数据分析-简单实用的数据清洗代码整合
发布日期:2021-06-29 15:45:47
浏览次数:2
分类:技术文章
本文共 1385 字,大约阅读时间需要 4 分钟。
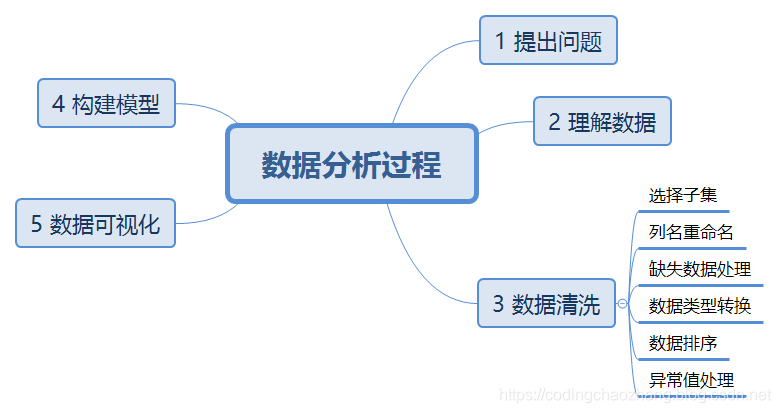
数据清洗代码整合
1 删除多列数据
有时,并不是所有列都对我们的分析有用。因此,df.drop函数是一个得心应手的工具去移除指定的列。
def drop_multiple_col(col_names_list,df): df.drop(col_names_list,axis=1,inplace=True) return df
2 改变数据类型
当一个数据集变大时,我们需要改变dtypes保存。
def change_dtypes(col_int,col_float,df): df[col_int] = df[col_int].astype("int32") df[col_float] = df[col_float].astype("float32") 3 类变量转换为数值变量
def convert_cat2num(df): num_encode = { "col_1":{ "YES":1,"NO":0},"col_2":{ "WON":1,"LOSE":0,"DRAW":0}} df.replace(num_code,inplace=True) 4 检查丢失数据
检查每列中丢失数据的数量,可以理解哪些列有多少丢失数据。
def check_missing_data(df): return df.isnull().sum().sort_values(ascending=False)
5 移除列中特殊字符串
def remove_col_str(df): # remove a portion of string in a datafram column - col_1 df['col_1'].replace('\n', '', regex=True, inplace=True) # remove all the characters after &#(including &#) for column-col_1 df['col_1'].replace(' &#.*', '', regex=True, inplace=True) 6 移除列中空格
def remove_col_white_space(df): ddf[col] = df[col].str.lstrip()
7 合并列
def concat_col_str_condition(df): mask = df["col_1"].str.endswith("pil",na=False) col_new = df[mask]["col_1"]+df[mask]["col_2"] col_new.replace("pil"," ",regex = True, inplace=True)#place the 'pil' with empty space 8 转换时间戳(string到datetime)
def convert_str_datetime(df): df.insert(loc=2,column='timestamp',value=pd.to_datetime(df.transdate, format='%Y-%m-%d %H:%M:%S.%f'))
转载地址:https://codingchaozhang.blog.csdn.net/article/details/99619824 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
路过按个爪印,很不错,赞一个!
[***.219.124.196]2024年04月22日 19时12分14秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
基于vue框架的在线问卷的设计
2019-04-29
java的酒店房间管理系统
2019-04-29
基于Java的截图工具
2019-04-29
基于JAVA的停车场管理系统
2019-04-29
基于SSM的网上购物系统的设计与开发
2019-04-29
基于SSM框架的BS微博系统的设计与实现
2019-04-29
超市订单管理系统
2019-04-29
基于ssm的民宿网站
2019-04-29
基于JavaWeb的物流管理系统的设计与实现
2019-04-29
基于Java的飞机大战游戏的设计与实现论文
2019-04-29
基于java实现的超级马里奥游戏
2019-04-29
keepalived 实现高可用,负载均衡
2019-04-29
linux发送邮件通知
2019-04-29
linux不删除文件:替换rm命令
2019-04-29
Centos6 搭建lnmp环境
2019-04-29
Hbase优化:使用压缩snappy,lz4
2019-04-29
maven 安装第三方jar包到本地仓库
2019-04-29
hbase数据结构模型
2019-04-29
Shell编程:return 返回脚本调用的状态码
2019-04-29
Hbase Shell 调用java代码:通过比较器,强过滤查询
2019-04-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 310001319 位访客
访问时间: 2024-05-02 11:45:50
访问IP: 18.224.63.87
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版