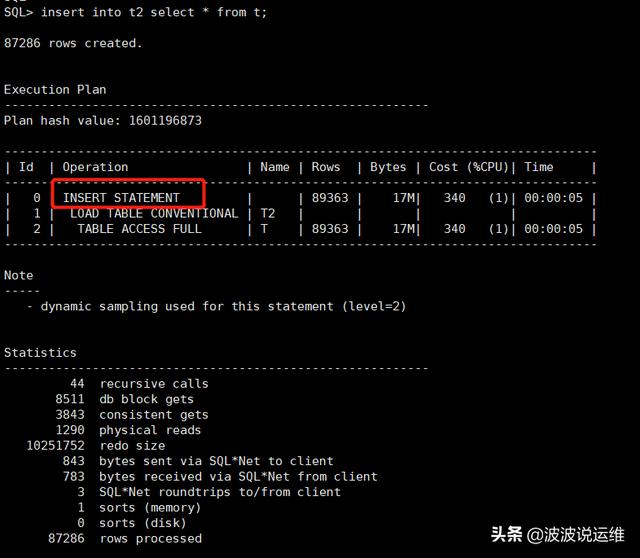
3、改写后
set linesize 1000 set pagesize 2000 set autotrace off ALTER SESSION SET statistics_level = all; rollback; insert all into t1 into t2 select * from t; SELECT * FROM table(dbms_xplan.display_cursor(null,null,'allstats last'));
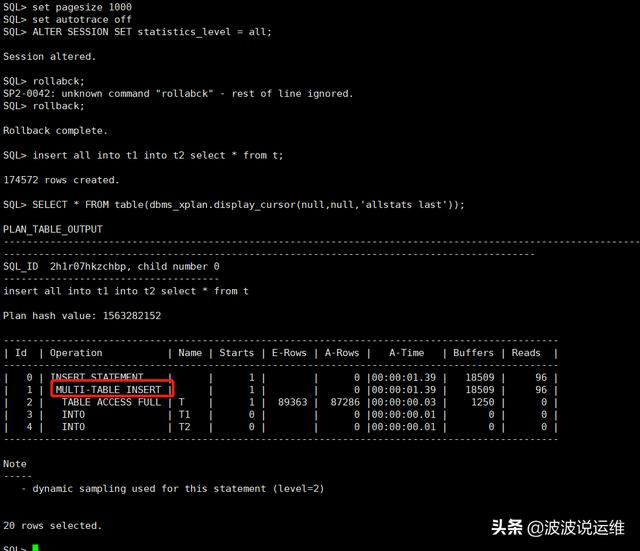
说明: MULTI-TABLE INSERT:从性能上来看, insert all 不-定会有优势,但是当分开写和合并写不等价的时候,分开 写要很麻烦,比如锁表,比如中间表,这样性能就要比 insert all 差多了!
SQL改写--rownum分页
1、环境准备:
drop table t; create table t as select * from dba_objects; set linesize 1000 set pagesize 2000 set autotrace off
2、语句1:
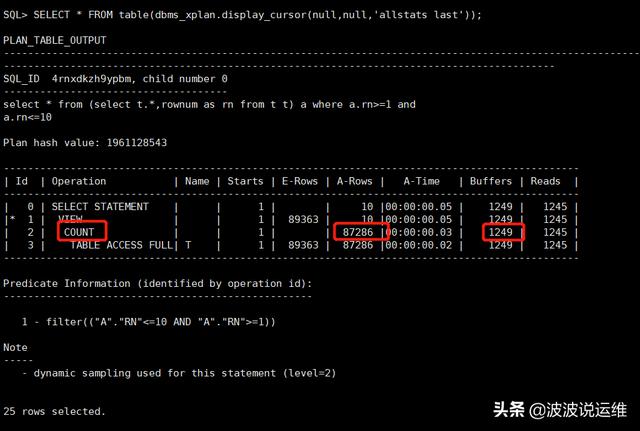
select * from (select t.*,rownum as rn from t t) a where a.rn>=1 and a.rn<=10; SELECT * FROM table(dbms_xplan.display_cursor(null,null,'allstats last'));
3、语句2:
select * from (select t.*,rownum as rn from t t where rownum<=10) a where a.rn>=1 ; SELECT * FROM table(dbms_xplan.display_cursor(null,null,'allstats last'));
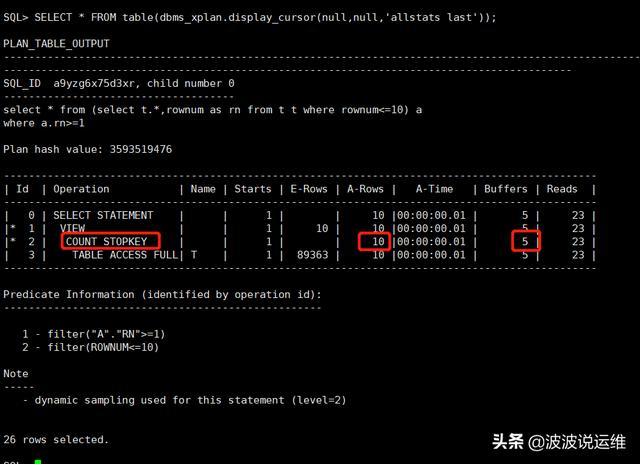
说明:语句 1 和语句 2 在写法上是等价的 。 但是语句 2 走的是 COUNT STOPKEY ,可以看到语句 2 的执行计划中的 A-ROWS 部分明显减少了很多。
SQL改写--rowid 的影响
1、环境准备:
drop table t purge; create table t as select * from dba_objects; update t set object_id=rownum; commit; create index idx_object_id on t(object_id); set autotrace off select rowid from t where object_id=8;
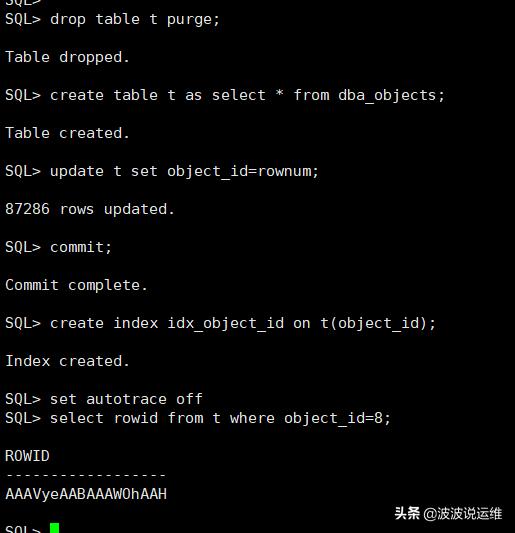
2、语句1:
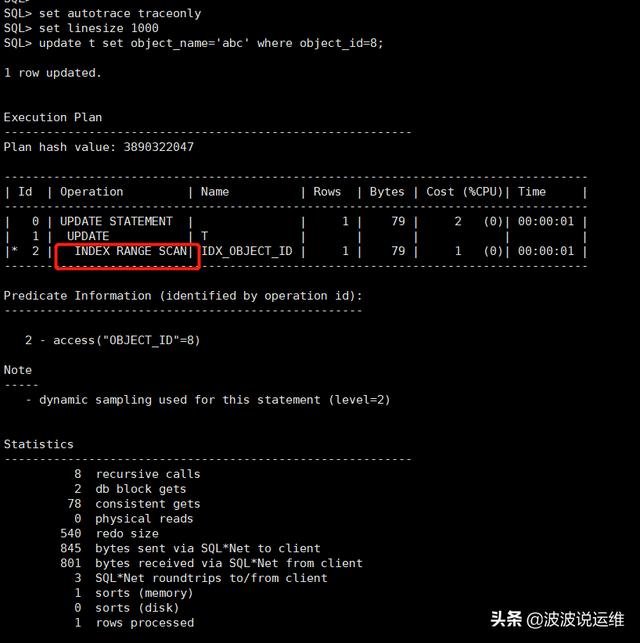
set autotrace traceonlyset linesize 1000update t set object_name='abc' where object_id=8;
3、语句2:
update t set object_name='abc' where object_id=8 and t.rowid='AAAVyeAABAAAWOhAAH';
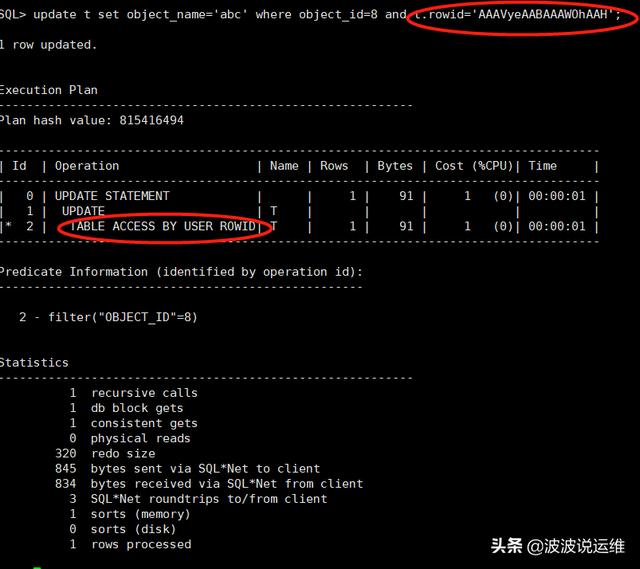
说明: 语句 1 和语句 2 在某些业务场景下,显然是等价的 。 但是语句 2 走的是 TABLE ACCESS BY USER ROWID,而语句1走的是 INDEX RANGE SCAN。 请注意这个 TABLE ACCESS BY USER ROWID 扫描方式,其直接根据 rowid 来 访问,是最快的访问方式!
SQL改写--分区条件有无
1、环境准备:
set autotrace offdrop table list_part_tab purge; --注意,此分区为列表分区 create table list_part_tab (id number,deal_date date,area_code number,nbr number,building varchar2(4000)) partition by list (area_code) ( partition p_591 values (591), partition p_592 values (592), partition p_593 values (593), partition p_594 values (594), partition p_595 values (595), partition p_596 values (596), partition p_597 values (597), partition p_598 values (598), partition p_599 values (599), partition p_other values (DEFAULT) ) ;--以下是插入一整年日期随机数和表示XX地区号含义(591到599)的随机数记录,共有10万条,如下: insert into list_part_tab (id,deal_date,area_code,nbr,building) select rownum, to_date( to_char(sysdate-365,'J')+TRUNC(DBMS_RANDOM.VALUE(0,365)),'J'),ceil(dbms_random.value(590,599)), ceil(dbms_random.value(18900000001,18999999999)), rpad('*',400,'*') from dual connect by rownum <= 100000; commit; update list_part_tab set building='广州' where area_code=591 and rownum=1; commit; 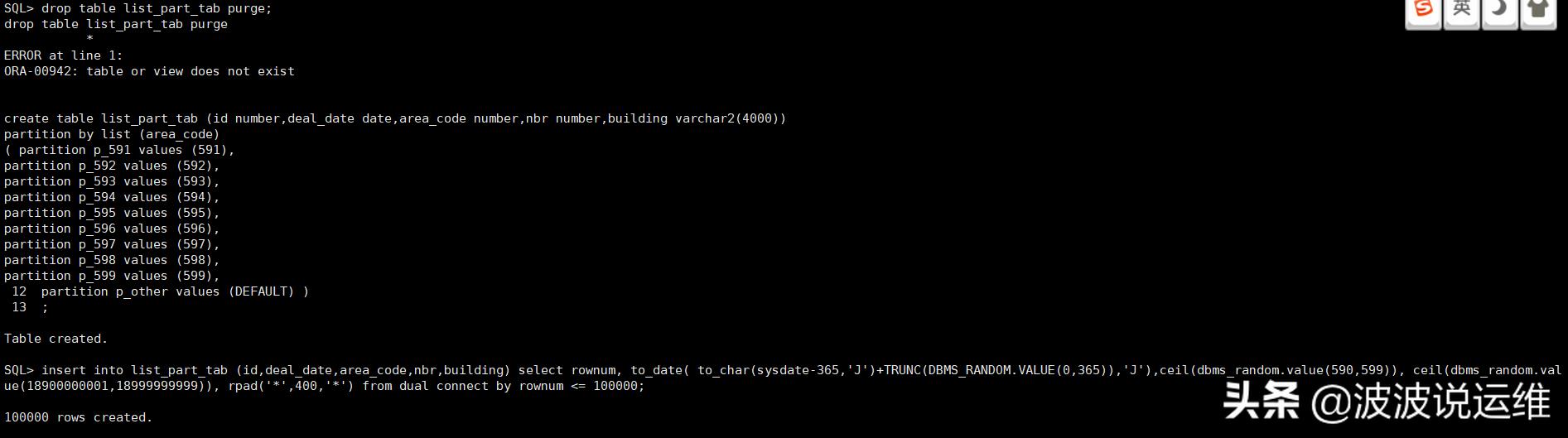
2、语句1:
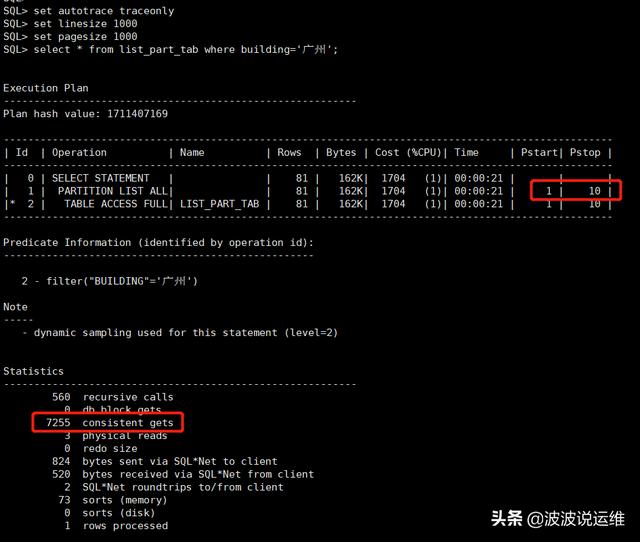
set autotrace traceonlyset linesize 1000set pagesize 1000select * from list_part_tab where building='广州';
3、语句2:
select * from list_part_tab where building='广州' and area_code=591;
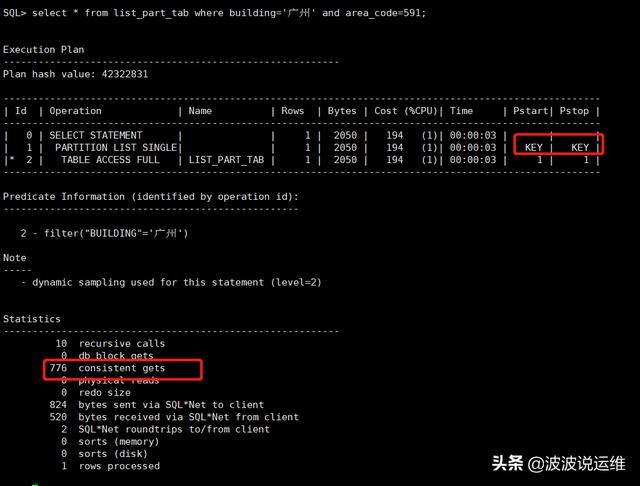
说明:两个语句的执行计划似乎没有差别,但是经过仔细查看我们发现,语句1 的 执行计划中 Pstart 为1 而 Pstop 为 10,说明从第 1 个分区边历到第 10 个分区。 而 第 2 个语句的执行计划 中 Pstart 和 Pstop 对应的是 KEY,说明它们落在了指定的 分区中。 执行计划的不同性能也不言自明,逻辑读前者是7255,后者是776。
这个实验还是花了一定时间去做的,其中两个测试有点问题,例如result_cache方面,后面再单独做介绍吧,有问题的就不写了~
后面会分享更多关于 DBA方面内容,感兴趣的朋友可以关注下!

转载地址:https://blog.csdn.net/weixin_39767645/article/details/110906143 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
