数据结构与算法——堆
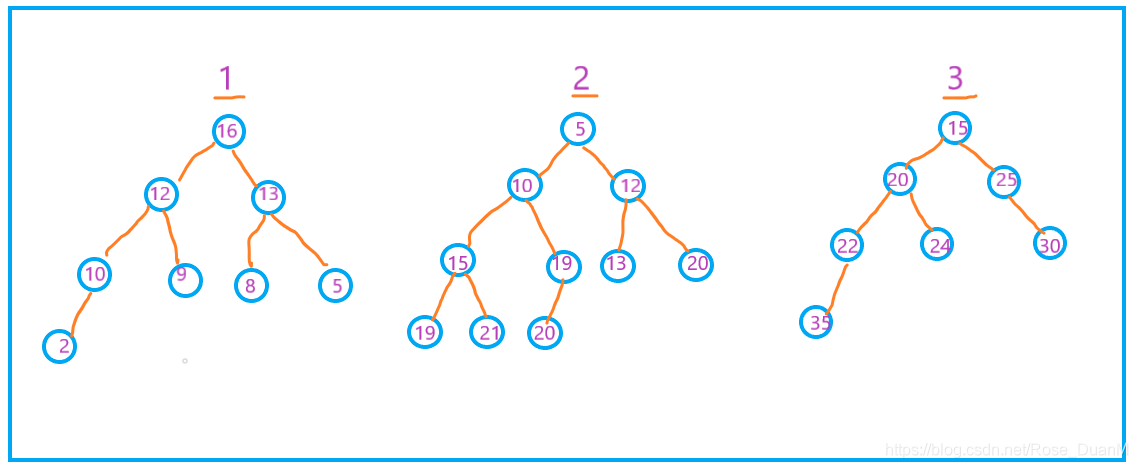 其中,1 是大顶堆,2 是小顶堆,3 不是堆。
其中,1 是大顶堆,2 是小顶堆,3 不是堆。 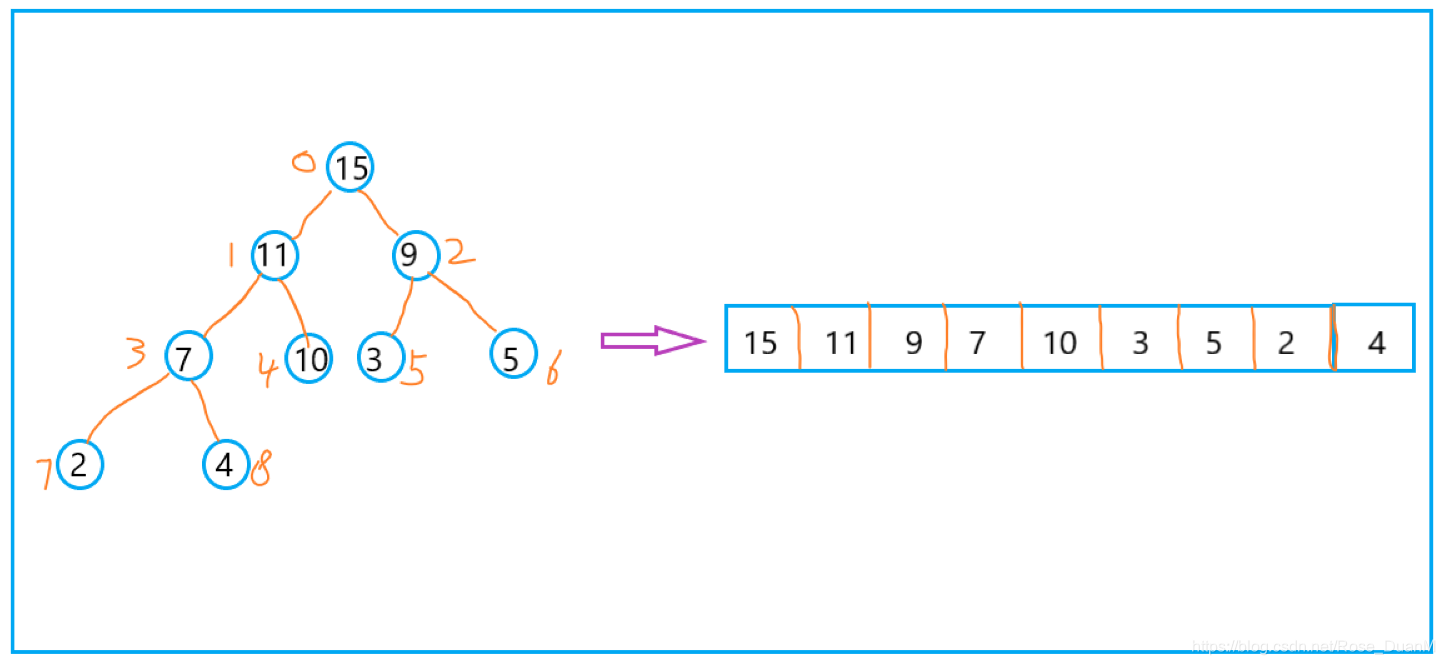 其中,对于任意位置上的节点 i ,其左子节点是 2 * i + 1,右子节点是 2 * i + 2,父节点是 (i - 1) / 2。
其中,对于任意位置上的节点 i ,其左子节点是 2 * i + 1,右子节点是 2 * i + 2,父节点是 (i - 1) / 2。 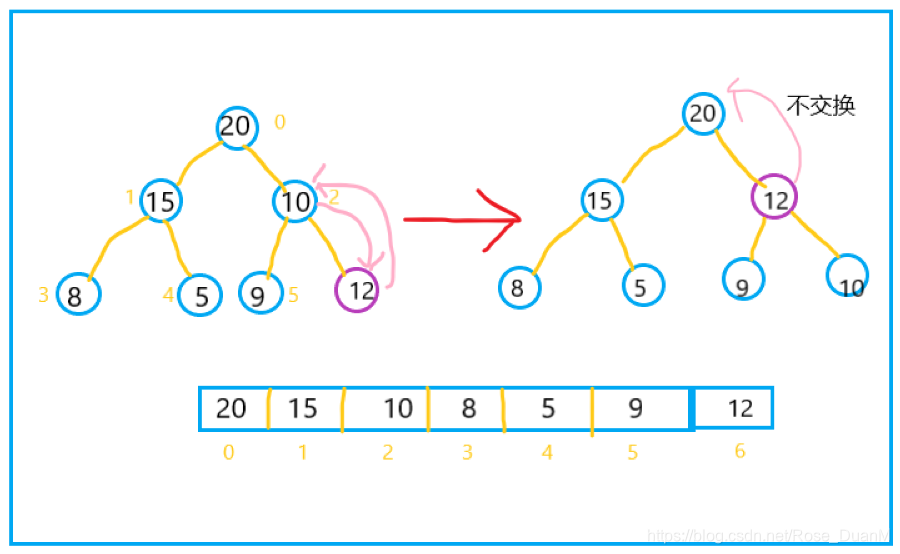 交换操作的代码,我也放到这里:
交换操作的代码,我也放到这里: 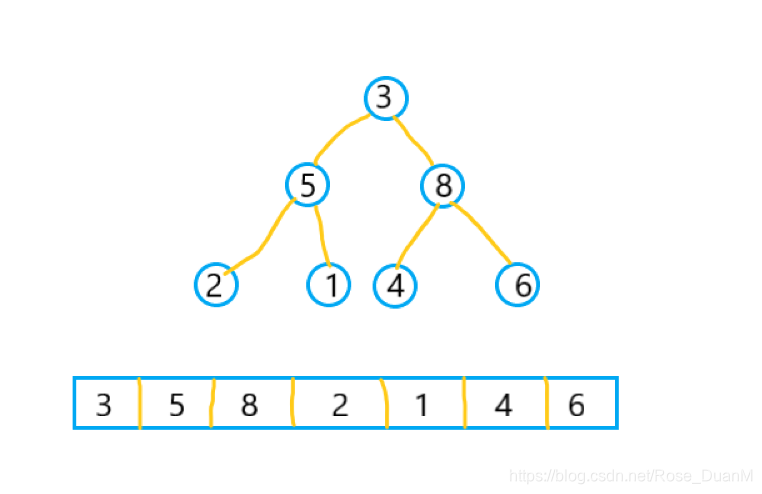 可以看到第一个非叶子节点是 8,所以我们从 8 开始从上往下堆化,然后依次是 5 - 3,堆化后的效果就是这样的:
可以看到第一个非叶子节点是 8,所以我们从 8 开始从上往下堆化,然后依次是 5 - 3,堆化后的效果就是这样的: 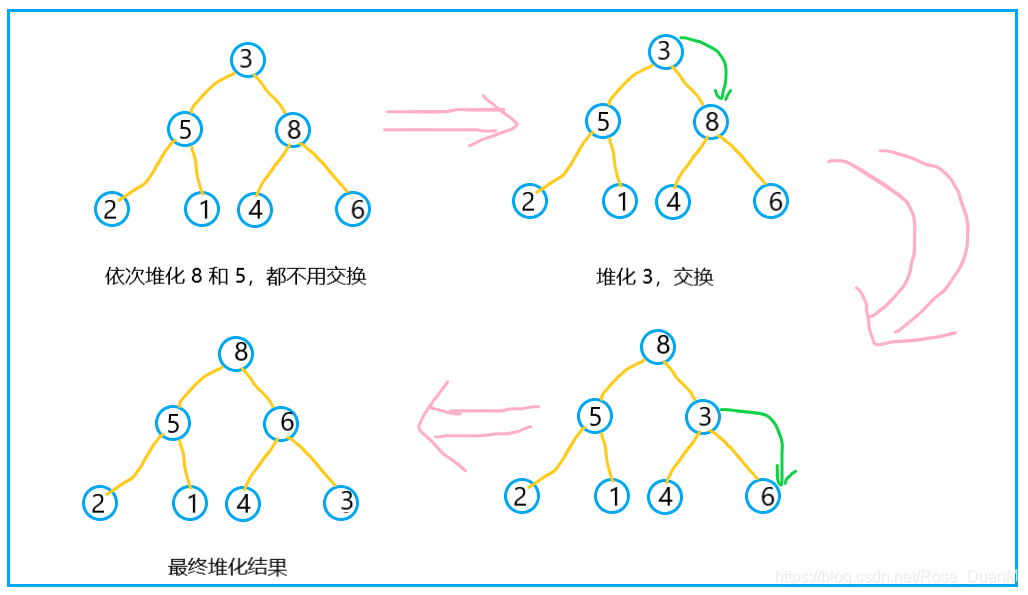 这样,我们就将一个无序的数组堆化成了具有堆的性质的数据,还需要说明以下,如果确定一个堆的第一个非叶子节点是多少呢?实际上,对于长度为 length 的数组,(length - 2) / 2下标对应的数据,就是堆中的第一个非叶子节点。接下来的操作就是排序了。
这样,我们就将一个无序的数组堆化成了具有堆的性质的数据,还需要说明以下,如果确定一个堆的第一个非叶子节点是多少呢?实际上,对于长度为 length 的数组,(length - 2) / 2下标对应的数据,就是堆中的第一个非叶子节点。接下来的操作就是排序了。 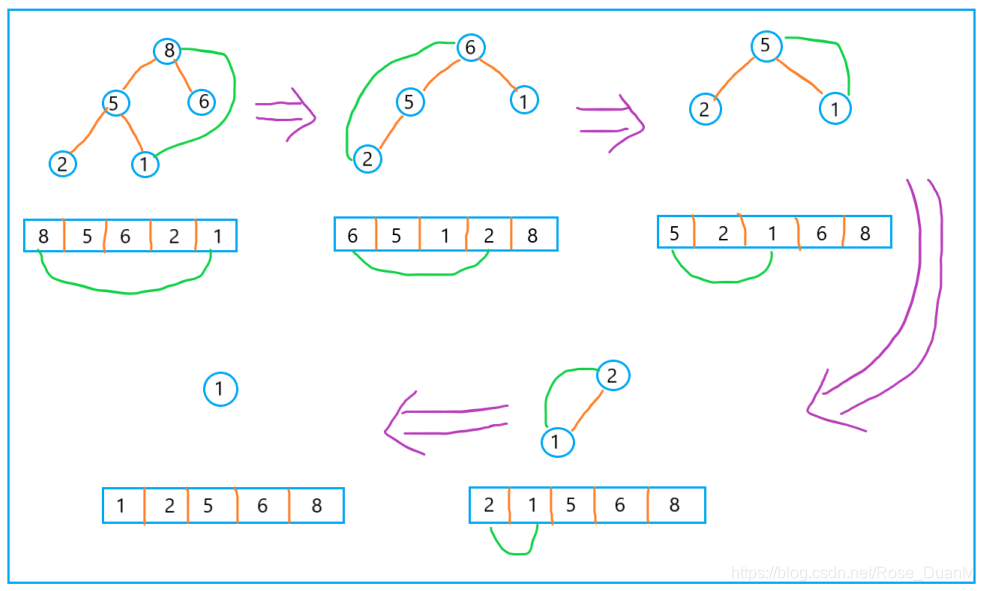 整个建堆和排序的实现的代码也贴在这里:
整个建堆和排序的实现的代码也贴在这里:
发布日期:2021-06-23 04:28:52
浏览次数:4
分类:技术文章
本文共 3106 字,大约阅读时间需要 10 分钟。
1. 什么是堆
堆(Heap),其实是一种特殊的二叉树,主要满足了二叉树的两个条件:’
- 堆是一种完全二叉树,还记得完全二叉树的定义吗?叶节点都在最底下两层,最后一层的节点都靠左排列,并且除了最后一层,其他层的节点个数都要达到最大,这种树叫做完全二叉树。
- 堆中的每个节点的值都必须大于等于(或者小于等于)其左右子节点的值。2. 堆中的每个节点的值都必须大于等于(或者小于等于)其左右子节点的值。
对于堆中的每个节点都大于等于其左右子节点的值,叫做大顶堆,反之,则叫做小顶堆。看看下面的图就能懂了。
其中,1 是大顶堆,2 是小顶堆,3 不是堆。 2. 堆是如何存储的?
其实,堆可以按照完全二叉树的存储方式来储存,因为完全二叉树是比较省空间的,所以我们可以直接用数组来存储,然后按照数组下标来取出堆中数据。参照下图,来看看堆的存储:
其中,对于任意位置上的节点 i ,其左子节点是 2 * i + 1,右子节点是 2 * i + 2,父节点是 (i - 1) / 2。 3. 堆的几种操作
明白了堆是怎样储存的,我们在来看看堆最常见的两个操作:往堆中插入元素和删除堆顶元素。
首先,如果要往堆中插入一个元素,我们先将其插入到数组中最后一个位置,然后与其父节点的值进行比较,如果大于父节点,则交换位置,继续比较。看看下面的图你就明白了:
交换操作的代码,我也放到这里: public class Heap { private int[] data;//存储堆数据的数组 private int n;//堆中可存储的元素容量 private int size;//堆中存储的元素个数 public Heap(int capacity) { this.data = new int[capacity]; this.n = capacity; this.size = 0; } //往堆中插入数据 public void insert(int value){ if (size >= n) return;//堆满了 data[size] = value; int i = size; while ((i - 1) / 2 >= 0 && data[i] > data[(i - 1) / 2]){ //交换data[i] 极其父节点 data[(i - 1) / 2] 的值 swap(data, i, (i - 1) / 2); i = (i - 1) / 2; } size ++; } //交换数组两个位置的元素 private void swap(int[] data, int i, int j){ int temp = data[i]; data[i] = data[j]; data[j] = temp; }} 接下来看看第二种操作:删除堆顶元素。
根据堆的定义,堆顶元素其实就是堆的最大或最小元素。所以删除堆顶元素,我们只需要移除数组中的第 0 个元素,然后再进行堆化,让堆继续保持顺序。那该怎么进行堆化呢?
首先我们直接将堆中的最后一个元素移到堆顶,然后与其左右子节点的值进行比较,找到较大的那么子节点,交换位置,然后继续比较,你可以结合代码来理解一下:
//删除数据,如果是大顶堆,则删除的是堆中的最大元素 //如果是小顶堆,则删除的堆中的最小元素 public int removeMax(){ if (size == 0) return -1;//堆为空 //将数组中的最后一个元素,放到第一个位置 int result = data[0]; data[0] = data[size - 1]; data[-- this.size] = 0; //进行堆化 heapify(data, size, 0); return result; } //堆化函数 private void heapify(int[] data, int size, int i){ while (true){ int max = i; if ((2 * i + 1) < size && data[i] < data[2 * i + 1]) max = 2 * i + 1; if ((2 * i + 2) < size && data[max] < data[2 * i + 2]) max = 2 * i + 2; if (max == i) break; swap(data, i, max); i = max; } } 4. 堆排序
现在来看看里用堆这种数据结构是怎么实现排序功能的。堆排序的时间复杂度非常的稳定,是O(nlogn),并且是原地排序算法,具体是怎么实现的呢?我们一般把堆排序分为两个步骤:建堆和排序。
建堆
对于一个未排序的数组,例如 data[3,5,8,2,1,4,6],其原始的结构是这样的: 可以看到第一个非叶子节点是 8,所以我们从 8 开始从上往下堆化,然后依次是 5 - 3,堆化后的效果就是这样的: 这样,我们就将一个无序的数组堆化成了具有堆的性质的数据,还需要说明以下,如果确定一个堆的第一个非叶子节点是多少呢?实际上,对于长度为 length 的数组,(length - 2) / 2下标对应的数据,就是堆中的第一个非叶子节点。接下来的操作就是排序了。 排序
排序的过程类似于上面说到的删除堆顶元素,因为堆顶元素是堆的最大或最小元素,以大顶堆为例,我们只需要将堆顶元素和数组中最后一个元素交换位置,然后重新构造堆,继续交换堆顶元素和数组中最后一个未排序数据,知道堆中元素剩下最后一个。示意图如下:
整个建堆和排序的实现的代码也贴在这里: //堆排序 public void heapSort(int[] data){ int length = data.length; if (length <= 1) return; //建堆 buildHeap(data); while (length > 0){ swap(data, 0, --length); heapify(data, length, 0); } } //建堆 //从非叶子节点依次堆化 private void buildHeap(int[] data){ int length = data.length; for (int i = (length - 2) / 2; i >= 0; -- i) { heapify(data, length, i); } } 转载地址:https://blog.csdn.net/Rose_DuanM/article/details/88204235 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
第一次来,支持一个
[***.219.124.196]2024年04月09日 15时59分20秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
lua table排序
2019-04-27
Unity发布的ios包在iphone上声音是从听筒里出来的问题
2019-04-27
UIScrollView复用节点示例
2019-04-27
Unity 5 AudioMixer
2019-04-27
Unity 代码混淆: CodeGuard的使用
2019-04-27
UGUI 列表循环使用
2019-04-27
使用命令行运行unity并执行某个静态函数(运用于命令行打包和批量打包)
2019-04-27
web.py框架
2019-04-27
web.py学习笔记
2019-04-27
python的代码缩进
2019-04-27
A* Pathfinding Project (Unity A*寻路插件) 使用教程
2019-04-27
bash学习笔记
2019-04-27
sqlite学习
2019-04-27
手把手教你实现Unity与Android的交互
2019-04-27
手把手教你使用Unity的Behavior Designer
2019-04-27
Unity3D摄像机裁剪——NGUI篇
2019-04-27
lua深拷贝一个table
2019-04-27
app运行提示Unable to Initialize Unity Engine
2019-04-27
spring boot 与 Ant Design of Vue 实现修改按钮(十七)
2019-04-27
spring boot 与 Ant Design of Vue 实现删除按钮(十八)
2019-04-27
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 308007729 位访客
访问时间: 2024-04-26 08:18:32
访问IP: 3.145.178.157
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版