JavaEE 企业级分布式高级架构师(十七)ElasticSearch全文检索(2)
发布日期:2021-06-28 21:08:28
浏览次数:2
分类:技术文章
本文共 11842 字,大约阅读时间需要 39 分钟。
ElasticSearch学习笔记
实操篇
ElasticSearch相关软件安装
ES单机安装
下载安装包
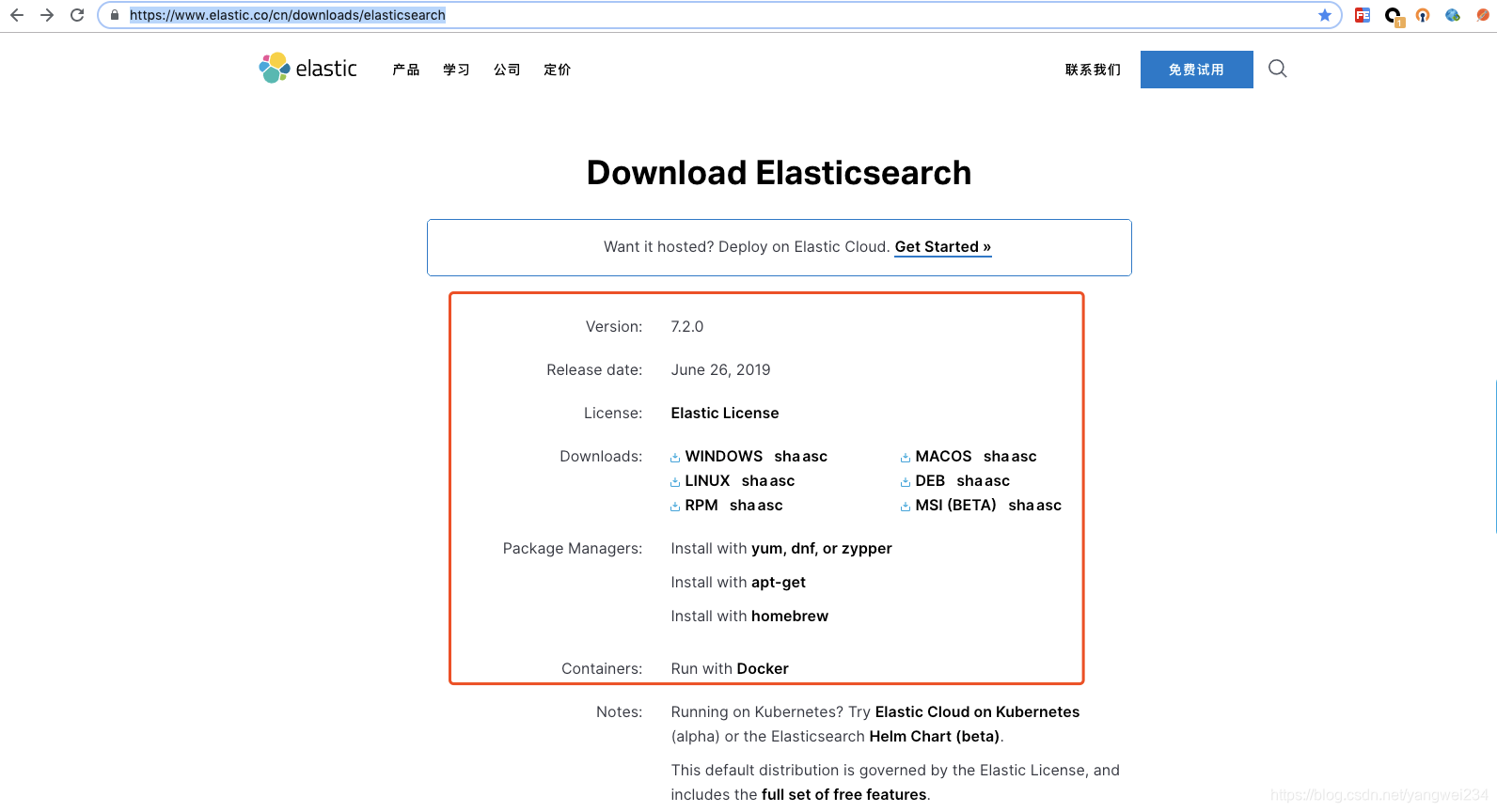
- 官网地址:https://www.elastic.co/cn/
- 下载地址:https://www.elastic.co/cn/downloads/elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.2.0-linux-x86_64.tar.gz
解压缩修改配置文件
- cd 到 ElasticSearch 下载目录,并进行解压缩
cd /usr/toolstar -zxvf elasticsearch-7.2.0-linux-x86_64.tar.gz -C /usr/apps/elasticsearch/
- cd 到 ElasticSearch 解压缩目录,并修改配置文件
cd /usr/apps/elasticsearch/elasticsearch-7.2.0vim config/elasticsearch.yml
- 注意修改点:
cluster.name: my-applicationnode.name: node-1# 设置外网访问,默认配置外网无法访问network.host: 192.168.254.120http.port: 9200# 设置集群master节点cluster.initial_master_nodes: ["node-1"]
- 如果不设置集群节点,就会报错:
[1]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
启动ElasticSearch
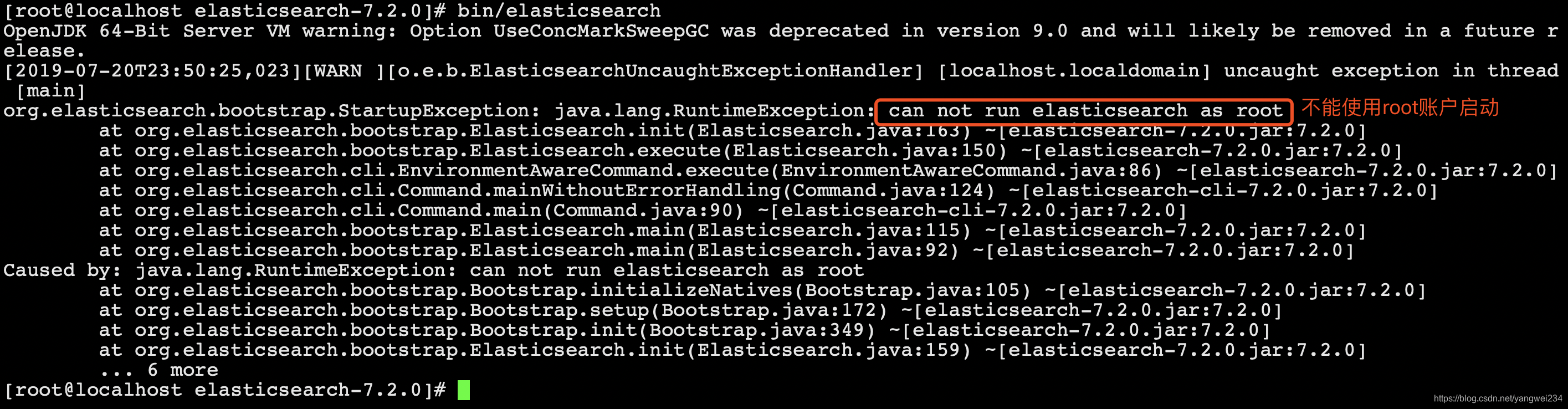
- 不要以root用户进行启动:
- 设置用户名和密码:
useradd yangwei echo "Password" | passwd yangwei --stdin
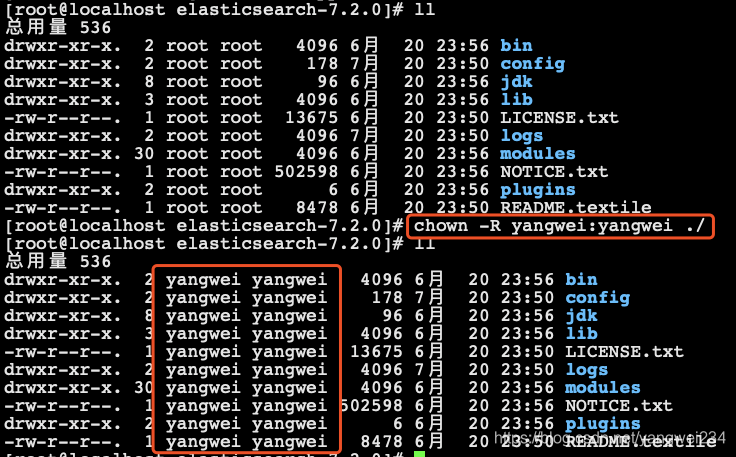
- 修改elasticsearch目录所有者:
[root@localhost elasticsearch-7.2.0]# chown -R yangwei:yangwei ./
- 修改root权限:
vim /etc/sudoers

- 启动:
su yangweibin/elasticsearch

修改系统环境变量
vim /etc/sysctl.conf
- 添加如下内容:
[yangwei@localhost elasticsearch-7.2.0]$ sudo vim /etc/sysctl.conf
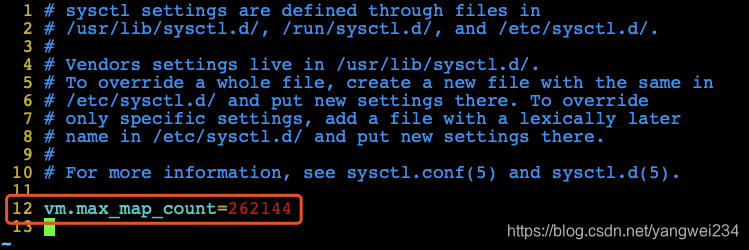
- 修改完后需要重新启动才能生效
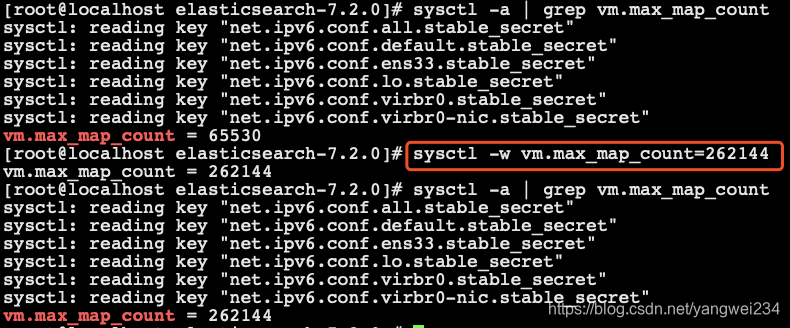
[yangwei@localhost elasticsearch-7.2.0]$ sysctl -a | grep vm.max_map_count[yangwei@localhost elasticsearch-7.2.0]$ sudo sysctl -w vm.max_map_count=262144
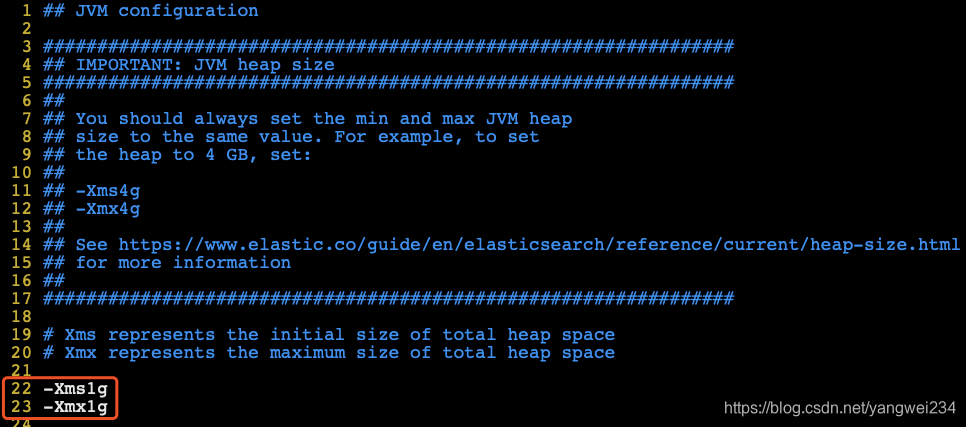
修改JVM分配大小
主要xms和xmx大小要一致
vim config/jvm.options
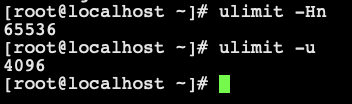
修改最大文件描述符数量和用户最大线程数
[yangwei@localhost elasticsearch-7.2.0]$ sudo vim /etc/security/limits.conf* soft nofile 65536* hard nofile 65536* soft nproc 4096* hard nproc 4096

- 注意:此文件修改后需要重新登录用户,才会生效。
- 重启查看:
# 查看最大文件描述符ulimit -Hn # 查看用户最大线程数ulimit -u
后台启动
bin/elasticsearch &# 或者bin/elasticsearch -d
- 启动成功:
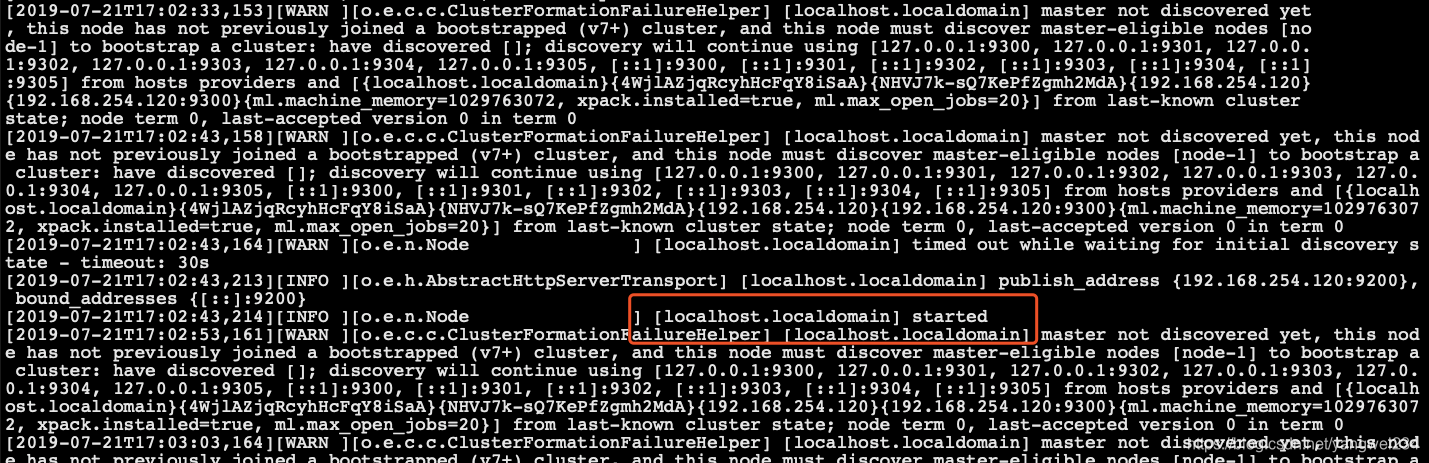
- 查看进程:

- 访问一下:http://192.168.254.120:9200/
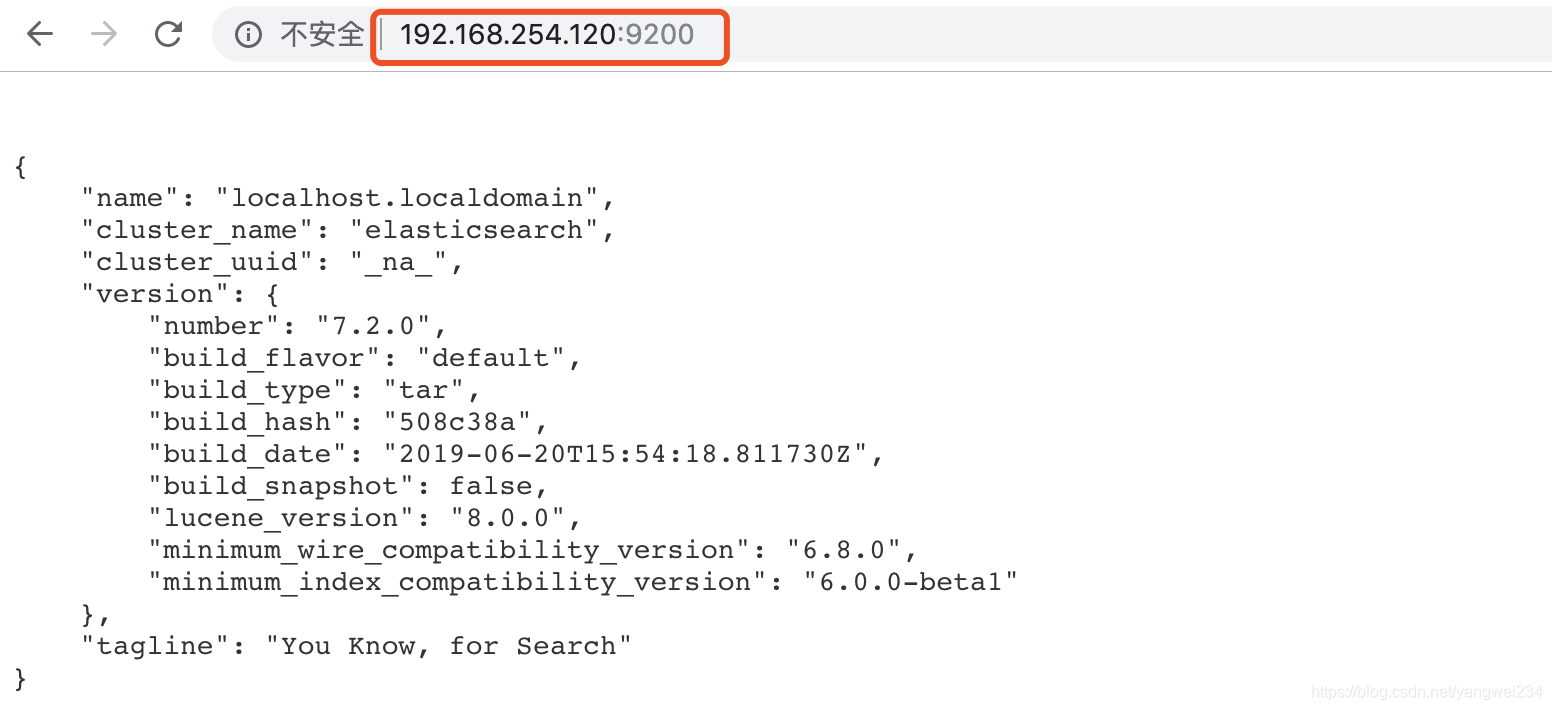 http://192.168.254.120:9200/_cat/health
http://192.168.254.120:9200/_cat/health 
使用Docker容器安装ES
#搜索镜像docker search elasticsearch#拉取镜像docker pull elasticsearch:6.2.4#创建容器docker create --name elasticsearch --net host -e "discovery.type=single- node" -e"network.host=192.168.254.120" elasticsearch:6.2.4#启动docker start elasticsearch#查看日志docker logs elasticsearch
Head插件安装
head插件主要用途
- elasticsearch-head是一个用来浏览、与Elastic Search簇进行交互的web前端展示插件。
- elasticsearch-head是一个用来监控Elastic Search状态的客户端插件。
- elasticsearch主要有以下三个主要操作:
- 簇浏览,显示簇的拓扑并允许你执行索引(index)和节点层面的操作。
- 查询接口,允许你查询簇并以原始json格式或表格的形式显示检索结果。
- 显示簇状态,有许多快速访问的tabs用来显示簇的状态。
- 支持Restful API接口,包含了许多选项产生感兴趣的结果,包括:
- ① 请求方式:get、put、post、delete;json请求数据,节点node,路径path。
- ② JSON验证器。
- ③ 定时请求的能力。
- ④ 用javascript表达式传输结果的能力。
- ⑤ 统计一段时间的结果或该段时间结果比对的能力。
- ⑥ 以简单图表的形式绘制传输结果。
安装
- 下载node,并解压
# 下载nodejs,head插件运行依赖nodewget https://npm.taobao.org/mirrors/node/v14.13.0/node-v14.13.0-linux-x64.tar.xz# 解压tar -xf node-v14.13.0-linux-x64.tar.xz -C /usr/apps/
- 配置profile:
[root@centos102 apps]# vim /etc/profile# 将node的路径添加到path中export NODE_HOME=/usr/apps/node-v14.13.0-linux-x64export PATH=$PATH:${NODE_HOME}/bin# 刷新配置[root@centos102 apps]# source /etc/profile[root@centos102 apps]# node -vv14.13.0 - 下载 head 插件
# 下载wget https://github.com/mobz/elasticsearch-head/archive/master.zip# 解压unzip master.zip
- 配置淘宝镜像加速
npm install -g cnpm --registry=https://registry.npm.taobao.org# 进入head插件解压目录,执行安装命令[root@centos102 elasticsearch-head-master]# npm start> elasticsearch-head@0.0.0 start /usr/apps/elasticsearch-head-master> grunt serverRunning "connect:server" (connect) taskWaiting forever...Started connect web server on http://localhost:9100
运行
# 启动head插件npm start
- 访问:

- 启用cors跨域支持:当head插件访问es时,必须在elasticsearch中启用CORS,否则您的浏览器将拒绝跨域。
# 在elasticsearch配置中增加:http.cors.enabled: true# 还必须设置,http.cors.allow-origin因为默认情况下不允许跨域。http.cors.allow-origin: "*" 是允许配置的,但由于这样配置的任何地方都可以访问,所以有安全风险。http.cors.allow-origin: "*"
- 再次访问head插件:

LogStash安装
LogStash介绍
- Logstash是一个具有实时管道的开源数据收集引擎。可以动态地统一不同来源的数据,并将数据归到不同目的地。也是一个管理事件和日志工具。你可以用它来收集日志,分析它们,并将它们储存起来以供以后使用。
- Logstash 通常都是和 Kibana 以及 Elasticsearch 一起使用。
- 文档:
LogStash安装
- 下载并解压
# 注意版本和elasticsearch,kibana 必须保持一致wget https://artifacts.elastic.co/downloads/logstash/logstash-7.2.0.tar.gz # 解压tar -zxvf logstash-7.2.0.tar.gz -C /usr/apps
- 启动与使用:
# 基本的 intput output# stdin stdout 输入输出插件./logstash -e 'input{ stdin{} } output{ stdout{} }'# codec./logstash -e 'input{ stdin{} } output{ stdout{ codec => json } }'# 日志内容写入elasticsearch./logstash -e 'input{ stdin{} } output{ elasticsearch{hosts => ["192.168.254.120:9200"]} }'# 日志内容写入elasticsearch,同时输出# 注意elasticsearch插件的语法格式:hosts 对应数组./logstash -e 'input{ stdin{} } output{ elasticsearch{hosts => ["192.168.254.120:9200"]} stdout{} }' -e:设置启动参数
input、output:是logstash的插件 stdin{}:等待输入插件 stdout{}:输出日志插件 codec:编码创建



LogStash相关插件
input插件
- 输入比较常见的几个插件:stdin、file、http、tcp
| Plugin | Description | Github repository |
|---|---|---|
| stdin | Reads events from standard input | |
| file | Streams events from files | |
| http | Receives events over HTTP or HTTPS | |
| tcp | Reads events from a TCP socket |
output插件
- 输入比较常见的几个插件:stdin、file、http、tcp
| Plugin | Description | Github repository |
|---|---|---|
| stdout | Prints events to the standard output | |
| file | Writes events to files on disk | |
| http | Sends events to a generic HTTP or HTTPS endpoint | |
| tcp | Writes events over a TCP sockett |
- 把日志内容输出到elasticsearch插件:
| Plugin | Description | Github repository |
|---|---|---|
| elasticsearch | Stores logs in Elasticsearch |
codec插件
- Codec(Code Decode)Plugin作用于input和output plugin,负责将数据在原始与Logstash之间转换,常见的codec有:
- plain:读取原始内容
- dots:将内容简化为点进行输出
- rubydebug:将内容按照ruby格式输出,方便调试 line 处理带有换行符的内容
- json:处理json格式的内容
- multiline:处理多行数据的内容
LogStash配置
创建配置
- 在config目录下创建 logstash.conf 配置文件:

配置语法
- logstash.conf 配置:
input { stdin { } }output { elasticsearch { hosts => ["192.168.254.120:9200"] } stdout { codec => rubydebug }} - 启动:
bin/logstash -f config/logstash.conf
File日志收集
- file.conf配置:
# 建立新的配置文件mv logstash.conf file.conf# 详细配置如下:input { file { path => "/var/log/messages" # 收集messages文件日志 type => "system" start_position => "beginning" # 记录上次收集的位置 }}output { elasticsearch { hosts => ["192.168.254.120:9200"] # 写入elasticsearch的地址 index => "system-%{+YYYY.MM.dd}" # 定义索引的名称 } stdout { codec => rubydebug }} - 启动:
bin/logstash -f config/file.conf
Java日志收集
- 在原来file文件的基础上进行编辑
input { file { path => "/var/log/messages" type => "system" start_position => "beginning" } # 加一个file文件收集日志插件,收集elasticsearch日志、es就是java语言开发的。 file { path => "/usr/apps/elasticsearch-7.2.0/logs/yw-es.log" type => "es-info" start_position => "beginning" }}output { if [type] == "system" { elasticsearch { hosts => ["192.168.254.120:9200"] index => "system-%{+YYYY.MM.dd}" } } # 判断,导入到不同的索引库,否则会放入同一个索引库中 if [type] == "es-info" { elasticsearch { hosts => ["192.168.254.120:9200"] index => "es-info-%{+YYYY.MM.dd}" } } stdout { codec => rubydebug }} - 问题:目前导入日志都是按照行导入的、但是有些日志多行是一句话,如果分开的话,就不太容查看日志的完整的意思了。

- 解决方案:可以使用codec来进行解决,codec把多行日志:
input { file { path => "/var/log/messages" type => "system" start_position => "beginning" } file { path => "/usr/apps/elasticsearch-7.2.0/logs/yw-es.log" type => "es-info" start_position => "beginning" # 使用正则表达式,合并多行日志 codec => multiline { pattern => "^\[" # 发现中括号,就合并日志 negate => true what => "previous" } }}output { if [type] == "system" { elasticsearch { hosts => ["192.168.254.120:9200"] index => "system-%{+YYYY.MM.dd}" } } if [type] == "es-info" { elasticsearch { hosts => ["192.168.254.120:9200"] index => "es-info-%{+YYYY.MM.dd}" } } stdout { codec => rubydebug }} 项目日志
- 配置如下:
input { tcp { port => 9600 codec => json }}output { elasticsearch { hosts => ["192.168.254.120:9200"] index => "yw-log-%{+YYYY.MM.dd}" } stdout { codec => rubydebug }} Kibana安装
Kibana插件介绍
- kibana 插件提供了Marvel监控的UI界面。
- kibana是一个与elasticsearch一起工作的开源的分析和可视化的平台。使用kibana可以查询、查看并与存储在elasticsearch索引的数据进行交互操作。使用kibana能执行高级的数据分析,并能以图表、表格和地图的形式查看数据。 kibana使得理解大容量的数据变得非常容易。它非常简单,基于浏览器的接口使我们能够快速的创建和分享显示elasticsearch查询结果实时变化的仪表盘。
Kibana下载安装
- 下载并解压:
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.2.0-linux-x86_64.tar.gztar -zxvf kibana-7.2.0-linux-x86_64.tar.gz -C /usr/apps/elasticsearch/
- 修改配置文件:
cd /usr/apps/elasticsearch/kibana-7.2.0-linux-x86_64/vim config/kibana.yml
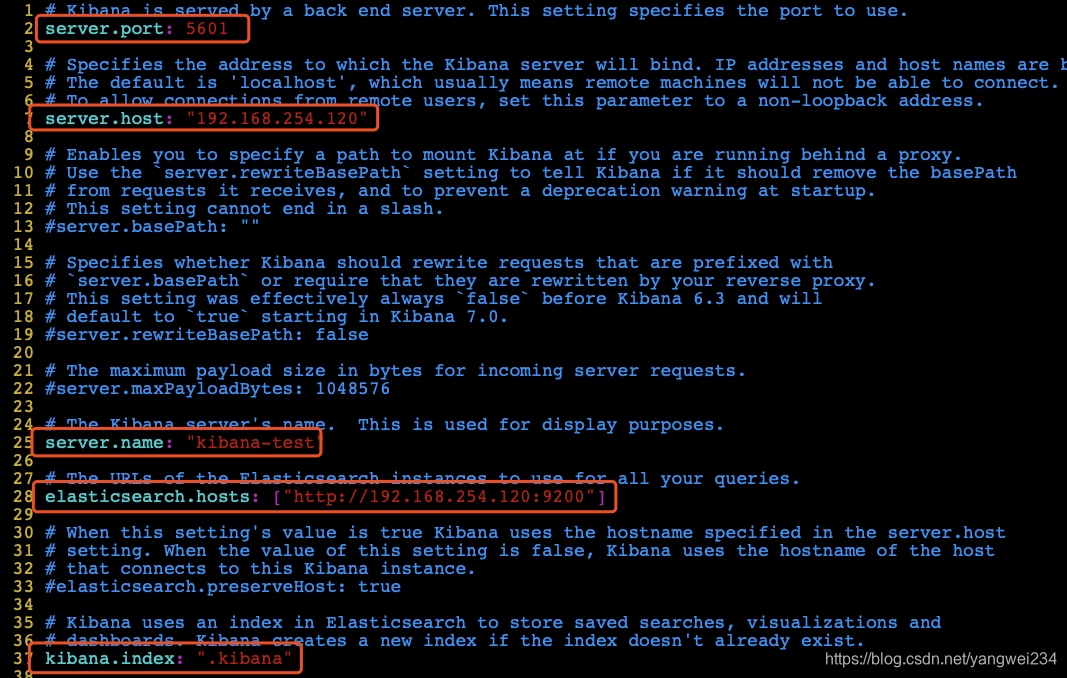
- 启动:注意,kibana同样不能在 root 下启动
[root@localhost kibana-7.2.0-linux-x86_64]# chown -R yangwei:yangwei ./# 启动./bin/kibana# 后台启动./bin/kibana &

- 访问一下:http://192.168.254.120:5601

日志视图
- 创建日志:



- 日志展示:

可视化数据
- 在Visualize应用程序中,你可以使用各种图表、表格和地图等来塑造数据,你将创建可视化效果:饼图、柱状图、坐标图和Markdown小部件等。

- 创建好了后保存

- 在Dashboard添加视图模块


分词器
下载分词器,并解压到 ElasticSearch 安装目录下的 plugins 目录
ik分词器
- 下载:
[root@localhost ik]# pwd/usr/apps/elasticsearch/elasticsearch-7.2.0/plugins/ik[root@localhost ik]# wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.2.0/elasticsearch-analysis-ik-7.2.0.zip
拼音分词器
- 下载:
[root@localhost pinyin]# pwd/usr/apps/elasticsearch/elasticsearch-7.2.0/plugins/pinyin[root@localhost pinyin]# wget https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v7.2.0/elasticsearch-analysis-pinyin-7.2.0.zip
测试
- 重启 ElasticSearch,利用 kibana 可视化界面的开发者工具进行测试
- simple分词器,测试语句:
POST /_analyze { "analyzer": "simple", "text": "我是一个程序员,咿呀咿呀哟!" } 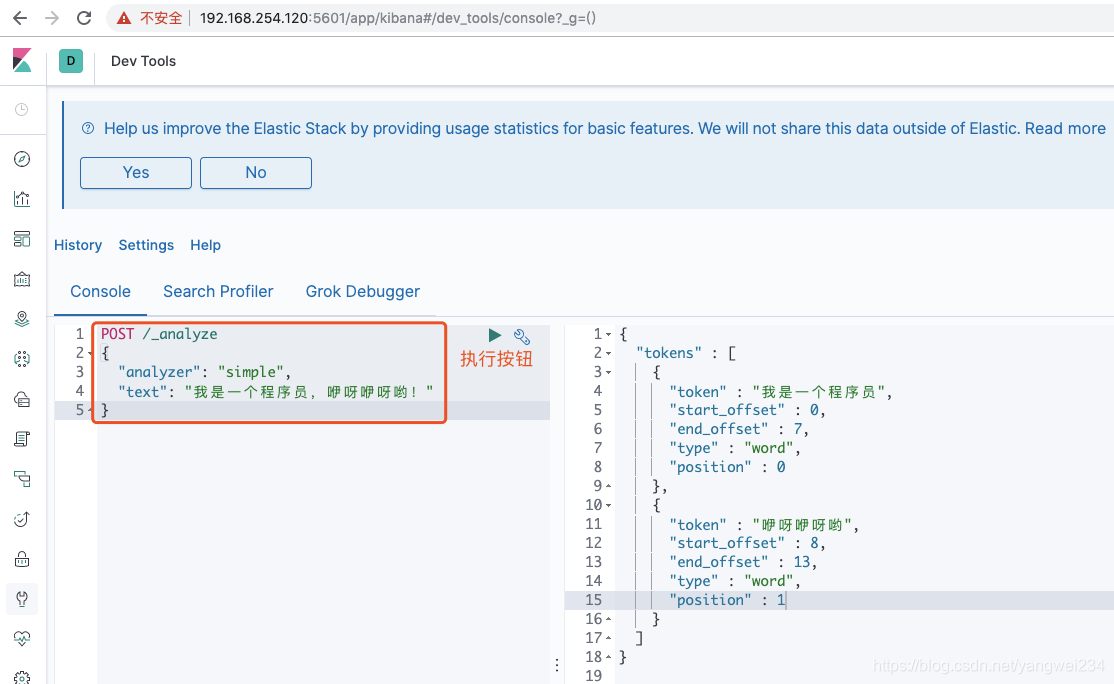
- ik 分词器,测试语句:
POST /_analyze { "analyzer": "ik_smart", "text": "我是一个程序员,咿呀咿呀哟!"} 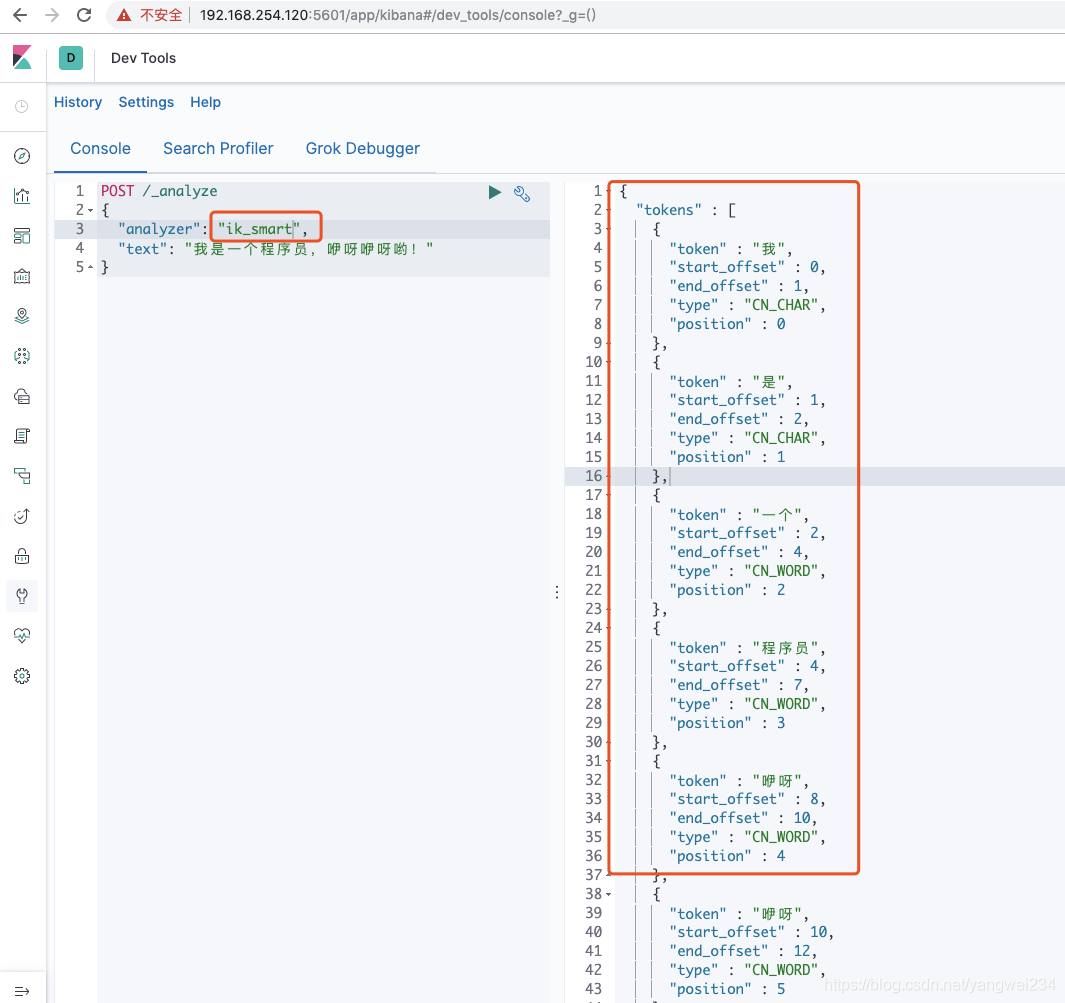
- pinyin 分词器,测试语句:
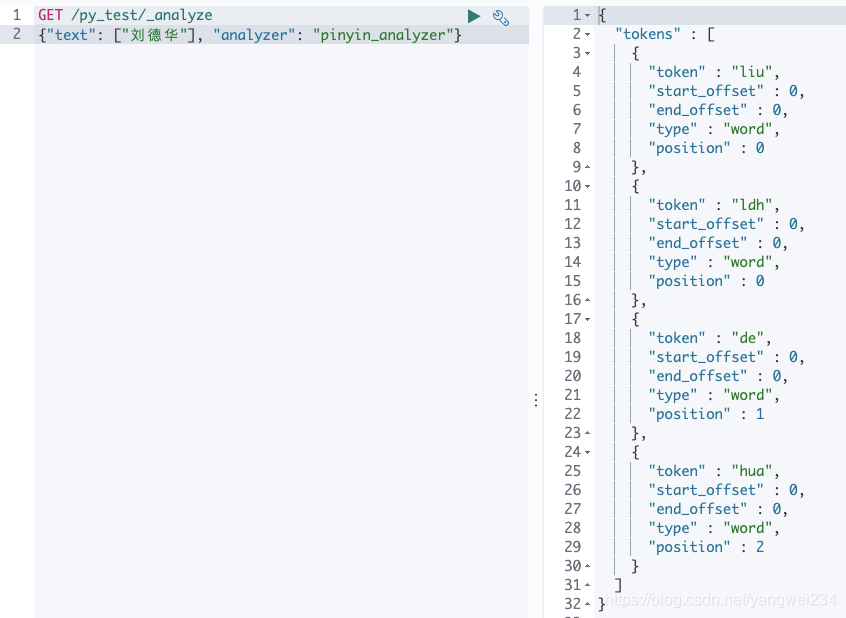
# 先创建索引PUT py_test{ "settings": { "index": { "analysis": { "analyzer": { "pinyin_analyzer": { "tokenizer": "my_pinyin", "filter": "word_delimiter" } }, "tokenizer": { "my_pinyin": { "type": "pinyin", "first_letter": "none", "padding_char": " " } } } } }}# 测试GET /py_test/_analyze { "text": ["刘德华"], "analyzer": "pinyin_analyzer"} 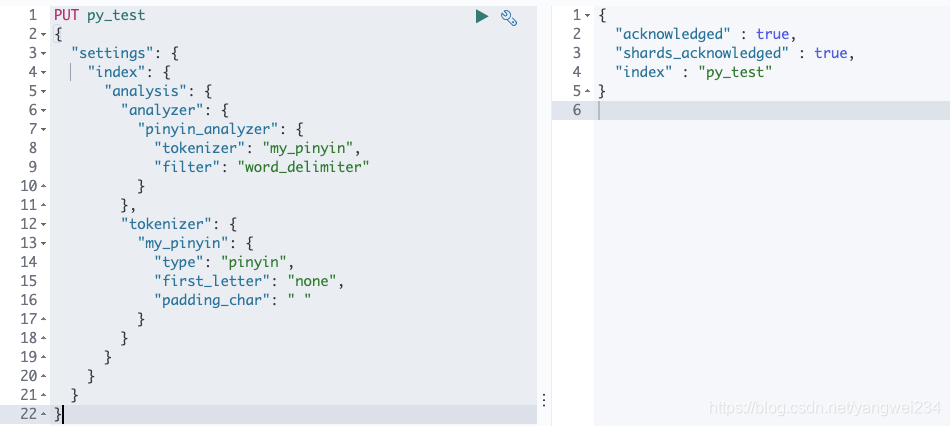
集群搭建
- 安装的版本:elasticsearch-7.2.0
- 该版本不用安装 JDK,其自带了 OpenJDK12.0.1
- 配置文件中,集群发现有改动
- 配置:
192.168.254.120 node-0192.168.254.102 node-1192.168.254.104 node-2
集群配置
- 修改配置文件 elasticsearch.yml:
# ES集群名称cluster.name: yw-es# 当前ES节点名称,每个节点的名称不能相同node.name: node-0# 设置外网访问,默认配置外网无法访问network.host: 192.168.254.120# 端口http.port: 9200# 集群节点列表discovery.seed_hosts: ["192.168.254.120", "192.168.254.102", "192.168.254.104"]# 设置集群可以选举的主节点cluster.initial_master_nodes: ["node-0", "node-1", "node-2"]
# ES集群名称cluster.name: yw-es# 当前ES节点名称,每个节点的名称不能相同node.name: node-1# 设置外网访问,默认配置外网无法访问network.host: 192.168.254.102# 端口http.port: 9200# 集群节点列表discovery.seed_hosts: ["192.168.254.120", "192.168.254.102", "192.168.254.104"]# 设置集群可以选举的主节点cluster.initial_master_nodes: ["node-0", "node-1", "node-2"]
# ES集群名称cluster.name: yw-es# 当前ES节点名称,每个节点的名称不能相同node.name: node-2# 设置外网访问,默认配置外网无法访问network.host: 192.168.254.104# 端口http.port: 9200# 集群节点列表discovery.seed_hosts: ["192.168.254.120", "192.168.254.102", "192.168.254.104"]# 设置集群可以选举的主节点cluster.initial_master_nodes: ["node-0", "node-1", "node-2"]
- 启动集群:启动各个ES结点
集群状态检查
http://192.168.254.120:9200/_cat/health?v

- 或者在kibana上查看
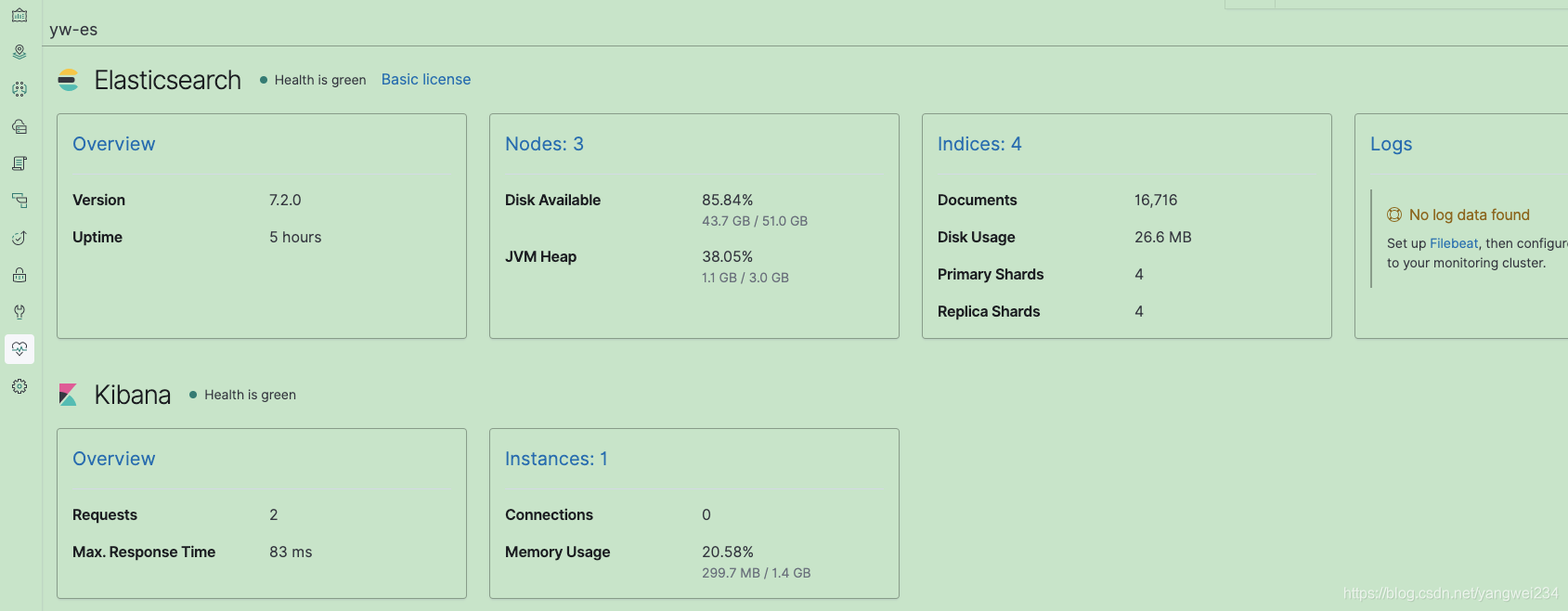
ElasticStack

- ElasticStack(ELK) = elasticsearch+Logstash+kibana
- elasticsearch:后台分布式存储以及全文检索;logstash:日志加工、“搬运工”;kibana:数据可视化展示。
- ELK架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。 三者相互配合,取长补短,共同完成分布式大数据处理工作。
创建项目
- 定义SpringBoot工程logstash-demo
- 引入依赖:
net.logstash.logback logstash-logback-encoder 5.2
代码实现
- 控制器:
@Slf4j@RestControllerpublic class LogController { @RequestMapping("/hello") public Object sayHello(String name) { log.debug("开始执行sayHello方法"); log.info("hello:" + name); log.debug("sayHello方法执行完毕"); return "OK"; }} - 配置文件:
server: port: 8080# 加载日志文件logging: config: classpath:logback-spring.xml
- 日志配置:
192.168.254.104:9600
测试
- logstash配置文件:
input { tcp { port => 9600 codec => json }}output { elasticsearch { hosts => ["192.168.254.120:9200"] index => "server-log-%{+YYYY.MM.dd}" } stdout { codec => rubydebug }} - 访问:http://localhost:8080/hello?name=zhangsan

转载地址:https://blog.csdn.net/yangwei234/article/details/96577075 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
不错!
[***.144.177.141]2024年04月03日 00时45分43秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
java设计模式-装饰器模式(包装模式)
2019-04-29
java设计模式-外观模式
2019-04-29
MapStruct使用和原理分析
2019-04-29
八分钟了解缓存的常见问题?
2019-04-29
percona-toolkit常用命令
2019-04-29
ocp的运维操作
2019-04-29
ob集群安装部署相关
2019-04-29
ob简易版合设部署
2019-04-29
ob运维相关
2019-04-29
分区表碎片整理(move)
2019-04-29
sec_case_sensitive_logon
2019-04-29
drop索引是否进回收站的测试
2019-04-29
偶数个FailGroup注意事项
2019-04-29
STK支持的地图服务
2019-04-29
error C2872: 'ifstream' : ambiguous symbol
2019-04-29
error C2065: 'cin' : undeclared identifier
2019-04-29
SOAP开启
2019-04-29
移动web页面测试
2019-04-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 309220152 位访客
访问时间: 2024-04-30 03:38:31
访问IP: 18.188.218.184
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版