本文共 5668 字,大约阅读时间需要 18 分钟。
不使用zookeeper的kafka集群
前言
大名鼎鼎的Kafka作为最出名的消息处理中间件,Zookeeper在其中提供一致性服务,并且承担了选主、服务发现、服务注册、存储各种Kafka的各种元数据。
随着Kafka的演进,Kafka自己也变成了一个复杂的分布式系统,它和zookeeper一样,都对外提供一致性服务。Kafka在其系统内再维护一套zookeeper分布式系统,这本身就是个吃力不讨好的工作,更别提zookeeper的各种问题、限制和瓶颈。所以,Kafka的开发者提出了,将zookeeper踢出Kakfa系统,Kafka自己负责管理各种信息、数据。文章还起了个致敬祖师爷的标题:Apache Kafka Made Simple
开发者管这个新的模式叫Kafka Raft Metadata mode,简称KRaft。我猜他们也发现了,zab比起paxos,还是更像raft吧:) 该模式的已经提交到Kafka分支中,预计将发布在Kakfa 2.8版本中。
ZooKeeper的缺点
Kafka想淘汰zookeeper这个事情也不是一时兴起的,社区的开发者们早就一直到zookeeper多少成为了整个系统的瓶颈,限制了集群的扩展能力。笔者去年也苦受zookeeper的折磨,下面我就列举几个常见的问题:
- Zab协议自身的限制导致了zookeeper的很多瓶颈,比如,单leader瓶颈,切主时服务不可用、系统存储的内容有限,可扩展性不足等等。
- 另外zookeeper集群的一致性模型也并没有想象中完美,不提一些违背一致性的bug如,其本身的机制:更新操作都要forward给leader,读操作follower节点可以独立进行,就决定了zookeeper的一致性保证只能做到
“Updates from a client will be applied in the order that they were sent”
- 另外zookeeper集群的一致性模型也并没有想象中完美,不提一些违背一致性的bug如,其本身的机制:更新操作都要forward给leader,读操作follower节点可以独立进行,就决定了zookeeper的一致性保证只能做到
- 身为一个分布式系统,本身就免不了有许多bug,Kakfa系统内部使用一个不属于自己维护的共识系统,发生问题了维护不方便。有很多论文调查、研究分布式系统历史上出现的各种bug,我列举了几篇放在参考链接3-5
- zookeeper本身限制也导致了客户端的访问方式、处理事件的方式等等处处掣肘,客户端不管其上层承载的业务模型是怎样的,都要按照zookeeper的filesystem/trigger API去操作。
著名的zookeeper客户端库Curator专门总结了使用Zookeeper的,我选择一些重要的翻译如下:
- 所有的watcher事件都应该在同一个线程里执行,然后再这个线程里对访问的资源加锁(这个操作应该由zk库在zk线程里自己完成)
- 认真对待session生命周期,如果expired就需要重连,如果session已经expired了,所有与这个session相关的操作也应该失败。session和临时节点是绑定的,session expired了临时节点也就没了
- zookeeper可以把sessionid和password保存起来,下次新建连接的时候可以直接用之前的
- zookeeper不适合做消息队列,因为
- zookeeper有1M的消息大小限制
- zookeeper的children太多会极大的影响性能
- znode太大也会影响性能
- znode太大会导致重启zkserver耗时10-15分钟
- zookeeper仅使用内存作为存储,所以不能存储太多东西。
- 最好单线程操作zk客户端,不要并发,临界、竞态问题太多
- Curator session 生命周期管理:
CONNECTED:第一次建立连接成功时收到该事件READONLY:标明当前连接是read-only状态SUSPENDED:连接目前断开了(收到KeeperState.Disconnected事件,也就是说curator目前没有连接到任何的zk server),leader选举、分布式锁等操作遇到SUSPENED事件应该暂停自己的操作直到重连成功。Curator官方建议把SUSPENDED事件当作完全的连接断开来处理。意思就是把收到SUSPENDED事件的时候就当作自己注册的所有临时节点已经掉了。LOST:如下几种情况会进出LOST事件- curator收到zkserver发来的EXPIRED事件。
- curator自己关掉当前zookeeper session
- 当curator断定当前session被zkserver认为已经expired时设置该事件。在Curator 3.x,Curator会有自己的定时器,如果收到SUSPENDED事件一直没有没有收到重连成功的事件,超时一定时间(2/3 * session_timeout)。curator会认为当前session已经在server侧超时,并进入LOST事件。
RECONNECTED:重连成功
对于何时进入LOST状态,curator的:
When Curator receives a KeeperState.Disconnected message it changes its state to SUSPENDED (see TN12, , etc.). As always, our recommendation is to treat SUSPENDED as a complete connection loss. Exit all locks, leaders, etc. That said, since 3.x, Curator tries to simulate session expiration by starting an internal timer when KeeperState.Disconnected is received. If the timer expires before the connection is repaired, Curator changes its state to LOST and injects a session end into the managed ZooKeeper client connection. The duration of the timer is set to the value of the “negotiated session timeout” by calling ZooKeeper#getSessionTimeout().
The astute reader will realize that setting the timer to the full value of the session timeout may not be the correct value. This is due to the fact that the server closes the connection when 2/3 of a session have already elapsed. Thus, the server may close a session well before Curator’s timer elapses. This is further complicated by the fact that the client has no way of knowing why the connection was closed. There are at least three possible reasons for a client connection to close:
- The server has not received a heartbeat within 2/3 of a session
- The server crashed
- Some kind of general TCP error which causes a connection to fail
In situtation 1, the correct value for Curator’s timer is 1/3 of a session - i.e. Curator should switch to LOST if the connection is not repaired within 1/3 of a session as 2/3 of the session has already lapsed from the server’s point of view. In situations 2 and 3 however, Curator’s timer should be the full value of the session (possibly plus some “slop” value). In truth, there is no way to completely emulate in the client the session timing as managed by the ZooKeeper server. So, again, our recommendation is to treat SUSPENDED as complete connection loss.
curator默认使用100%的session timeout时间作为SUSPENDED到LOST的转换时间,但是用户可以根据需求配置为33%的session timeout以满足上文所说的情况的场景
可见,使用好zookeeper不是一件容易的事,笔者使用zookeeper的过程中也曾遇到以下问题:
- zk session 处理
- 忽略了connecting事件,client与server心跳超时之后没有将选主服务及时下线掉,导致双主脑裂。
- 多个线程处理zk的连接状态,导致产生了多套zk线程连接zkserver。
- zk超时时间不合理,导致重连频率太高,打爆zkserver。
- 所有的zkserver全部重置(zk server全部状态被重置),这种情况下客户端不会受到expired事件,我之前实现的客户端也不会重新去建立zk session。导致之前的zkclient建立的session全部不可用,陷入无限重连而连不上的窘境。
- 多线程竞态
- zk客户端自己的线程do_completion会调用watcher的回调函数,和业务线程产生竞争,导致core dump。
- 客户端同步api
- 同步API没有超时时间,如果zkserver状态不对,发送给zkserver的rpc得不到回应,会导致调用同步zk API的线程阻塞卡死。
- 供业务使用的api设计不当,导致初始化时调用的同步版本api造成死锁。
Kakfa Without ZooKeeper简介
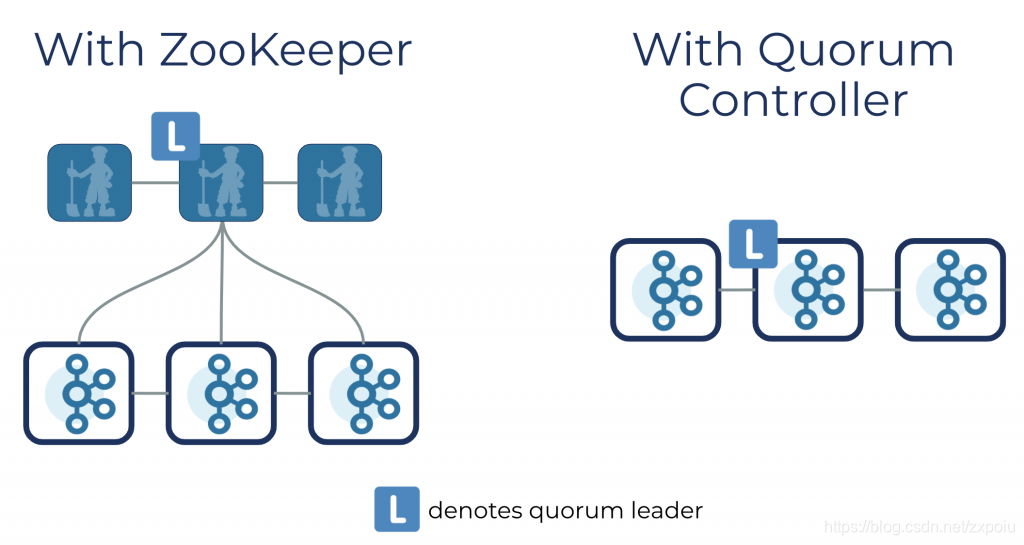
kafka将其引入的共识协议称为Event-driven consensus,controller节点内部维护RSM(replicated state machine),而不像之前的zookeeper-based,节点需要首先访问zookeeper获取状态信息。Kafka的元数据会通过raft一致性协议写入quorum,并且系统会定期做snapshot。
不同于之前的Kafka集群,唯一的Controller从所有的brker中选出,负责Watch Zookeeper、partition的replica的集群分配,以及leader切换选举等流程。KRaft中Controller可以被指定为奇数个节点(一般情况下3或5)组成raft quorum。controller节点中有一个active(选为leader),其他的hot standby。这个controller集群负责管理Kafka集群的元数据,通过raft协议达成共识。因此,每个controller都拥有几乎update-to-date的Metadata,所以controller集群重新选主时恢复时间很短。

集群的其他节点通过配置选项controller.quorum.voters获取controller。不同于之前的模式,controller发送Metadata给其他的broker。现在broker需要主动向active controller拉取Metadata。一旦broker收到Metadata,它会将其持久化。这个broker持久化Metadata的优化意味着一般情况下active controller不需要向broker发送完整的Metadata,只需要从某个特定的offset发送即可。但如果遇到一个新上线的broker,Controller可以发送snapshot给broker(类似raft的InstallSnapshot RPC)。
Kakfa Without ZooKeeper的优势
- 减少了服务配置的复杂度,不再需要通过去配置zookeeper来协调Kafka。整个系统也变得更轻量级了
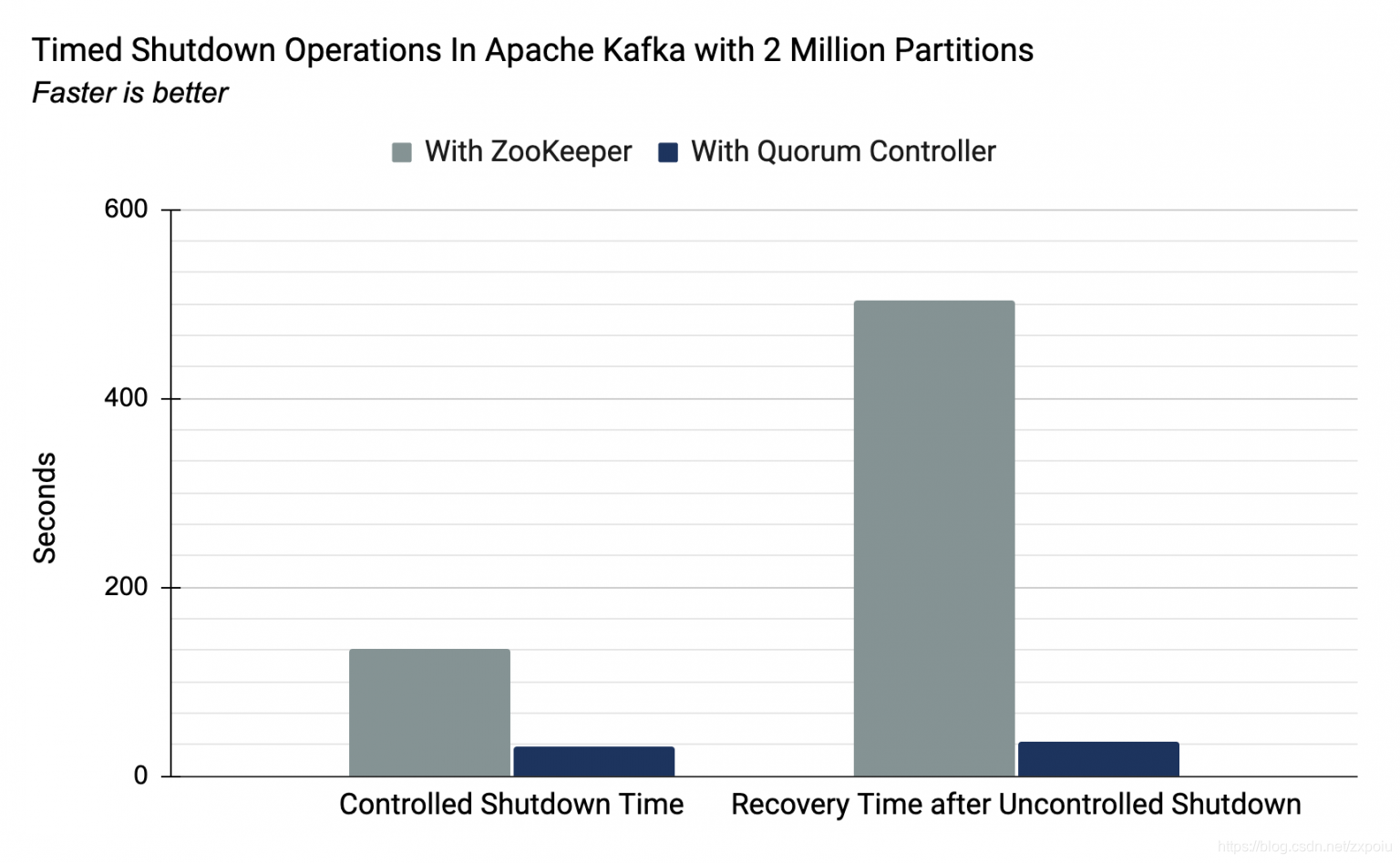
- 摆脱了之前提到的zookeeper种种限制,系统的可拓展性大大增强了,号称可支持百万partition。并且系统的节点启动和关闭时间和之前先比也大大降低了。
总结
Kakfa Without ZooKeeper是维护者对Kafka做出的一大创举,但是目前仅出于EA阶段,很多功能还不完善,并且一个分布式系统需要经历很多的迭代、bugfix,才能稳定下来,这都需要时间。但笔者认为这个方向是正确的,这是任何一个互联网系统发展到一定阶段必然会面对的问题。
参考链接
转载地址:https://blog.csdn.net/zxpoiu/article/details/115665451 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
