本文共 2517 字,大约阅读时间需要 8 分钟。
主要来源:视频学习网站
L₂ 正则化
请查看以下泛化曲线,该曲线显示的是训练集和验证集相对于训练迭代次数的损失。
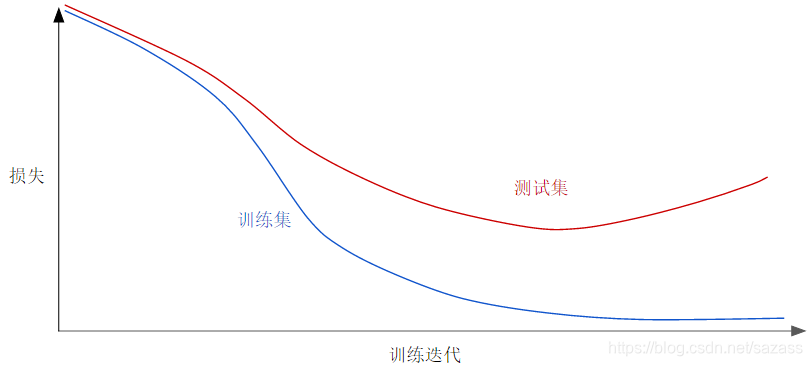 上图显示的是某个模型的训练损失逐渐减少,但验证损失最终增加。换言之,该泛化曲线显示该模型与训练集中的数据过拟合。 根据奥卡姆剃刀定律,或许我们可以通过降低复杂模型的复杂度来防止过拟合,这种原则称为正则化。 也就是说,并非只是以最小化损失(经验风险最小化)为目标:
上图显示的是某个模型的训练损失逐渐减少,但验证损失最终增加。换言之,该泛化曲线显示该模型与训练集中的数据过拟合。 根据奥卡姆剃刀定律,或许我们可以通过降低复杂模型的复杂度来防止过拟合,这种原则称为正则化。 也就是说,并非只是以最小化损失(经验风险最小化)为目标: 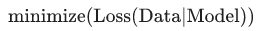 而是以最小化损失和复杂度为目标,这称为结构风险最小化:
而是以最小化损失和复杂度为目标,这称为结构风险最小化:  现在,我们的训练优化算法是一个由两项内容组成的函数:一个是损失项,用于衡量模型与数据的拟合度,另一个是正则化项,用于衡量模型复杂度。
现在,我们的训练优化算法是一个由两项内容组成的函数:一个是损失项,用于衡量模型与数据的拟合度,另一个是正则化项,用于衡量模型复杂度。 介绍两种衡量模型复杂度的常见方式:
将模型复杂度作为模型中所有特征的权重的函数。 将模型复杂度作为具有非零权重的特征总数的函数。如果模型复杂度是权重的函数,则特征权重的绝对值越高,对模型复杂度的贡献就越大。
我们可以使用 L2 正则化公式来量化复杂度,该公式将正则化项定义为所有特征权重的平方和: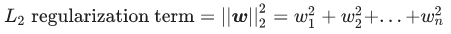 在这个公式中,接近于 0 的权重对模型复杂度几乎没有影响,而离群值权重则可能会产生巨大的影响。 例如,某个线性模型具有以下权重:
在这个公式中,接近于 0 的权重对模型复杂度几乎没有影响,而离群值权重则可能会产生巨大的影响。 例如,某个线性模型具有以下权重: 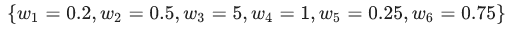 L2 正则化项为 26.915:
L2 正则化项为 26.915:  但是 w3(上述加粗内容)的平方值为 25,几乎贡献了全部的复杂度。所有 5 个其他权重的平方和对 L2 正则化项的贡献仅为 1.915。
但是 w3(上述加粗内容)的平方值为 25,几乎贡献了全部的复杂度。所有 5 个其他权重的平方和对 L2 正则化项的贡献仅为 1.915。 正则化率(Lambda)
模型开发者通过以下方式来调整正则化项的整体影响:用正则化项的值乘以名为 lambda(又称为正则化率)的标量。也就是说,模型开发者会执行以下运算:
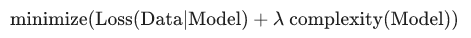 执行 L2 正则化对模型具有以下影响
执行 L2 正则化对模型具有以下影响 使权重值接近于 0(但并非正好为 0) 使权重的平均值接近于 0,且呈正态(钟形曲线或高斯曲线)分布。
增加 lambda 值将增强正则化效果。 例如,lambda 值较高的权重直方图可能会如下图所示:
 降低 lambda 的值往往会得出比较平缓的直方图,如下图所示:
降低 lambda 的值往往会得出比较平缓的直方图,如下图所示: 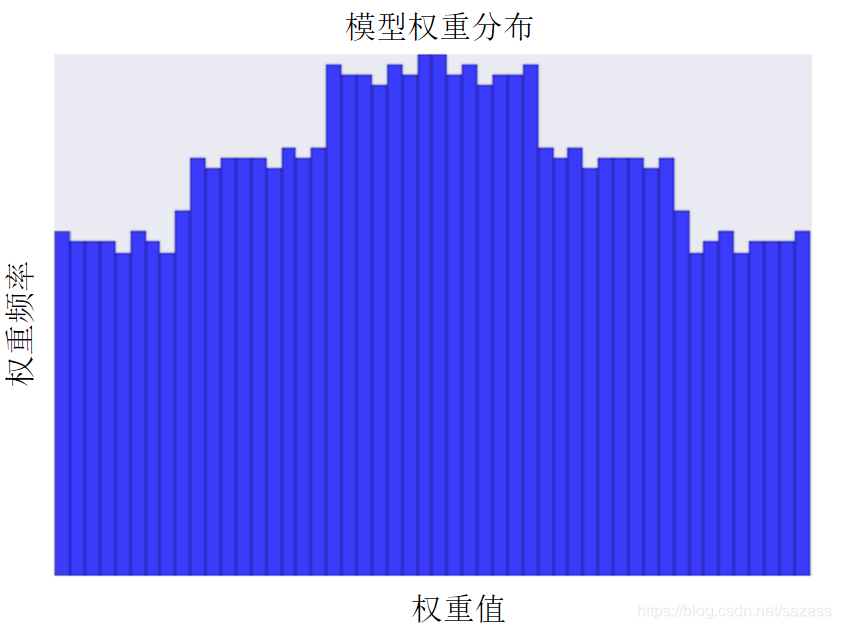 在选择 lambda 值时,目标是在简单化和训练数据拟合之间达到适当的平衡: 1.如果您的 lambda 值过高,则模型会非常简单,但是您将面临数据欠拟合的风险。您的模型将无法从训练数据中获得足够的信息来做出有用的预测。 2.如果您的 lambda 值过低,则模型会比较复杂,并且您将面临数据过拟合的风险。您的模型将因获得过多训练数据特点方面的信息而无法泛化到新数据。
在选择 lambda 值时,目标是在简单化和训练数据拟合之间达到适当的平衡: 1.如果您的 lambda 值过高,则模型会非常简单,但是您将面临数据欠拟合的风险。您的模型将无法从训练数据中获得足够的信息来做出有用的预测。 2.如果您的 lambda 值过低,则模型会比较复杂,并且您将面临数据过拟合的风险。您的模型将因获得过多训练数据特点方面的信息而无法泛化到新数据。 注意:将 lambda 设为 0 可彻底取消正则化。 在这种情况下,训练的唯一目的将是最小化损失,而这样做会使过拟合的风险达到最高。
关于正则化率的实验:
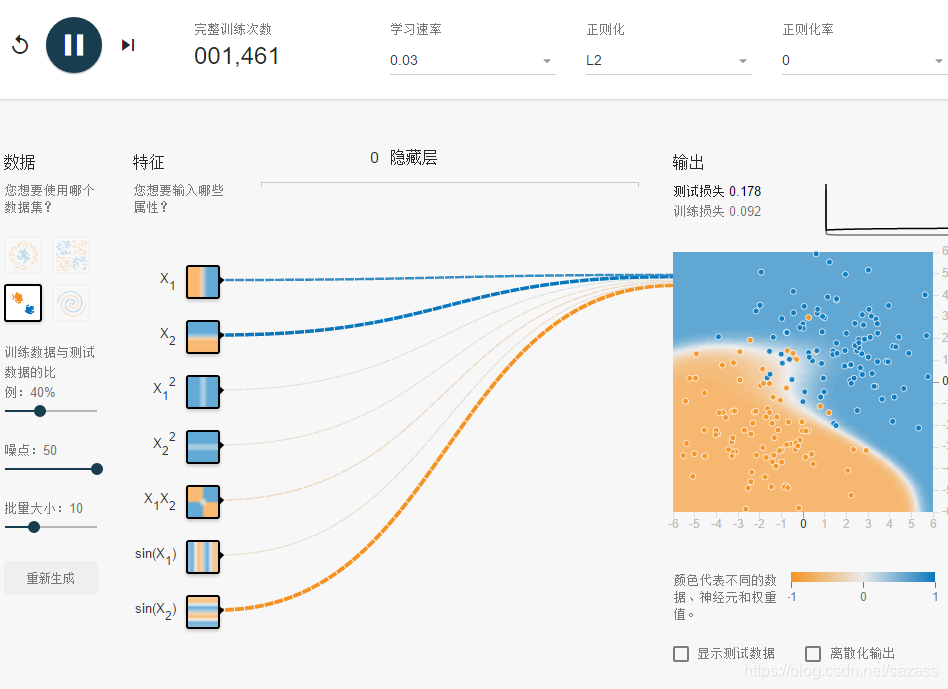
正则化率为0时,随着训练次数的不断增加,训练损失会不断增大,出现过拟合现象:
 当正则化率从0增加到0.3时: 测试损失明显减少; 测试损失与训练损失之间的差值明显减少; 特征和某些特征组合的权重的绝对值较低,这表示模型复杂度有所降低; 。
当正则化率从0增加到0.3时: 测试损失明显减少; 测试损失与训练损失之间的差值明显减少; 特征和某些特征组合的权重的绝对值较低,这表示模型复杂度有所降低; 。 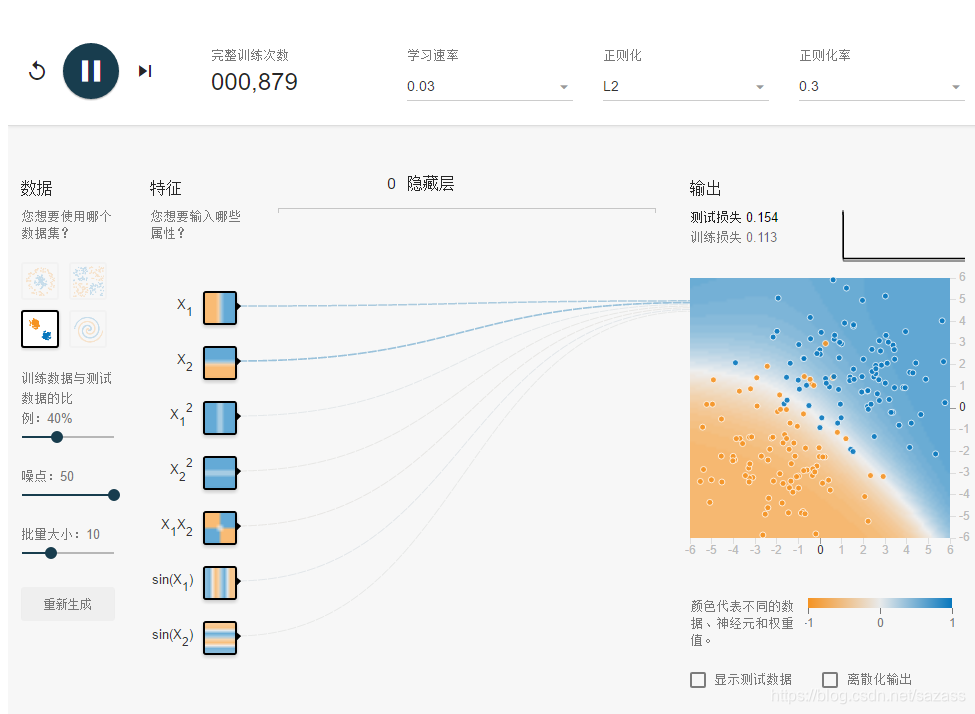 注意:虽然测试损失明显减少,训练损失实际上却有所增加。这属于正常现象,因为您向损失函数添加了另一项来降低复杂度。最终,最重要的是测试损失,因为它是真正用于衡量模型能否针对新数据做出良好预测的标准。
注意:虽然测试损失明显减少,训练损失实际上却有所增加。这属于正常现象,因为您向损失函数添加了另一项来降低复杂度。最终,最重要的是测试损失,因为它是真正用于衡量模型能否针对新数据做出良好预测的标准。 由于数据集具有随机性,因此无法预测哪个正则化率能得出最准确的结果。 对我们来说,正则化率为 0.3 或 1 时,一般测试损失降至最低。
L1正则化
稀疏矢量通常包含许多维度。创建特征组合会导致包含更多维度。由于使用此类高维度特征矢量,因此模型可能会非常庞大,并且需要大量的 RAM。
在高维度稀疏矢量中,最好尽可能使权重正好降至 0。正好为 0 的权重基本上会使相应特征从模型中移除。 将特征设为 0 可节省 RAM 空间,且可以减少模型中的噪点。
以一个涵盖全球地区(不仅仅只是涵盖加利福尼亚州)的住房数据集为例。如果按分(每度为 60 分)对全球纬度进行分桶,则在一次稀疏编码过程中会产生大约 1 万个维度;如果按分对全球经度进行分桶,则在一次稀疏编码过程中会产生大约 2 万个维度。这两种特征的特征组合会产生大约 2 亿个维度。这 2 亿个维度中的很多维度代表非常有限的居住区域(例如海洋里),很难使用这些数据进行有效泛化。 若为这些不需要的维度支付 RAM 存储费用就太不明智了。 因此,最好是使无意义维度的权重正好降至 0,这样我们就可以避免在推理时支付这些模型系数的存储费用。
我们或许可以添加适当选择的正则化项,将这种想法变成在训练期间解决的优化问题。
L2 正则化能完成此任务吗?遗憾的是,不能。 L2 正则化可以使权重变小,但是并不能使它们正好为 0.0。L1 正则化具有凸优化的优势,可有效进行计算。因此,我们可以使用 L1 正则化使模型中很多信息缺乏的系数正好为 0,从而在推理时节省 RAM。
L1 和 L2 正则化比较
L2 和 L1 采用不同的方式降低权重:
L2 会降低权重的平方。 L1 会降低权重的绝对值。因此,L2 和 L1 具有不同的导数:
L2 的导数为 2 * 权重。 L1 的导数为 k(一个常数,其值与权重无关)。可以将 L2 的导数的作用理解为每次移除权重的 x%。如 Zeno 所知,对于任意数字,即使按每次减去 x% 的幅度执行数十亿次减法计算,最后得出的值也绝不会正好为 0。(Zeno 不太熟悉浮点精度限制,它可能会使结果正好为 0。)总而言之,L2 通常不会使权重变为 0。
可以将 L1 的导数的作用理解为每次从权重中减去一个常数。不过,由于减去的是绝对值,L1 在 0 处具有不连续性,这会导致与 0 相交的减法结果变为 0。例如,如果减法使权重从 +0.1 变为 -0.2,L1 便会将权重设为 0。就这样,L1 使权重变为 0 了。
L1 正则化 - 减少所有权重的绝对值 - 证明对宽度模型非常有效。
请注意,该说明适用于一维模型。
凸优化 (convex optimization)
使用数学方法(例如梯度下降法)寻找凸函数最小值的过程。机器学习方面的大量研究都是专注于如何通过公式将各种问题表示成凸优化问题,以及如何更高效地解决这些问题。转载地址:https://chenlinwei.blog.csdn.net/article/details/87296803 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
