本文共 3411 字,大约阅读时间需要 11 分钟。
Windows Azure Storage论文解读
WAS是微软开发的云存储系统,提供Blob、Table、Queue三种类型的服务,它广泛部署于微软内部。其发表于2011年SOSP。
整体架构
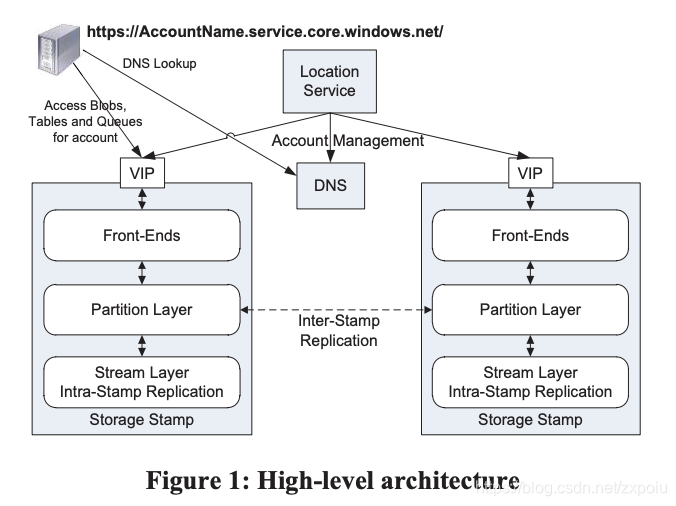
WAS主要分为两个部分:定位服务(Location Service LS)和存储区(Storage Stamp)
- 定位服务管理用户到存储区之间的映射,负责负载均衡,并且服务跨地域、高可用
- 存储区分为三层:
- 文件流层(
stream layer):处理底层的文件存储,分布式replication、管理extent等等,可以看做是存储引擎。 - 分区层(
Partition Layer):访问文件流层获取文件,对上层提供blob、table、queue服务。 - 前端层(
Front-End Layer):由一些列无状态的web服务器组成,接受请求完成验证之后,转发到partition layer。
- 文件流层(
因为WAS跨存储区,所以其使用了两种复制方式:
- Intra-Stamp Replication:在一个stamp内,使用synchronous replication保证强一致。每个成功的写操作必须保证所有的副本都同步成功。
- Inter-Stamp Replication:垮stamp使用asynchronous replication,异步复制,实现异地容灾。
文件流层 stream layer
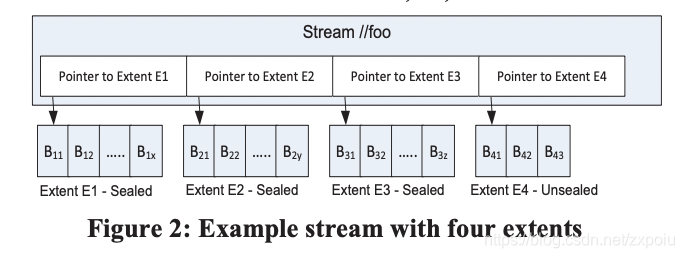
文件流层提供类似文件系统的命名空间和API,所有的写操作只能是追加。文件流层中的文件称为流(streams)。每个流包含一系列的extent,每个extent由多个block组成。
block是独具读写的最小单位。每个block最大不超过4M。stream layer会对block计算checksum。读取操作总是给定某个block的边界。每次读取都会检查checksum。系统后台也会每隔一段时间校验block的checksum。
extent是文件流层数据复制、负载均衡的基本单位,每个extent有三个副本。每个extent默认1GB,如果存储大对象,就会用很多个extent。
stream layer有一个stream manager,负责监控extent存储节点,管理文件到extent的映射关系,垃圾回收、负载均衡等等。通过paxos实现高可用。
存储引擎
WAS中的流文件只允许追加,不允许更改。追加操作是原子的,数据追加到Block中,客户端可以缓存多个请求之后一次提交给stream layer,客户端需要保证幂等性重试。
对于追加产生的重复数据,WAS这样处理:
- 对于元数据和log,通过他们的事务编号(transaction sequence)去重。
- 对于行数据流(row data streams):只有最后一个追加成功的会被索引,之前重复的会被垃圾回收。
WAS的追加流程如下:
- 如果客户端没有缓存需要的extent信息,或者extent已经被sealed(缝合)了,客户端向steam manager请求获取extent
- SM通过一定的策略,如负载均衡、副本分配等,分配一定数量的extent到存储节点EN(extent node),其中一个extent是主副本(这种方式写时才分配三副本,SM可以根据当前系统的状态动态调整新的部分的位置,并且不需要像GFS那样主chunk需要维持lease)
- 客户端知道主副本之后,将请求发送到主副本,主副本执行以下操作:
- 决定追加的数据块在extent中的位置
- 定序:如果有多个客户端向同一个extent并发追加,主副本需要确定追加顺序(元数据索引)(不知道这个确定顺序会不会有瓶颈,毕竟1G也比较大了)
- 将数据块写入主副本
- 主副本将请求发送给备副本,备副本链式转发给其他备副本,其他的备副本按照主副本确定的顺序追加写入。
- 备副本写成功后回应主副本
- 如果所有的主副本都成功,主副本应答客户端追加成功。
- 追加过程中如果某副本出现错误,客户端追加请求会失败,这时候客户端会联系SM,SM根据当前集群状况,首先seal失败的extent,然后创建新的extent用来提供追加请求。SM处理副本故障的平均时间在20ms左右,新的extent创建成功之后,追加操作可以继续。WAS通过这种错误处理的方式,实现强一致。
每个extent副本都维护了已经提交的数据长度(commit length),如果出现异常,每个副本当前的长度可能不一致,SM缝合时首先选择获取所有副本的commit length,如果副本之间不一致,SM将选择最小的长度作为缝合长度,如果某副本出现异常,等该节点重启之后,其上的extent会从其他节点上同步数据。
文件流层保证以下两点:
- 只要记录被猪价并成功相应客户端,从任何一个副本都能读取到相同的数据。
- 即使追加过程中出现故障,一旦extent被缝合,从任何一个被缝合的副本中都能读到相同的数据。
存储优化
extent存储面临两大问题:
- 如何保证磁盘调度公平
- 避免磁盘随机写操作
WAS的优化点如下:
- 如果SM发现某个存储节点的IO被阻塞时间超过100ms,则将新的请求调度到其他存储节点。
- 由于一个存储节点(磁盘)有很多个extent,不同extent的并发追加会导致磁盘出现很多随机写,降低写性能。因此存储节点采用单独的日志盘(journal drive),存储节点收到的追加请求会顺序的写入日志盘,然后针对同一个extent文件的多个连续写入合并成一个写操作,再真正落盘
- 通过EC(Erasure coding),将extent中的数据条带化落盘。这个和HDFS类似。
分区层 Partition Layer
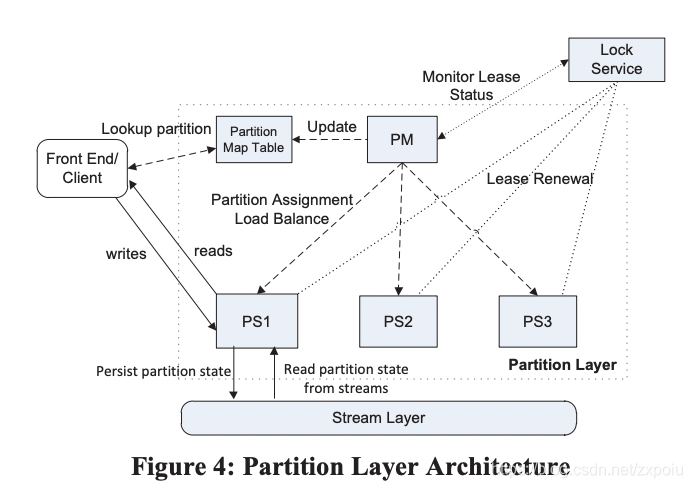
分区层建立在文件流层之上,用于提供Table、Blob、Queue等数据服务。分区层的一个重要特性是提供强一致性并保证事务操作顺序。
分区层内部支持一种成为对象表(Object Table,OT)的数据结构,用来存储对象到extent的映射,OT被动态的划分为多个连续的范围(RangePartition,对应Bigtable的子表),并分散到不同的Partition Server上,范围区间不想不重叠。另外,分区层中还有一张全局的Schema表(Schema Table),保证所有的对象表格的shema信息,即每个OT包含的每个列的名字、数据类型以及属性。这些表是持久化到存储区的。
通过这种方式,WAS支持了很多的数据类型,包括:bool、binary string、DataTime、duoble、GUID、int32、int64、DictionaryType、BlobType。
Partition Layer也存在Partition Server和Partition Master,Partition Master通过Lock Service选主。每个PS与Lock Service之间存在Lease,如果PS出现故障,PM需要首等待PS上的Lease过期,才能将他原来的服务分配出去。
存储引擎
WAS分区层中的操作与Bigtable基本类似。用户的写操作首先追加到操作日志(commit log strema)中,接着修改内存表(memory table),等到内存表达到一定大小之后,执行快照(checkpoint),PS还会将多个小快照合并成一个大快照(对应Bigtable中的minor/major compaction),并且PS上会缓存数据,还会有布隆过滤器优化读请求。也存在负载均衡和分区的分裂与合并。
与Bigtable不同点如下:
- WAS中每个分区有都有对应的commit log文件,而bigtable中,每个Tablet Server上的所有子表共享一个操作日志文件。
- WAS中每个分区维护各自的元数据,PM只负责管理每个分区之间的关系。而bigtable通过根表(root table)和元数据表(meta table),将所以的元数据统一在一起。
- WAS中存储类型较多,从数值到blob都支持。
WAS总结
WAS整体架构借鉴GFS+Bigtable,并有所创新:
- WAS使用1G的extent从而减少元数据
- WAS保证每个副本之间的强一致性
- WAS将范围分区的操作写到不同的操作日志中。
转载地址:https://blog.csdn.net/zxpoiu/article/details/115701356 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
