本文共 1844 字,大约阅读时间需要 6 分钟。
主要来源:视频学习网站
逻辑回归 (logistic regression):一种模型,通过将 S 型函数应用于线性预测,生成分类问题中每个可能的离散标签值的概率。虽然逻辑回归经常用于二元分类问题,但也可用于多类别分类问题(其叫法变为多类别逻辑回归或多项回归)。
许多问题需要将概率估算值作为输出。逻辑回归是一种极其高效的概率计算机制。实际上,您可以通过下两种方式之一使用返回的概率:
“按原样” 转换成二元类别(简单介绍)二元分类 (binary classification):一种分类任务,可输出两种互斥类别之一。例如,对电子邮件进行评估并输出“垃圾邮件”或“非垃圾邮件”的机器学习模型就是一个二元分类器。
我们来了解一下如何“按原样”使用概率。假设我们创建一个逻辑回归模型来预测狗在半夜发出叫声的概率。我们将此概率称为: p(bark | night)
如果逻辑回归模型预测 p(bark | night) 的值为 0.05,那么一年内,狗的主人应该被惊醒约 18 次: startled = p(bark | night) * nights 18 ~= 0.05 * 365您可能想知道逻辑回归模型如何确保输出值始终落在 0 和 1 之间。巧合的是,S 型函数生成的输出值正好具有这些特性,其定义如下:
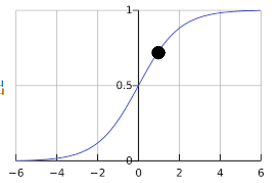
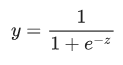 S 型函数会产生以下曲线图:
S 型函数会产生以下曲线图: 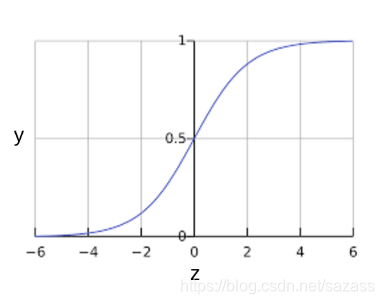 如果 z 表示使用逻辑回归训练的模型的线性层的输出,则 S 型(z) 函数会生成一个介于 0 和 1 之间的值(概率)。用数学方法表示为:
如果 z 表示使用逻辑回归训练的模型的线性层的输出,则 S 型(z) 函数会生成一个介于 0 和 1 之间的值(概率)。用数学方法表示为: 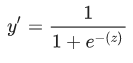 其中: y’ 是逻辑回归模型针对特定样本的输出。 z 是 b + w1x1 + w2x2 + … wNxN w 的值是该模型学习的权重,b 是偏差。 x 的值是特定样本的特征值。
其中: y’ 是逻辑回归模型针对特定样本的输出。 z 是 b + w1x1 + w2x2 + … wNxN w 的值是该模型学习的权重,b 是偏差。 x 的值是特定样本的特征值。 注意,z 也称为对数几率,因为 S 型函数的反函数表明,z 可定义为标签“1”(例如“狗叫”)的概率除以标签“0”(例如“狗不叫”)的概率得出的值的对数:
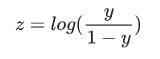
S 型函数 (sigmoid function):一种函数,可将逻辑回归输出或多项回归输出(对数几率)映射到概率,以返回介于 0 到 1 之间的值。
在逻辑回归问题中,σ 非常简单:σ=b+w1x1+w2x2+…wnxn 换句话说,S 型函数可将 σ 转换为介于 0 到 1 之间的概率。逻辑回归计算过程案例:
1.假设我们的逻辑回归模型具有学习了下列偏差和权重的三个特征:
b = 1 w1 = 2 w2 = -1 w3 = 5进一步假设给定样本具有以下特征值:
x1 = 0 x2 = 10 x3 = 22.因此,对数几率:
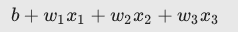 将是: (1) + (2)(0) + (-1)(10) + (5)(2) = 1
将是: (1) + (2)(0) + (-1)(10) + (5)(2) = 1 3.因此,此特定样本的逻辑回归预测值将是 0.731(73.1%概率):
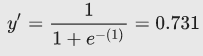
逻辑回归损失函数:
线性回归的损失函数是平方损失。逻辑回归的损失函数是对数损失函数,定义如下:
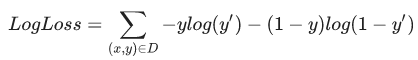 其中: (xy)ϵD 是包含很多有标签样本 (x,y) 的数据集。 y是有标签样本中的标签。由于这是逻辑回归,因此y的每个值必须是 0 或 1。 y’是对于特征集x的预测值(介于 0 和 1 之间)。
其中: (xy)ϵD 是包含很多有标签样本 (x,y) 的数据集。 y是有标签样本中的标签。由于这是逻辑回归,因此y的每个值必须是 0 或 1。 y’是对于特征集x的预测值(介于 0 和 1 之间)。 对数损失函数的方程式与 Shannon 信息论中的熵测量密切相关。它也是似然函数的负对数(假设“y”属于伯努利分布)。实际上,最大限度地降低损失函数的值会生成最大的似然估计值。
逻辑回归中的正则化
正则化在逻辑回归建模中极其重要。如果没有正则化,逻辑回归的渐近性会不断促使损失在高维度空间内达到 0。因此,大多数逻辑回归模型会使用以下两个策略之一来降低模型复杂性:
1.L2 正则化。 2.早停法,即,限制训练步数或学习速率假设您向每个样本分配一个唯一 ID,且将每个 ID 映射到其自己的特征。如果您未指定正则化函数,模型会变得完全过拟合。这是因为模型会尝试促使所有样本的损失达到 0 但始终达不到,从而使每个指示器特征的权重接近正无穷或负无穷。当有大量罕见的特征组合且每个样本中仅一个时,包含特征组合的高维度数据会出现这种情况。
幸运的是,使用 L2 或早停法可以防止出现此类问题。早停法 (early stopping):一种正则化方法,是指在训练损失仍可以继续降低之前结束模型训练。使用早停法时,您会在验证数据集的损失开始增大(也就是泛化效果变差)时结束模型训练
总结
逻辑回归模型会生成概率。
对数损失函数是逻辑回归的损失函数。 逻辑回归被很多从业者广泛使用。转载地址:https://chenlinwei.blog.csdn.net/article/details/87305467 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
