本文共 5529 字,大约阅读时间需要 18 分钟。

“按需求动态生成测试环境”最开始是我们QA团队提出的需求,一开始接到这个需求的时候,第一反应就是,怎么会有这么迫(bian)切(tai)的想法呢?
这里还得介绍一下我们的分支管理策略:
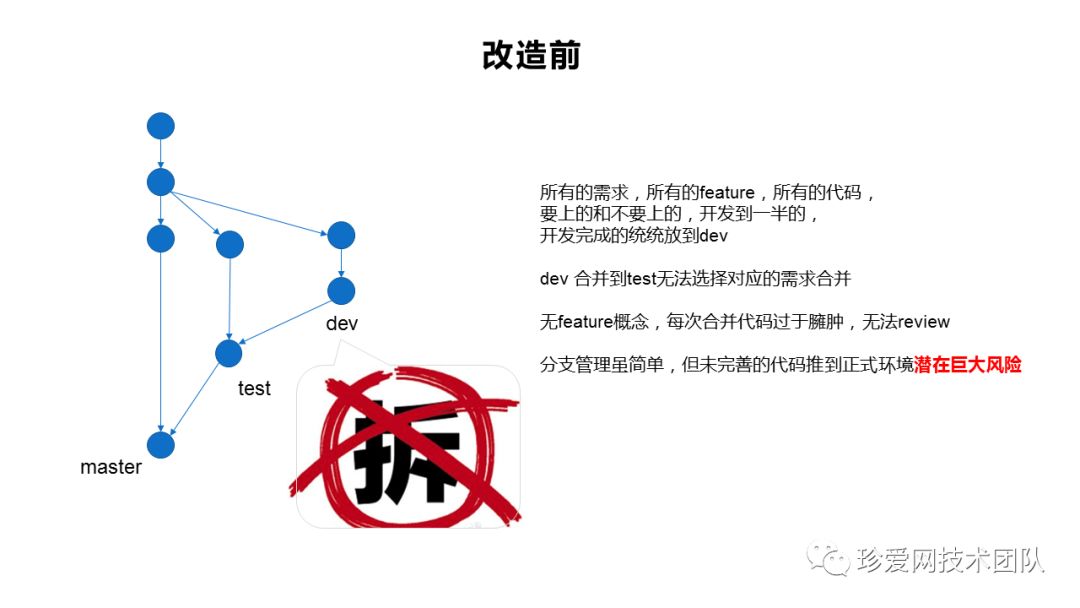
通过走访调研,最终确定遵循一个需求一个开发分支的原则,方便管理且可追溯 ,并行开发,互不干扰。
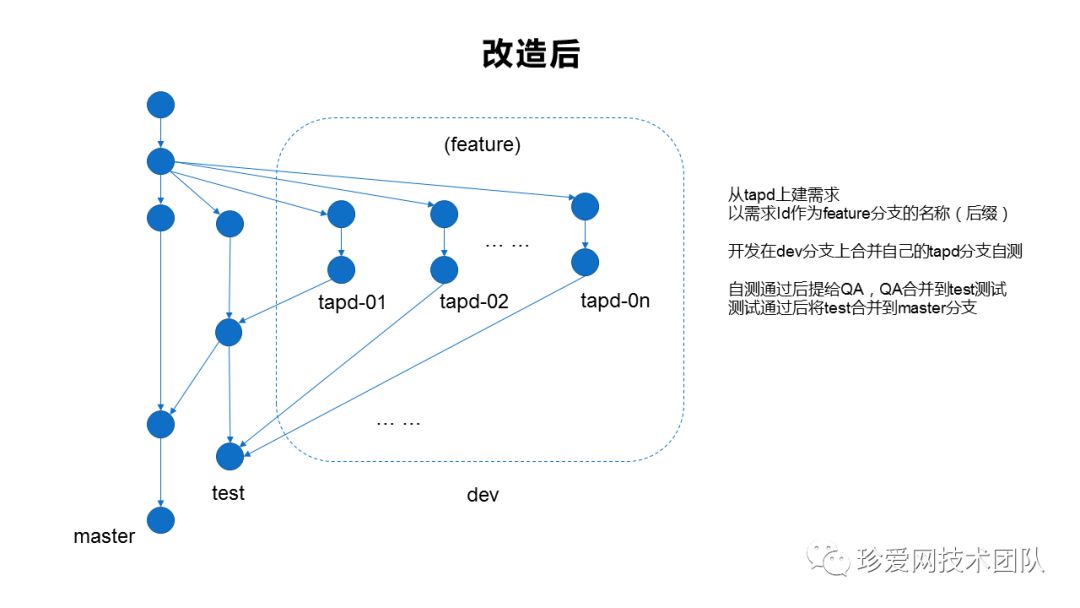
既然研发小哥哥的代码分支都是面向需求的,那测试小姐姐希望测试环境也能面向需求,就不过分了,一点都不过分!真心的!
接到这个需求后,最先想到的实现方式是使用docker、jenkins、gitlab等,给每一个需求都构建一个完整的全量项目的环境!
这是最简单的方式,但也是最不可行的方式!
一个迭代有十几个甚至几十个需求,每个需求一个全量的环境,那服务器资源就得翻好几十倍了,构建时间也无法接受。

作为一名苦逼的运维仔,
为了混口饭吃,再难也得顶着上!
落地方案往下看!
设计原理:
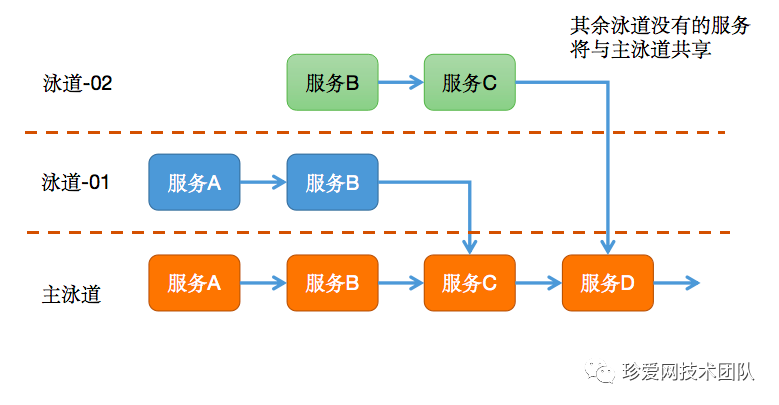
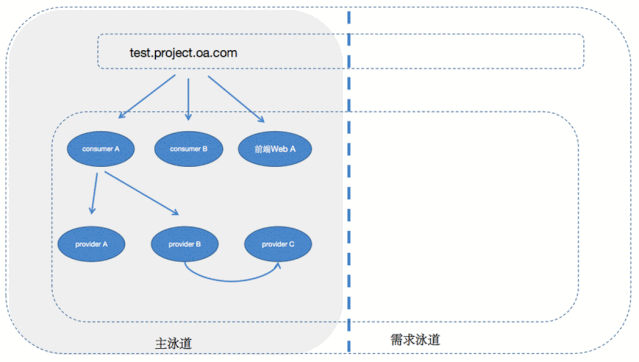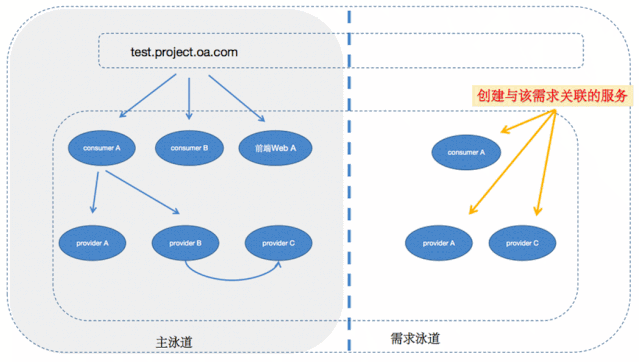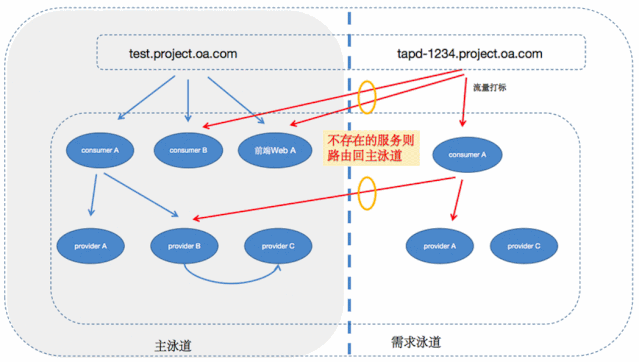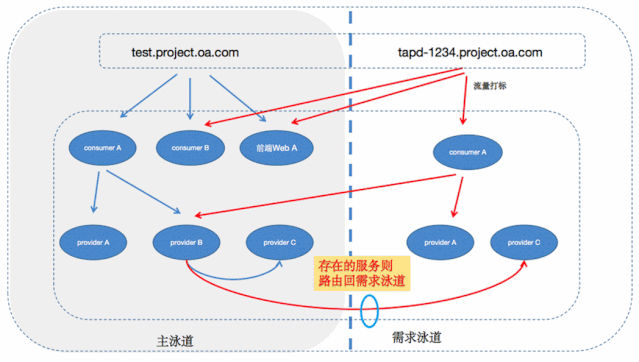
首先固定一条主泳道,包含系统完整的服务,其余泳道都对应一个需求分支,如果需求改动了一个或多个服务,那么相应泳道也将包含一个或多个服务。
然后将每条泳道都定义好一个指定的入口,如 feature-id.test.project.oa.com ,域名和泳道是一对一的关系,访问指定域名时会优先访问对应泳道中存在的服务,如果该泳道中不存在的服务则会fallback到主泳道上,以此完成整个链路的调用关系。
实现步骤:
一. 使用容器和容器编排技术来部署服务
(泳道共享技术从原理上来讲,不使用容器也能实现,但是借助容器和容器编排技术能让整个实现过程变得更简单,所以我们直接讲解基于容器的实现方式)
为什么要使用容器呢?
首先,docker容器具备较高的隔离性,安全性,镜像构建后可以放到到任意一台安装了docker的服务器快速运行起来,能较大程度提高服务部署效率和迁移的便捷性。
其次,作为一名苦逼的运维仔,其实我从来都不相信服务器是可靠的,总会有各种各样的原因让服务器崩掉,容器化部署——让服务和服务器无关才是王道!
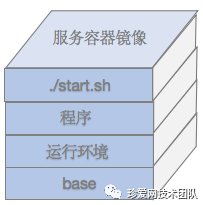
(我们的docker镜像包含了服务运行时所需要的所有东西)
为什么要使用容器编排呢?
服务容器化之后,看似节省了不少部署工作,但仍存在需要人工干预的地方,而容器编排系统则可以完全实现自动化。我们来对比两个场景的处理方式:
A:服务器负载过高,需要扩容服务节点的时候 无容器编排系统的处理方式: 列出集群中所有服务器,查看cpu、内存、网络、负载、IO使用等数据,然后人肉判断选出合适的服务器,在选中的服务器进行部署,部署完成之后服,从LB出将流量引入到该服务中。 有容器编排系统的处理方式: 定义好扩容阈值和范围后,负载过高的时候 自动选择合适的服务器节点, 自动扩容服务,自动引入流量。 B:当某个服务器出现故障或者需要下架维护服务器的时候 无容器编排系统的处理方式: 从LB层切掉所有发送到该机器的流量,停掉上面部署的服务,同时重复一遍上面人肉选服务器的过程,部署完成之后人肉导入流量。 有容器编排系统的处理方式:当服务器出现故障不通时,编排系统将 自动从现有正常的服务器集群中选择合适的服务器 自动部署确实的服务节点,而针对服务器下架,则可以直接执行驱逐命令,即可把指定服务器的服务平滑迁移走,方便且快捷。我们选用容器编排系统是k8s,因为k8s在过去一段时间和各大编排系统的竞争中脱颖而出,一举夺下容器编排系统界宝座,同时随着k8s的流行,生态圈也越来越完善。
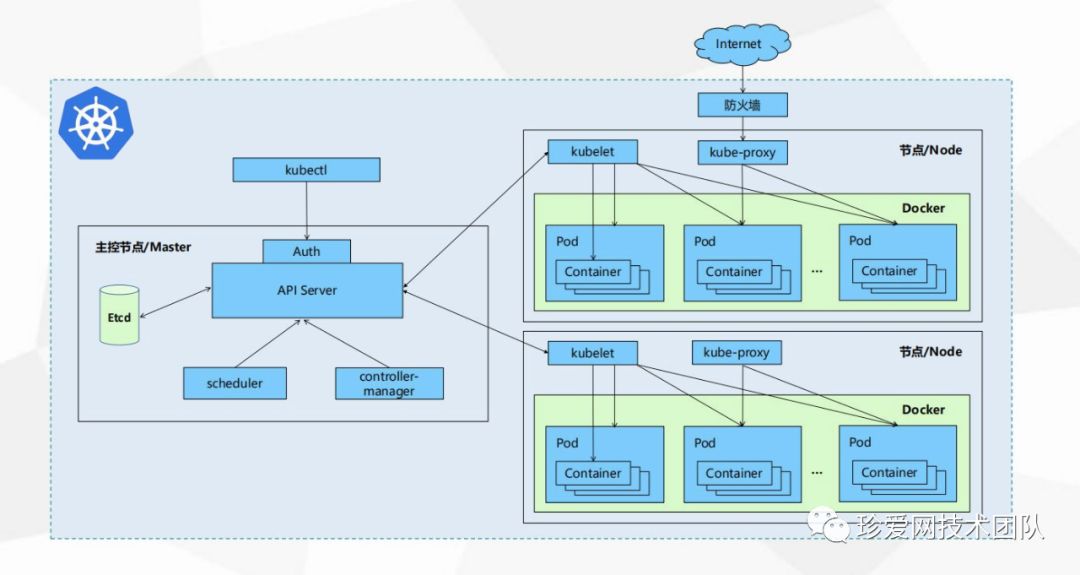
(kubenetes的集群架构图)
二. 使用Helm进行编排配置管理
编排系统的好处诸多,但采用了k8s编排系统就能一劳永逸吗?
先科普一下k8s的编排配置:
每个服务在放入k8s编排系统之前都需要准备好一份配置,告诉k8s怎么做编排,就好比我们拥有了一个厂房,里面有各种各样的自动化车床流水线,但是启动流水线之前需要有一份图纸去告诉车床怎么运作,而这个图纸就是我们所说的编排配置。
那么问题来了:
假如每个服务都有一份编排配置,突然有个需求,需要改掉所有服务都有的一个参数,常规的做法是所有的服务编排配置都修改一遍,然而每个服务都对应着4个环境(开发、测试、预发布、生产),每个环境对应着一份配置...
简单来说就是假如我们有100个微服务,那就要人工修改400次!!!
哎,摸了摸稀疏的头顶,发现我的时间不多了!!

如何高效管理K8S的编排配置呢?
首先,将服务抽象分类,分为前端、中间层、dubbo后端、springboot后端等,每类都写一份能兼容到各个环境的抽象编排配置模板。
相似的地方通过抽象的方式包装起来,那些不同的、和服务相关的特性则存放在一个单独的yaml配置文件。
配置文件片段:
# dubbo providerzhenai-crm-login-provider: base: group: crm project: zhenai-crm-login service_path: zhenai-crm-login-provider type: dubbo image: from_image: inner.harbor.oa.com/crm/openjdk-8u171-jdk-alpine:latest files: - 'target/zhenai-crm-login-provider.zip:/usr/local/app:unzip' workdir: /usr/local/app/zhenai-crm-login-provider entrypoint: sh /dubbo_start.sh k8s: helm_template_name: zhenai-crm-demo-provider livenessProbe: tcpSocket: port: 9089# tomcat serverzhenai-crm-center-server: base: group: crm project: zhenai-crm-center service_path: zhenai-crm-center-manager type: tomcat image: from_image: inner.harbor.oa.com/crm/tomcat-8.0.53-jre8-alpine:latest files: - 'target/zhenai-crm-center-web.war:/data/web-app/:unzip' workdir: /usr/local/tomcat k8s: helm_template_name: zhenai-crm-demo-server livenessProbe: httpGet: path: /_health.do port: 8080
base部分:
项目的基本信息,指定了属于哪个项目(project),该服务在这个项目中的路径
image部分:
主要是对构建docker镜像的参数做了一个抽像,从什么基础镜像构建,构建的时候需要把什么文件放到镜像中,还可以指定workdir,entrypoint等。
k8s部分:
记录了使用哪个helm模板来渲染helm配置和健康检测相关信息。
另外,我们引入helm来管理k8s的配置,将每一类的配置都做成helm chart,并将存放于helm仓库ChartMuseum。
helm chart目录结构如下:
zhenai-crm-demo-server├── Chart.yaml├── Chart_tpl.yaml├── templates│ ├── NOTES.txt│ ├── _helpers.tpl│ ├── deployment.yaml│ ├── ingress.yaml│ ├── service.yaml│ └── tests│ └── test-connection.yaml├── values.yaml└── values_tpl.yaml2 directories, 10 files
Chart.yaml记录了项目的基本项目(名字、版本等),values.yaml记录了项目之间不一样的特性变量(如健康检测端口,URL,副本数量等)。
而Chart_tpl.yaml、values_tpl.yaml都是模板文件,会根据服务的特性分别渲染成 Chart.yaml 和 values.yaml。
这样下来,即便有几百个微服务配置也只需几份模板就能搞定!
强调一下,保证项目结构的统一性非常重要!!!
三. 泳道间服务路由实现
讲完了容器和容器编排,下面我们讲一下如何基于这些技术实现泳道间服务路由
去掉lb、nginx、zk等组件,我们的服务可以抽象成两层:
第一层:包括前端和dubbo consumer(restful api)
第二层:dubbo provider(供consumer调用)
服务层次抽象出来大概长这个样子
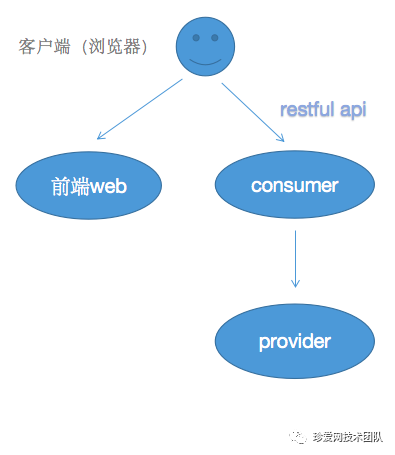
前端和consumer层的服务路由实现
这是服务接入的最外层,每个环境构建完成的时候都将生成一个唯一的域名,如:tapd-123.test.project.oa.com,当我们访问这个域名的时候,流量将进入到指定的nginx-ingress,这个nginx-ingress则为服务流量做了第一层的路由,将流量优先打到该环境的服务,如果该环境没有对应的服务,则打到主泳道也就是我们的主测试环境。
如其中的一个ingress配置(片段):
apiVersion: extensions/v1beta1kind: Ingressmetadata: name: project-ingress-tapd-123 namespace: project-crm kubernetes.io/ingress.class: nginx nginx.ingress.kubernetes.io/configuration-snippet: | proxy_set_header zone tapd-123;spec: rules: - host: tapd-123.test.project.oa.com http: paths: - backend: serviceName: zhenai-crm-invite-web-tapd-123 servicePort: http path: /invite - backend: serviceName: zhenai-crm-app-server-test servicePort: http path: /api/app
dubbo provider层的服务路由实现
dubbo框架有自己的服务注册中心,k8s并不能干预其调用策略,因此,还需要对dubbo的服务调用机制动动手脚才行。
dubbo的consumer选择provider的时候会调用loadbalancer接口,所以我们要做的就是重写dubbo的loadbalancer接口,让它的调度也能符合我们的策略。
所以思路就是,provider注册的时候带上自己的泳道信息,告诉注册中心自己是属于哪个需求环境的,然后consumer在调用provider的时候,根据流量标识去选择相应的provider,如果没找到相应的后端,同样也fallback到主泳道上。
另外,provider之间互调的情况,上面说了http可以通过header的方式记录流量的标识,那dubbo的rpc协议怎么维持流量标识呢?可以重写dubbo filter API,拦截rpc请求,再通过dubbo的隐式传参(RpcContext.getContext().setAttachment、RpcContext.getContext().getAttachment)实现参数传递。
加了服务路由后调用关系如下图所示
(服务调用过程.gif)
动图的服务名字看不清,特地奉上一张超高清大图给各位大佬
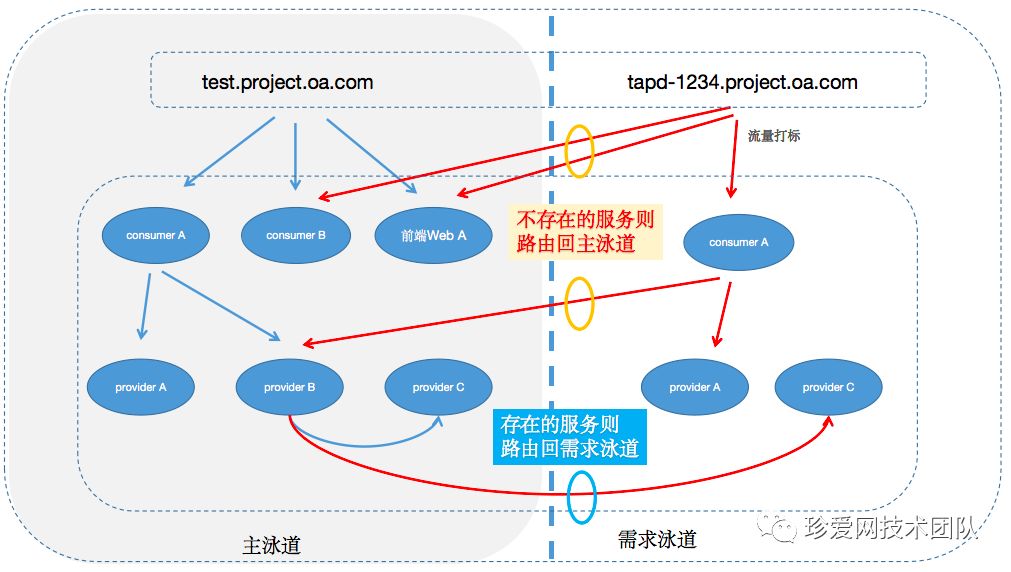
(服务调用过程.jpg)
四. 使用Jenkins Pipeline自动化构建及部署服务
我们整个Jenkins pipeline可以用一张图来描述
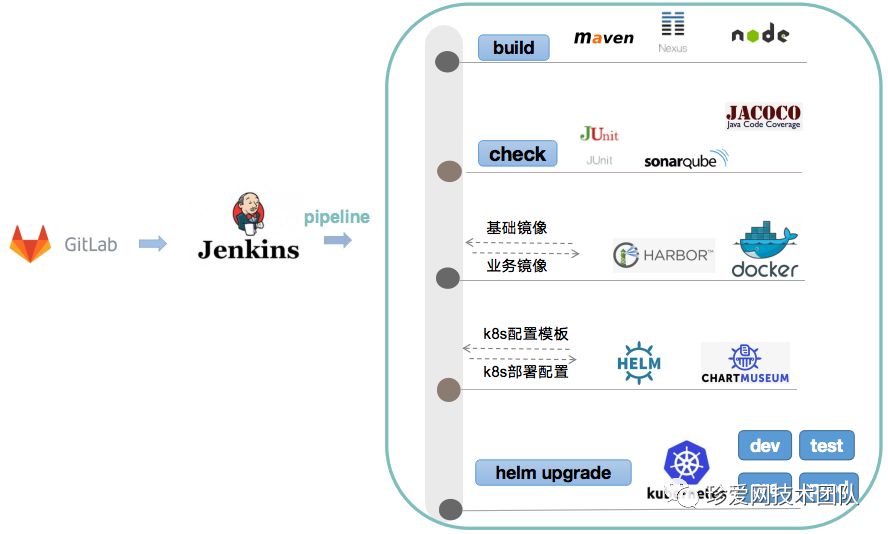
代码构建阶段:根据项目编写语言使用对应的构建工具进行构建
check阶段:做代码检测和代码扫描
镜像构建阶段:把代码构建产物和基础镜像合成业务镜像
k8s编排配置生成阶段:主要做编排配置渲染
k8s集群更新阶段:利用上一阶段生成的配置对集群的服务进行滚动更新
环境创建过程:
QA同学在构建界面输入一个需求ID
自动通过这个ID找到所有关联的服务
并发式的对匹配的服务进行编译、构建镜像和部署
完成部署后,会生成一个对该需求环境访问的URL
点击URL就能进入到由该需求构建出来的环境了
pipeline构建过程
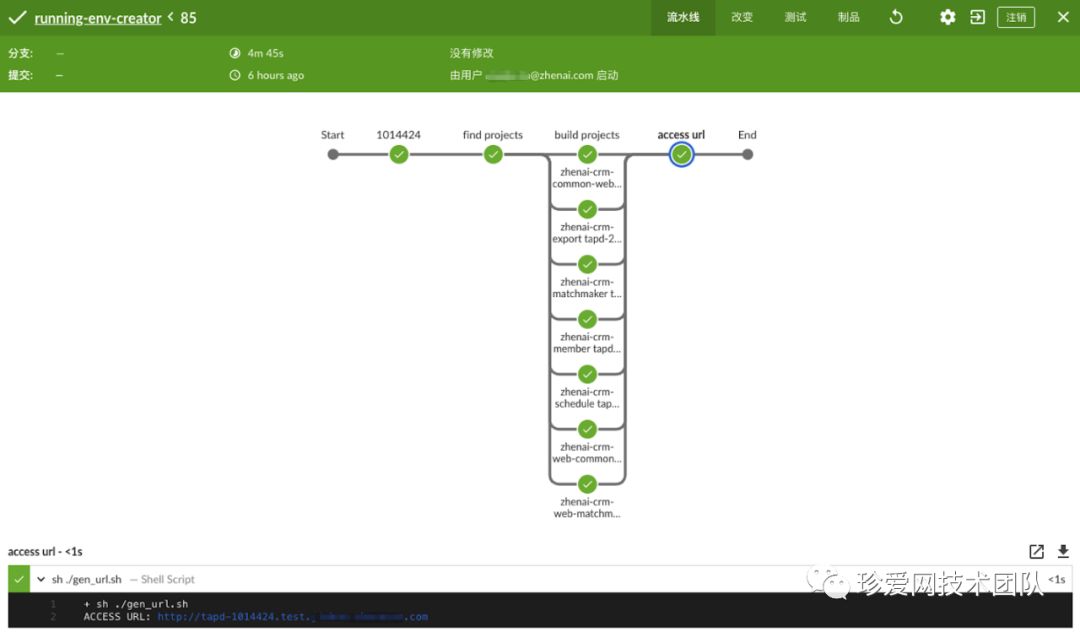
由于并发构建,所以整个环境生成仅需2-3分钟完成!
效果展示:
构建完成后会生成需求ID对应的测试环境:
tapd-123.project.oa.com (示例URL)
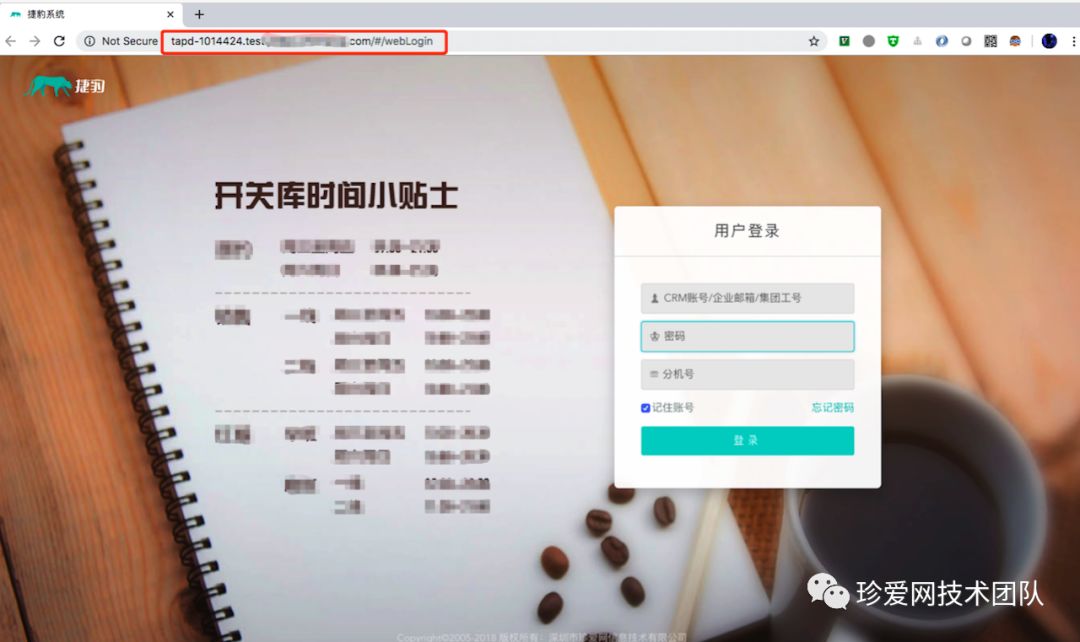
搞定!
赶紧让小花同学验收下!

转载地址:https://blog.csdn.net/weixin_32048757/article/details/112528678 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
