JavaEE 企业级分布式高级架构师(十七)ElasticSearch全文检索(1)
发布日期:2021-06-28 21:08:27
浏览次数:3
分类:技术文章
本文共 13874 字,大约阅读时间需要 46 分钟。
ElasticSearch学习笔记
基础篇
问题思考
大规模数据如何检索?
当系统数据量上了 10 亿、100 亿条的时候,我们在做系统架构的时候通常会从以下角度去考虑:
- 用什么数据库好:MySQL、Sybase、Oracle、MongoDB、HBase、…
- 如何解决单点故障:LVS、F5、A10、Zookeeper、MQ
- 如何保证数据安全性:热备、冷备、异地多活
- 如何解决检索难题:数据库代理中间件——mysql-proxy、Cobar、MaxScale等
- 如何解决统计分析问题:离线、近实时
传统数据库的应对解决方案?
对于关系型数据,我们通常采用以下或类似架构去解决查询瓶颈和写入瓶颈,解决要点:
- 通过主从备份解决数据安全性问题;
- 通过数据库代理中间件心跳检查,解决单点故障问题;
- 通过代理中间件将查询语句分发到各个 Slave 节点进行查询,并汇总结果。

- 通过分库分表解决读写效率问题:使用例如Mycat、ShardingJDBC等数据库中间件管理数据库,实现数据库水平拆分、垂直拆分、集群等。

非关系型数据库的解决方案?
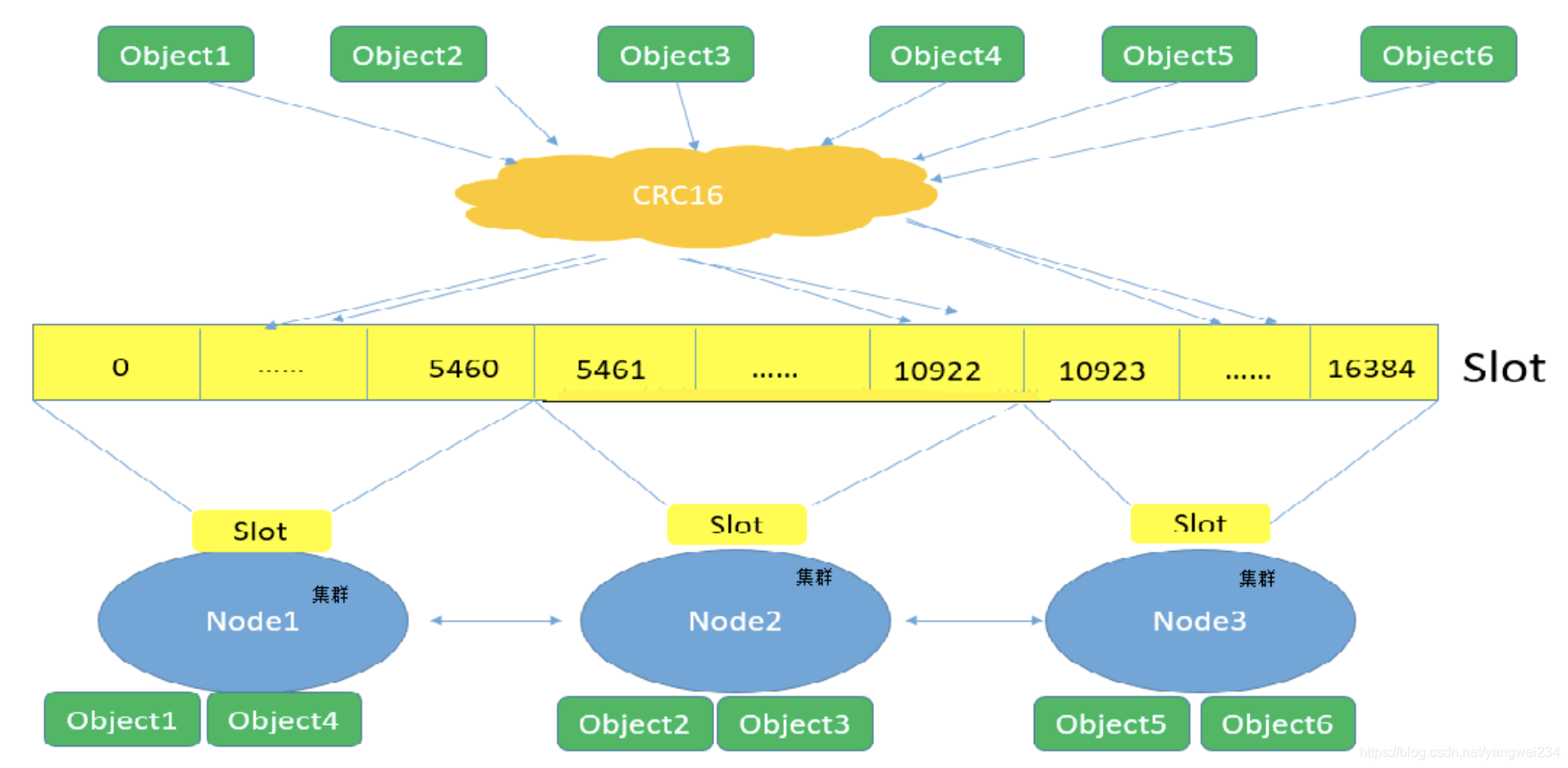
对于 NoSQL 数据库,以 Redis 为例,其它原理类似,解决要点:
- 通过副本备份保证数据安全性;
- 通过节点竞选机制解决单点问题;
- 先从配置库检索分片信息,然后将请求分发到各个节点,最后由路由节点合并汇总结果。

另辟蹊径——完全把数据放入内存怎么样?
- 完全把数据放在内存中是不可靠的,实际上也不太现实,当我们的数据达到 PB 级别时,按照每个节点 96G 内存计算,在内存完全装满的数据情况下,我们需要的机器是:1PB=1024T=1048576G,节点数=1048576/96=10922个,实际上,考虑到数据备份,节点数往往在 2.5 万台左右。成本巨大决定了其不现实!
- 从前面我们了解到,把数据放在内存也好,不放在内存也好,都不能完完全全解决问题。
- 全部放在内存速度问题是解决了,但成本问题上来了。 为解决以上问题,从源头着手分析,通常会从以下方式来寻找方法:
- ① 存储数据时按有序存储;
- ② 将数据和索引分离;
- ③ 压缩数据。
全文检索技术
什么是全文检索
结构化数据和非结构化数据
- 结构化数据:指具有固定格式或有限长度的数据,比如:数据库、元数据等
- 非结构化数据:指不固定长或无固定格式的数据,比如:互联网数据、邮件、word文档等。
全文检索基本思路
- 对非结构化数据顺序扫描很慢,对结构化数据的搜索却相对较快,那么把我们的非结构化数据想办法弄得有一定结构不就行了吗?这就是全文检索的基本思路。也即将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之为索引。
- 非结构化数据又一种叫法是全文数据。
搜索分类
按照数据的分类,搜索也分为两种:
- 对结构化数据的搜索:如对数据库的搜索,用SQL语句。再如对元数据的搜索,如利用windows搜索对文件名,类型,修改时间进行搜索等。
- 对非结构化数据的搜索:如用 Google 和 百度 可以搜索大量内容数据。
非结构化数据搜索方式
对非结构化数据也即全文数据的搜索主要有两种方法:
- 顺序扫描法:所谓顺序扫描法,就是顺序扫描每个文档内容,看看是否有要搜索的关键字,实现查找文档的功能,也就是根据文档找词。
- 反向索引法:所谓反向索引,就是提前将搜索的关键字建成索引,然后再根据索引查找文档,也就是根据词找文档。
- 这种先建立索引,再对索引进行搜索文档的过程就叫做全文检索(Full-text-Search)。
举个例子
例如查找一个词“开心”
- 情况1:词典 — 没有目录 — 查找方式:顺序扫描(从头开始,一页一页去翻,直到你找到为止)
- 情况2:词典 — 有目录 — 找找方式:先看目录(偏旁部首,拼音)—页码—找到词语对应的位置
全文检索场景
- 搜索引擎:百度、Google、必应、搜狗、…
- 站内搜索:爱奇艺、优酷、京东
- 系统文件搜索:百度文库
实时搜索和传统搜索
- 通常来说,传统搜索都是一些“静态”的搜索,即用户搜索的只是从信息库里边筛选出来的信息。而百度推出的实时搜索功能,改变了传统意义上的静态搜索模式,用户对于搜索的结果是实时变化的。
- 举个例子,用户在搜索“华山”、“峨眉山”等景点时,实时观看各地景区画面。以华山景区为例,当用户在搜索框中输入“华山”时,点击右侧“实时直播——华山”,即可实时观看华山靓丽风景,并能在华山长空栈道、北峰顶、观日台三个视角之间切换。同时,该直播引入广受年轻人欢迎的“弹幕”模式,用户在观看风景时可以同时发表评论,甚至进行聊天互动。
全文检索相关技术
- Lucene:如果使用该技术实现,需要对 Lucene 的API和底层原理非常了解,而且需要编写大量的Java代码。
- Solr:使用java实现的一个web应用,可以使用 rest 方式的 http 请求,进行远程 API 的调用。
- ElasticSearch(ES):可以使用 rest 方式的 http 请求,进行远程 API 的调用。
全文检索的流程分析
什么是索引
- 有人可能会说,对非结构化数据顺序扫描很慢,对结构化数据的搜索却相对较快(由于结构化数据有一定的结构可以采取一定的搜索算法加快速度),那么把我们的非结构化数据想办法弄得有一定结构不就行了吗?
- 这种想法很天然,却构成了全文检索的基本思路,也即将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。
- 这部分从非结构化数据中提取出的然后重新组织的信息,我们称之为索引。
- 这种说法比较抽象,举几个例子就很容易明白,比如字典,字典的拼音表和部首检字表就相当于字典的索引,对每一个字的解释是非结构化的,如果字典没有音节表和部首检字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们的非结构化数据——也即对字的解释。
流程总览
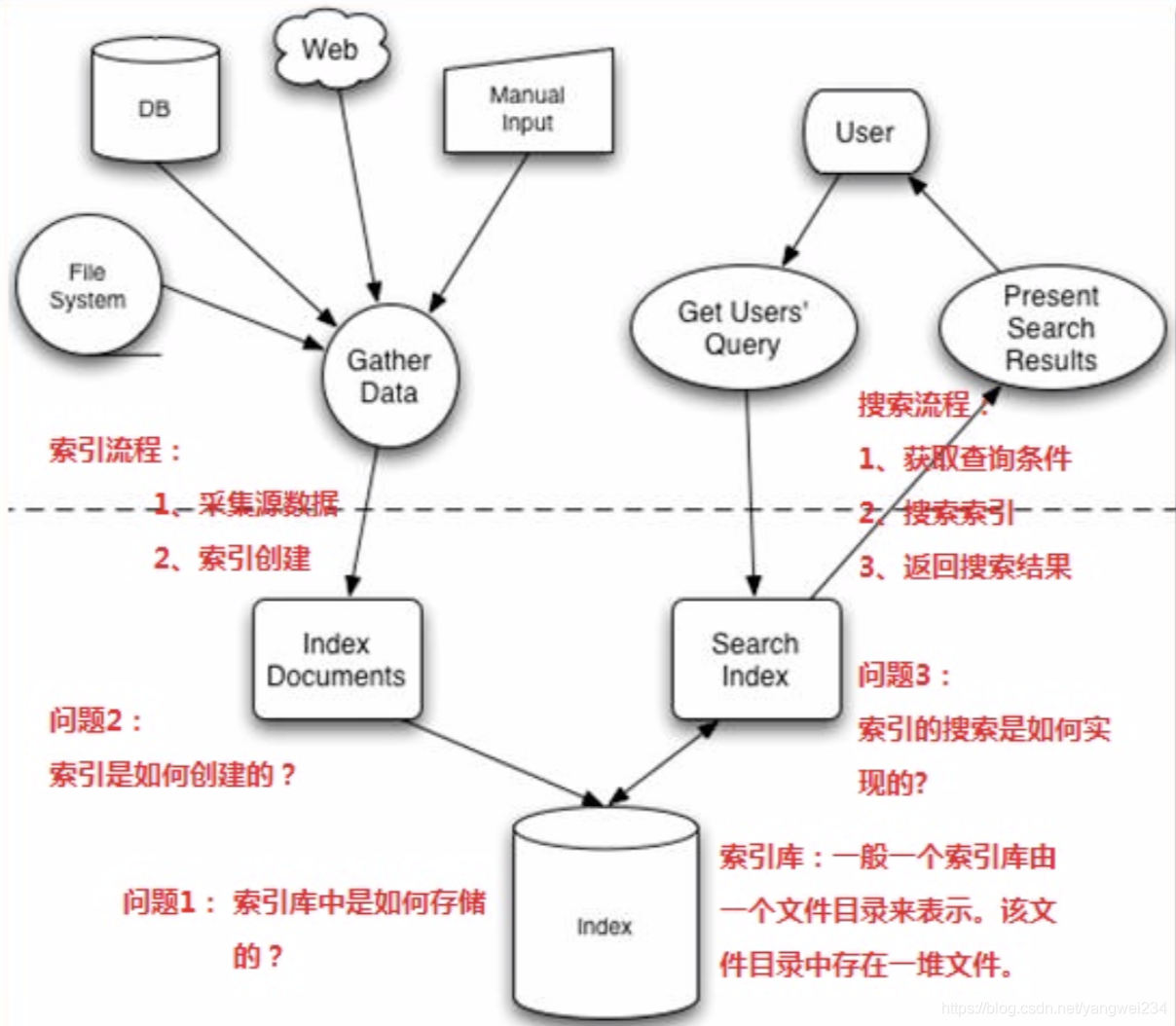
- 全文检索的流程分为两大流程:创建索引和搜索索引

- 创建索引:将现实世界中所有的结构化和非结构化数据信息提取,创建索引的过程。
- 搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
想搞清楚全文检索,必须要搞清楚三个问题:
- ① 索引库里面究竟存些什么?(Index) 索引库存储结构--------文档域的存储结构

- ② 如何创建索引?(Indexing)
- ③ 如何对索引进行搜索?(Search)
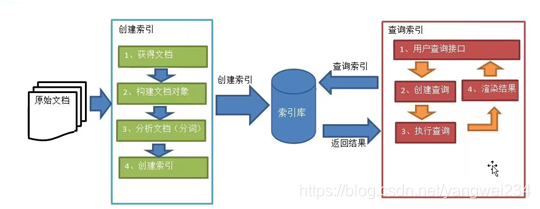
创建索引流程
- 一次索引,多次使用
原始内容
- 原始内容是指要索引和搜索的内容。(非结构化数据)
- 原始内容包括互联网上的网页、数据库中的数据、磁盘上的文件等。
获得文档
- 也就是采集数据,从互联网上、数据库、文件系统中等获取需要搜索的原始信息,这个过程就是信息采集。采集数据的目的是为了将原始内容存储到 Document 对象中。
如何采集数据?
- 对于互联网上网页,可以使用工具将网页抓取到本地生成html文件。
- 数据库中的数据,可以直接连接数据库读取表中的数据。
- 文件系统中的某个文件,可以通过I/O操作读取文件的内容。
- 在Internet上采集信息的软件通常称为爬虫或蜘蛛,也称为网络机器人,爬虫访问互联网上的每一个网页,将获取到的内容存储起来。
创建文档
- 创建文档的目的是统一数据格式(Document),方便文档分析。
- 一个Document文档中包括多个域(Field),域(Field)中存储内容。
- 这里我们可以将数据库中一条记录当成一个Document,一列当成一个Field。
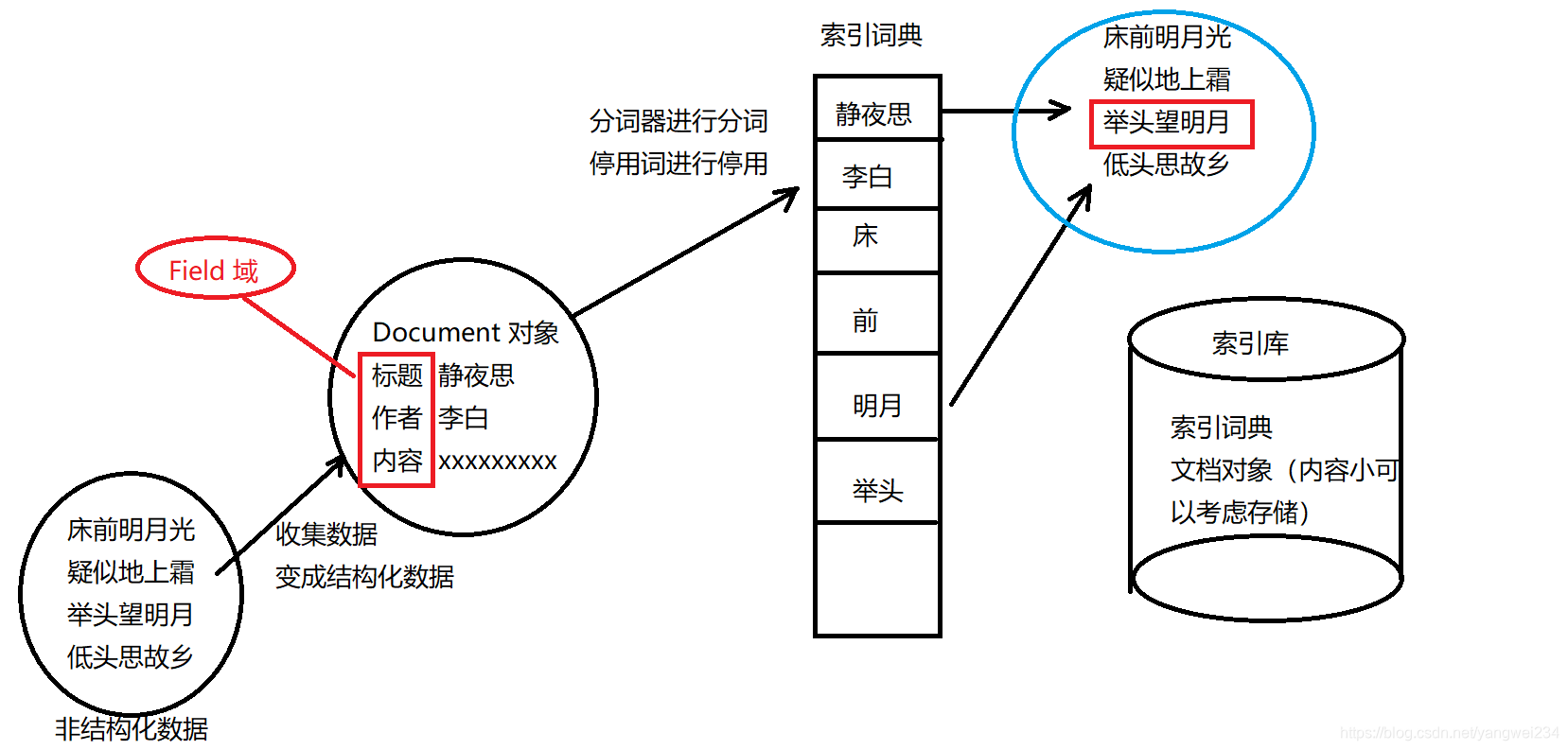
分析文档(重点)
- 分析文档主要是对Field域进行分析,分析文档的目的是为了索引。分析文档主要通过分词组件(Tokenizer)和语言处理组件(Linguistic)。
- 分词与语言处理
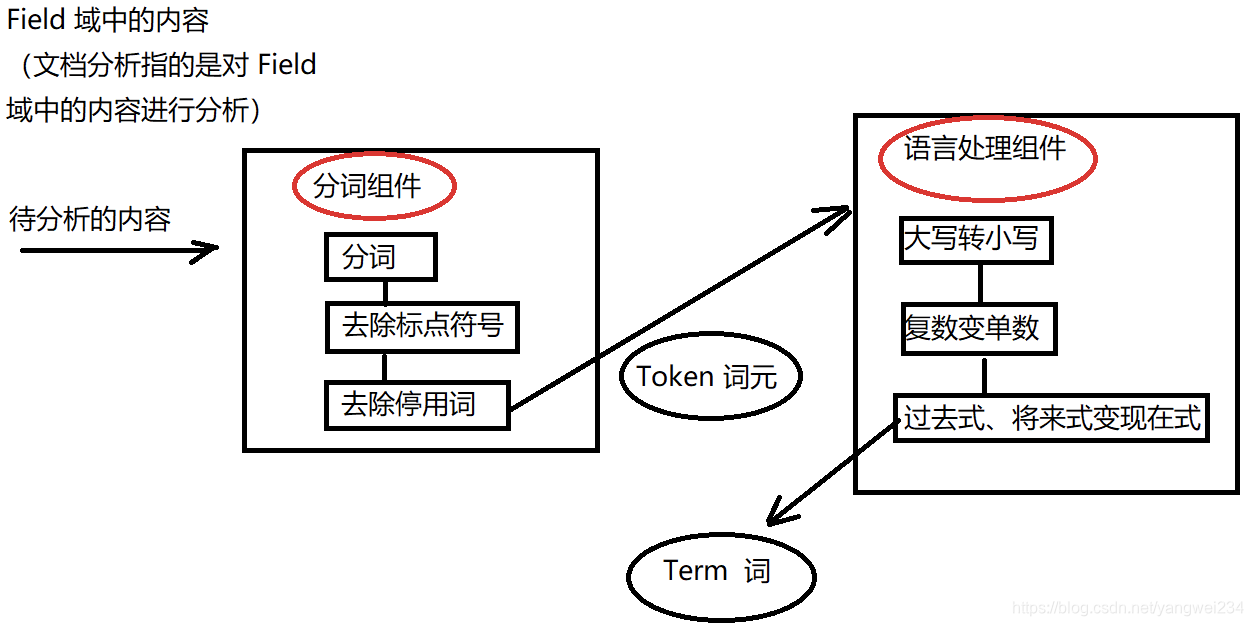
分词组件
- 分词组件工作流程(此过程称为Tokenize):
- 将Field域中的内容进行分词(不同语言有不同的分词规则);
- 去除标点符号;
- 去除停用词(stop word)。
所谓停词(Stop word)就是一种语言中最普通的一些单词,由于没有特别的意义,因而大多数情况下不能成为搜索的关键词,因而创建索引时,这种词汇被去掉而减少索引的大小。
英文中停词有:the、a、this等。 对于每一种语言的分词组件,都有一个停词集合。
- 经过分词之后得到的结果成为词元(Token)
- 示例:
# Document1 的 Field 域Students should be allowed to go out with their friends, but not allowed to drink beer.# Document2 的 Field 域My friend Jerry went to school to see his students but found them drunk which is not allowed.# 得到词元“Students”,“allowed”,“go”,“their”,“friends”,“allowed”,“drink”,“beer”,“My”,“friend”,“Jerry”,“went”,“school”,“see”,“his”,“students”,“found”,“them”,“drunk”,“allowed”。
语言处理组件
- 将得到的词元(Token)传给语言处理组件(Linguistic Processor)。
- 语言处理组件(linguistic processor)主要是对得到的词元(Token)做一些同语言相关的处理。对于英语,语言处理组件(Linguistic Processor) 一般做以下几点:
- 变为小写(Lowercase);
- 将单词缩减为词根形式,如“cars”到“car”等。这种操作称为:stemming;
- 将单词转变为词根形式,如“drove”到“drive”等。这种操作称为:lemmatization。
Stemming 和 lemmatization的异同:
- 相同之处:Stemming和lemmatization都要使词汇成为词根形式。
- 两者的方式不同:Stemming采用的是“缩减”的方式:“cars”到“car”,“driving”到“drive”。Lemmatization采用的是“转变”的方式:“drove”到“drove”,“driving”到“drive”。
- 两者的算法不同:Stemming主要是采取某种固定的算法来做这种缩减,如去除“s”,去除“ing”加“e”,将“ational”变为“ate”,将“tional”变为“tion”。Lemmatization主要是采用保存某种字典的方式做这种转变。比如字典中有“driving”到“drive”,“drove”到“drive”,“am, is, are”到“be”的映射,做转变时,只要查字典就可以了。
- Stemming和lemmatization不是互斥关系,是有交集的,有的词利用这两种方式都能达到相同的转换。
- 语言处理组件(linguistic processor)的结果称为词(Term) :
“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“jerry”,“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”。
- 也正是因为有语言处理的步骤,才能使搜索drove,而drive也能被搜索出来。
索引文档
- 索引的目的是为了搜索。
- 将得到的词(Term)传给索引组件(Indexer),索引组件主要做以下几件事情:
创建Term字典
- 在我们的例子中字典如下:
| TERM | DOCUMENT ID |
|---|---|
| student | 1 |
| allow | 1 |
| go | 1 |
| their | 1 |
| friend | 1 |
| allow | 1 |
| drink | 1 |
| beer | 1 |
| my | 2 |
| friend | 2 |
| jerry | 2 |
| go | 2 |
| school | 2 |
| see | 2 |
| his | 2 |
| student | 2 |
| found | 2 |
| them | 2 |
| drunk | 2 |
| allow | 2 |
排序Term字典
- 对字典按字母顺序进行排序:
| TERM | DOCUMENT ID |
|---|---|
| allow | 1 |
| allow | 1 |
| allow | 2 |
| beer | 1 |
| drink | 1 |
| drunk | 2 |
| found | 2 |
| friend | 1 |
| friend | 2 |
| go | 1 |
| go | 2 |
| his | 2 |
| jerry | 2 |
| my | 2 |
| school | 2 |
| see | 2 |
| student | 1 |
| students | 2 |
| their | 1 |
| them | 2 |
合并Term字典
- 合并相同的词(Term)成为文档倒排(Posting List)链表
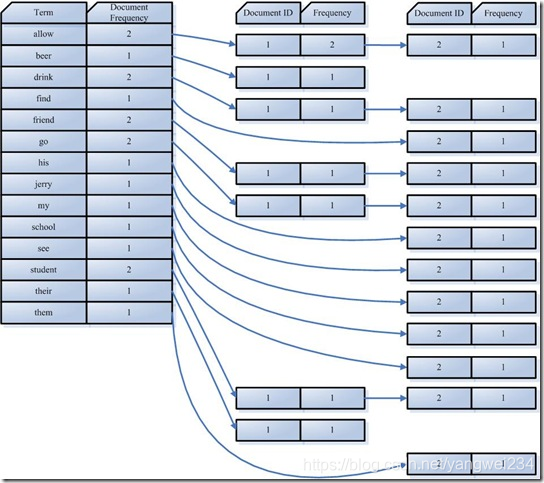
- 在此表中,有几个定义:
- Document Frequency:即文档频次,表示总共有多少文件包含此词(Term)
- Frequency:即词频率,表示此文件中包含了几个该词(Term)
- 到此为止,索引已经创建好了。
- 最终的索引结构是一种倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它的规模较小,而文档集合较大。
- 倒排索引结构是根据内容(词汇)找文档,如下图:

搜索索引流程
查询语句
- 查询语句格式如下:
1、域名:关键字, 比如 name:lucene2、域名:[min To max], 比如 price:[1 To 9]# 多个查询语句之间,使用关键字 AND、OR、NOT 表示逻辑关系
- 用户输入查询语句如下:
lucene AND learned NOT hadoop
执行搜索
第一步
- 对查询语句进行词法分析、语法分析及语言处理
词法分析
- 如上述例子中,经过词法分析,得到单词有 lucene、learned、hadoop,关键字有 AND、NOT。
注意:关键字必须大写,否则就作为普通单词处理。
语法分析
- 如果发现查询语句不满足语法规则,则会报错。如lucene NOT AND learned,则会出错。如上述例子,lucene AND learned NOT hadoop形成的语法树如下:

语言处理
- 如learned变成learn等。经过下面的第二步,我们得到一棵经过语言处理的语法树。

第二步
- 搜索索引,得到符号语法树的文档。
- 首先,在反向索引表中,分别找出包含lucene,learn,hadoop的文档链表。
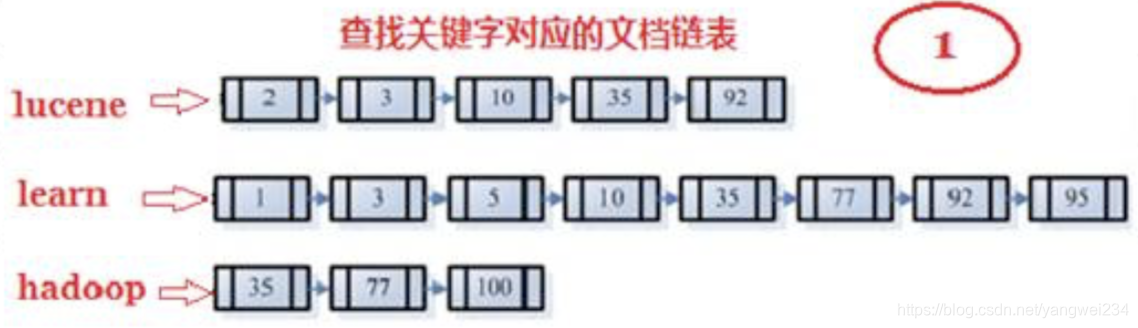
- 其次,对包含lucene,learn的链表进行合并操作,得到既包含lucene又包含learn的文档链表。
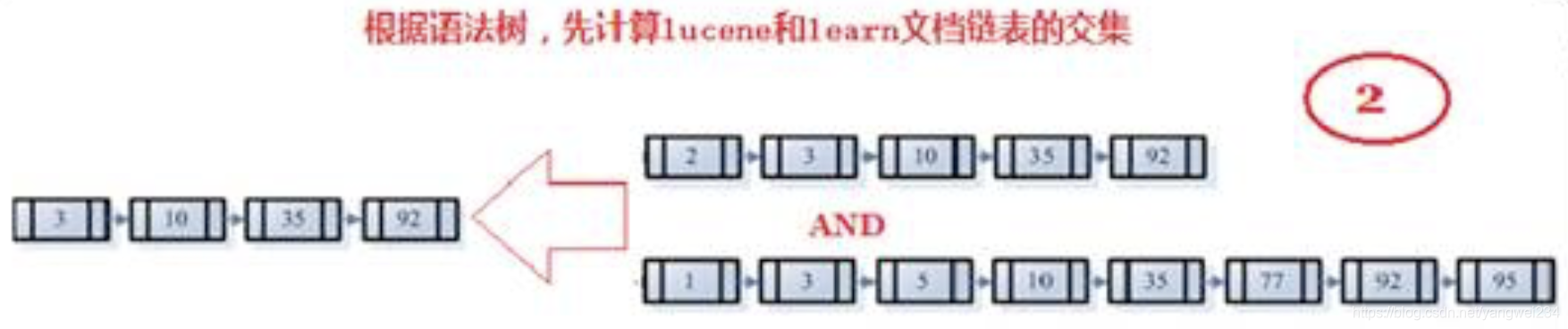
- 然后,将此链表与hadoop的文档链表进行差操作,去除包含hadoop的文档,从而得到既包含lucene又包含learn而且不包含hadoop的文档链表。
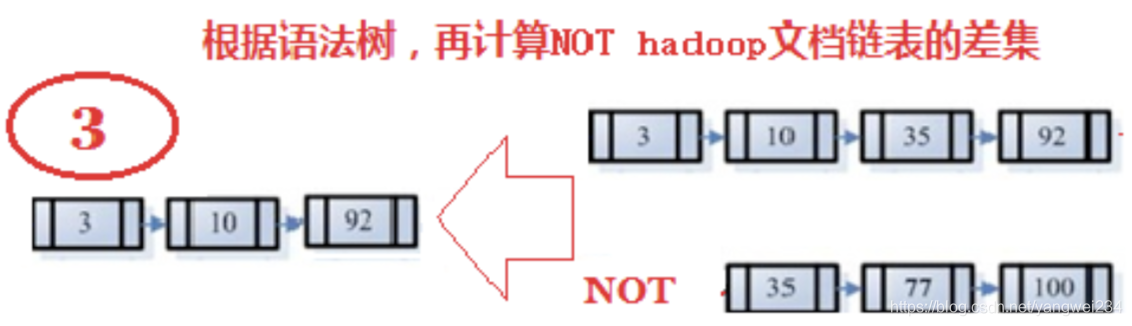
- 此文档链表就是我们要找的文档。
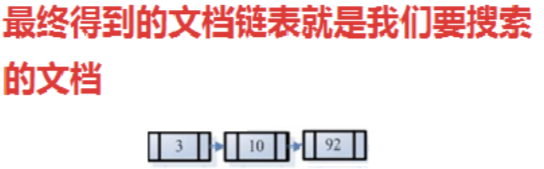
第三步
- 根据得到的文档和查询语句的相关性,对结果进行排序
- 相关度自然打分(权重越高分越高)
- tf越高、权重越高
- df越高、权重越低
- 人为影响分数:设置Boost值(加权值)

Lucene相关度排序
什么是相关度排序
- **相关度排序是查询结果按照与查询关键字的相关性进行排序,越相关的越靠前。**比如搜索“Lucene”关键字,与该关键字最相关的文章应该排在前边。
相关度打分
Lucene对查询关键字和索引文档的相关度进行打分,得分高的就排在前边。
**如何打分呢?**Lucene是在用户进行检索时实时根据搜索的关键字计算出来的,分两步:
- 计算出词(Term)的权重
- 根据词的权重值,计算文档相关度得分
什么是词的权重?
- 通过索引部分的学习,明确索引的最小单位是一个Term(索引词典中的一个词)。搜索也是从索引域中查询Term,再根据Term找到文档。Term对文档的重要性称为权重,影响Term权重有两个因素:
- Term Frequency(tf):指这个Term在当前的文档中出现了多少次。tf 越大说明越重要。词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要,如“Lucene”这个词,在文档中出现的次数很多,说明该文档主要就是讲Lucene技术的。
- Document Frequency(df):指有多少个文档包含这个Term。df 越大说明越不重要。比如:在某篇英文文档中,this出现的次数很多,能说明this重要吗?不是的,有越多的文档包含此词(Term),说明此词(Term)越普通,不足以区分这些文档,因而重要性越低。
设置boost值影响相关度排序
- **boost是一个加权值(默认加权值为1.0f),也可以影响权重的计算。**在索引时对某个文档中的eld设置加权值,设置越高,在搜索时匹配到这个文档就可能排在前边。
Lucene的Field域
Field属性
- Field是文档中的域,包括Field名和Field值两部分,一个文档可以包括多个Field,Document只是Field的一个承载体,Field值即为要索引的内容,也是要搜索的内容。
是否分词(tokenized)
- 是:作分词处理,即将Field值进行分词,分词的目的是为了索引。比如:商品名称、商品描述等,这些内容用户要输入关键字搜索,由于搜索的内容格式大、内容多需要分词后将语汇单元建立索引。
- 否:不作分词处理。比如:商品id、订单号、身份证号等。
是否索引(indexed)
- 是:进行索引。将Field分词后的词或整个Field值进行索引,存储到索引域,索引的目的是为了搜索。比如:商品名称、商品描述分析后进行索引,订单号、身份证号不用分词但也要索引,这些将来都要作为查询条件。
- 否:不索引。比如:图片路径、文件路径等,不用作为查询条件的不用索引。
是否存储(stored)
- 是:将Field值存储在文档域中,存储在文档域中的Field才可以从Document中获取。比如:商品名称、订单号,凡是将来要从Document中获取的Field都要存储。
- 否:不存储Field值。比如: 商品描述,内容较大不用存储。如果要向用户展示商品描述可以从系统的关系数据库中获取。
Field常用类型
- 下边列出了开发中常用 的Filed类型,注意Field的属性,根据需求选择:
| FIELD类 | 数据类型 | ANALYZED是否分词 | INDEXED是否索引 | STORED | 说明 |
|---|---|---|---|---|---|
| StringField(FieldName, FieldValue,Store.YES)) | 字符串 | N | Y | Y或N | 这个Field用来构建一个字符串Field,但是不会进行分词,会将整个串存储在索引中,比如(订单号,身份证号等)是否存储在文档中用Store.YES或Store.NO决定 |
| LongField(FieldName, FieldValue,Store.YES) | Long型 | Y | Y | Y或N | 这个Field用来构建一个Long数字型Field,进行分词和索引,比如(价格)是否存储在文档中用Store.YES或Store.NO决定 |
| StoredField(FieldName, FieldValue) | 重载方法,支持多种类型 | N | N | Y | 这个Field用来构建不同类型Field不分析,不索引,但要Field存储在文档中 |
| TextField(FieldName, FieldValue, Store.NO)或TextField(FieldName, reader) | 字符串或流 | Y | Y | Y或N | 如果是一个Reader, lucene猜测内容比较多,会采用Unstored的策略 |
Field设计
Field域如何设计,取决于需求,比如搜索条件有哪些?显示结果有哪些?
- 商品id: 是否分词:不用分词,因为不会根据商品id来搜索商品。 是否索引:不索引,因为不需要根据商品ID进行搜索。 是否存储:要存储,因为查询结果页面需要使用id这个值。
- 商品名称: 是否分词:要分词,因为要根据商品名称的关键词搜索。 是否索引:要索引。 是否存储:要存储。
- 商品价格: 是否分词:要分词,lucene对数字型的值只要有搜索需求的都要分词 和索引,因为lucene对数字型的内容要特殊分词处理,需要分词和索 引。 是否索引:要索引。 是否存储:要存储。
- 商品图片地址: 是否分词:不分词。 是否索引:不索引。 是否存储:要存储。
- 商品描述: 是否分词:要分词。 是否索引:要索引。 是否存储:因为商品描述内容量大,不在查询结果页面直接显示,不存储。
常见问题:不存储是指不在lucene的索引域中记录,目的是为了节省lucene的索引文件空间。
如果要在详情页面显示描述,解决方案:从 lucene 中取出商品的id,根据商品的id查询关系性数据库(MySQL)中 item 表得到描述信息。
ElasticSearch介绍
基本概述
- Elasticserach由来:许多年前,一个叫Shay Banon的待业工程师跟随他的新婚妻子来到伦敦,他的妻子想在伦敦学习做一名厨师。而他在伦敦寻找工作的期间,接触到了Lucene的早期版本,他想为自己的妻子开发一个方便搜索菜谱的应用。
- Elasticsearch发布的第一个版本是在2010年的二月份,从那之后,Elasticsearch便成了Github上最受人瞩目的项目之一,并且很快就有超过300名开发者加入进来贡献了自己的代码。后来Shay和另一位合伙人成立了公司专注打造Elasticsearch,他们对Elasticsearch进行了一些商业化的包装和支持。但是,Elasticsearch承诺,永远都将是开源并且免费的。
- Elastic为主体的公司提供了很多优秀的解决方案,拿到很多的投资,现已上市,后来收购logstash、kibana及一些其他的服务。
- 据国际权威的数据库产品评测机构DBEngines的统计,在2016年1月,Elasticsearch已超过Solr等,成为排名第一的搜索引擎类应用。
问题思考
ES是什么?
- ES = elasticsearch简写, Elasticsearch是一个开源的高扩展的分布式全文检索引擎。
- Elasticsearch 使用Java开发,并使用Lucene作为其核心,来实现所有索引和搜索的功能。但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{ "name": "John", "sex": "Male", "age": 25, "birthDate": "1990/05/01", "about": "I love to go rock climbing", "interests": [ "sports", "music" ]} 为什么需要ES?
ES国内外使用优秀案例
- 2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。 “GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码”。
- 维基百科:启动以elasticsearch为基础的核心搜索架构。
- SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”。
- 百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据。
我们也需要
- 实际项目开发实战中,几乎每个系统都会有一个搜索的功能,当搜索做到一定程度时,维护和扩展起来难度就会慢慢变大,所以很多公司都会把搜索单独独立出一个模块,用ElasticSearch等来实现。
- 近年ElasticSearch发展迅猛,已经超越了其最初的纯搜索引擎的角色,现在已经增加了数据聚合分析(aggregation)和可视化的特性,如果你有数百万的文档需要通过关键词进行定位时,ElasticSearch肯定是最佳选择。
- 当然,如果你的文档是JSON的,你也可以把ElasticSearch当作一种“NoSQL数据库”, 应用ElasticSearch数据聚合分析(aggregation)的特性,针对数据进行多维度的分析。
ES有什么能力?
- Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 ApacheLucene™ 基础上的搜索引擎。
- 实际项目开发实战中,几乎每个系统都会有一个搜索的功能,当数据达到很大且搜索要做到一定程度时,维护和扩展难度就会越来越高,并且在全文检索的速度上、结果内容的推荐、分析以及统计聚合方面也很难达到我们预期效果。
- 并且 Elasticsearch ,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。(实时的存储、检索数据)
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。(集群只能支持:上百台 ---- 中等规模的数据)
使用场景?
- 网站搜索:可以自动搜索、自动补全建议、关键词搜索
- 日志分析:ELK——ElaSticSearch(日志收集) + LogStash(日志分析) + Kibana(运维)
- 数据预警:Watcher监控数据
- 商业智能数据分析:今日头条、数据分析、机器学习
- 一线公司ES使用场景:
- 新浪ES 如何分析处理32亿条实时日志
- 阿里ES 构建挖财自己的日志采集和分析体系
- 有赞ES 业务日志处理
- ES实现站内搜索
ES 和 Solr 的比较
检索速度比较
- 当单纯的对已有数据进行搜索时,Solr更快。
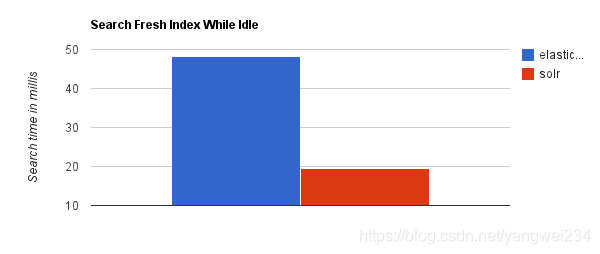
- 当实时建立索引时,Solr 会产生 io 阻塞,查询性能较差,Elasticsearch 具有明显的优势。
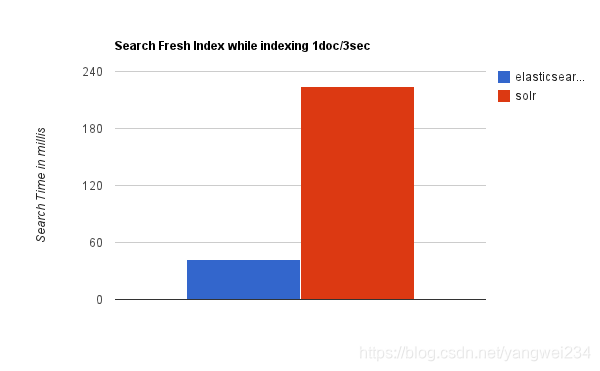
- 随着数据量的增加,Solr 的搜索效率会变得更低,而 Elasticsearch 却没有明显的变化。
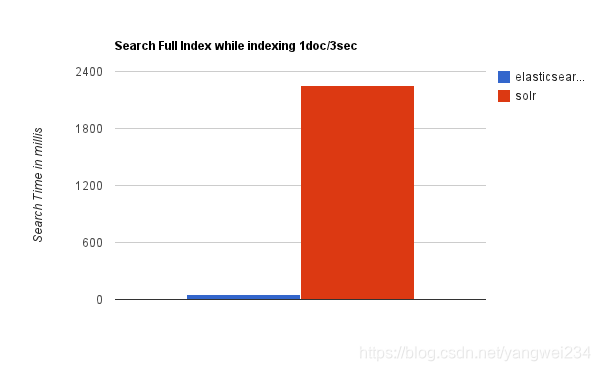
- 大型互联网公司,实际生产环境测试 ,将搜索引擎从 Solr 转到 ElasticSearch 以后的平均查询速度有了50倍的提升
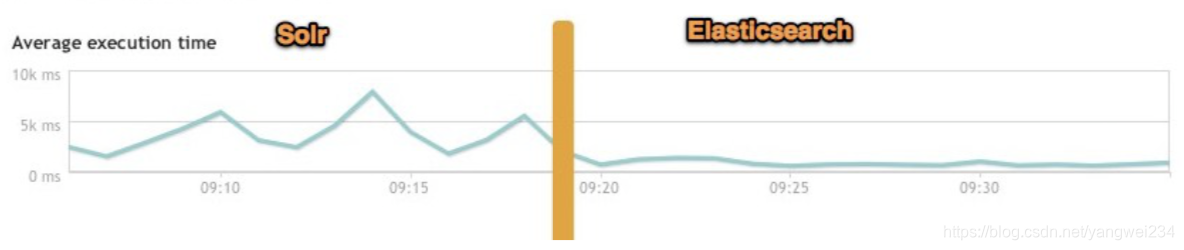
比较总结
- 二者安装都很简单;
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
- Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
- 最终结论:Solr 是传统搜索应用的有力解决方案,但 ElasticSearch 更适合用于新兴的实时搜索应用。
ElasticSearch架构
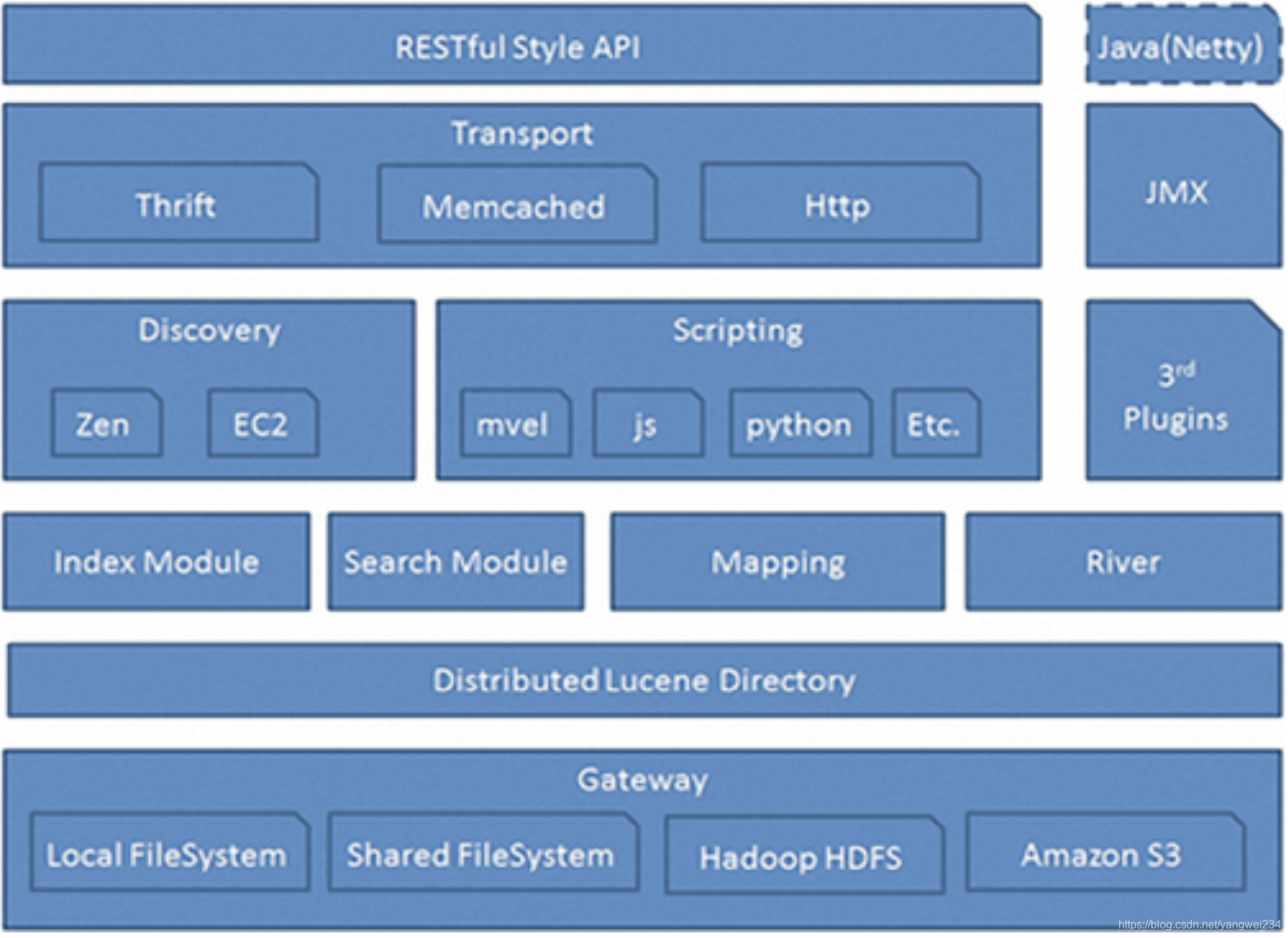
网关Gateway层
- 底层文件系统:ES用来存储索引文件的一个文件系统且它支持很多类型,例如:本地磁盘、共享存储(做snapshot的时候需要用到)、hadoop的hdfs分布式存储、亚马逊的S3。
- 主要职责:是用来对数据进行长持久化以及整个集群重启之后可以通过gateway重新恢复数据。代表es索引的持久化存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到硬盘。
- 数据安全:当这个es集群关闭再重新启动时就会从gateway中读取索引数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
- 存储数据:存储索引信息、集群信息、mapping 等等。
Distributed Lucene Directory
- Gateway上层就是一个lucene的分布式框架。
- Lucene 是做检索的,但是它是一个单机的搜索引擎,像这种 es 分布式搜索引擎系统,虽然底层用 Lucene ,但是需要在每个节点上都运行 Lucene 进行相应的索引、查询以及更新,所以需要做成一个分布式的运行框架来满足业务的需要。
四大模块组件
districted lucene directory 之上就是一些ES的四大模块:
- Index Module:索引模块,就是对数据建立索引也就是通常所说的建立一些倒排索引等;
- Search Module:搜索模块,就是对数据进行查询搜索;
- Mapping Module:数据映射与解析模块,就是你的数据的每个字段可以根据你建立的表结构通过mapping进行映射解析,如果你没有建立表结构,es就会根据你的数据类型推测你的数据结构之后自己生成一个mapping,然后都是根据这个mapping进行解析你的数据;
- River Module:在es2.0之后应该是被取消了,它的意思表示是第三方插件,例如可以通过一些自定义的脚本将传统的数据库(mysql)等数据源通过格式化转换后直接同步到es集群里,这个River大部分是自己写的,写出来的东西质量参差不齐,将这些东西集成到es中会引发很多内部bug,严重影响了es的正常应用,所以在es2.0之后考虑将其去掉。
自动发现Discovery、Script
ES四大模块组件之上有 Discovery 模块:
- es是一个集群包含很多节点,很多节点需要互相发现对方,然后组成一个集群包括选主的,这些es都是用的discovery模块,默认使用的是 Zen,也可是使用EC2;es是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
- es查询还可以支撑多种script即脚本语言,包括mvel、js、python等等。
通信(Transport)
- 代表es内部节点或集群与客户端的交互方式,默认内部是使用 tcp 协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
- 节点间通信端口默认:9300-9400。
- JMX 就是 java 的一个远程监控管理框架,因为 es 是通过 java 实现的。
Restful接口层
最上层就是ES暴露给我们的访问接口
- 官方推荐的方案就是这种Restful接口,直接发送http请求,方便后续使用nginx做代理、分发包括可能后续会做权限的管理,通过http很容易做这方面的管理。如果使用java客户端它是直接调用api,在做负载均衡以及权限管理还是不太好做。
ElasticSearch概念说明
- Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。Elasticsearch比传统关系型数据库如下:
Relational DB -> Databases -> Tables -> Rows -> ColumnsElasticsearch -> Indices -> (Types) -> Documents -> Fields
索引 index
- 一个索引就是一个拥有几分相似特征的文档的集合。
- 比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
类型 type
- 在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。
- 通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
文档 document
- 一个文档是一个可被索引的基础信息单元。
- 比如,你可以拥有某一个客户的文档,某一个产品的一个文档。当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
- 在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。
字段 field
- 相当于是数据表的字段,对文档数据根据不同属性进行的分类标识。
映射 mapping
- mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
转载地址:https://blog.csdn.net/yangwei234/article/details/95958522 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
感谢大佬
[***.8.128.20]2024年04月05日 12时16分35秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
Java:对象的引用类型:强引用、软引用、弱引用、和虚引用
2019-04-29
react消息订阅与发布机制
2019-04-29
React路由(1)-前端路由的基石 history
2019-04-29
React路由(2)-路由的基本使用
2019-04-29
React路由(3)-一般组件和路由组件
2019-04-29
C# richTextBox显示不同颜色文字
2019-04-29
C#连接ACCESS
2019-04-29
c#richtextbox的内容保存为TXT文本
2019-04-29
Windows.old可以删除吗?
2019-04-29
VS2012类视图查看函数
2019-04-29
VS项目添加附加目录
2019-04-29
VS找到汇编指令对应的16进制字符
2019-04-29
VS生成依赖项关系图
2019-04-29
VC6.0栈回溯
2019-04-29
VS2010:Tips
2019-04-29
VS改项目名称
2019-04-29
ArcMap加载SHP文件
2019-04-29
arcgis如何导出属性表为excel
2019-04-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 309228975 位访客
访问时间: 2024-04-30 04:06:59
访问IP: 3.145.108.9
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版