HMM中文分词_CodingPark编程公园
发布日期:2021-06-29 15:47:13
浏览次数:2
分类:技术文章
本文共 257 字,大约阅读时间需要 1 分钟。
文章介绍
新词识别OVV是中文分词一大难点,为此我们从词语级模型切换到字符级模型,将中文分词任务转换为序列标注问题。
作为新手起步,我们尝试了最简单的序列标注模型----隐马尔可夫模型HMM中文分词流程
-
映射
- 标注集:将标注集{B,M,E,S}映射为连续的整形id
- 词表:将字符映射为另一套id,
-
语料转换
我们必须把语料库转换为(x,y)二元组才能训练HMM -
训练
HMMTrainer #train -
预测
HMMSegmenter #sgment -
评价
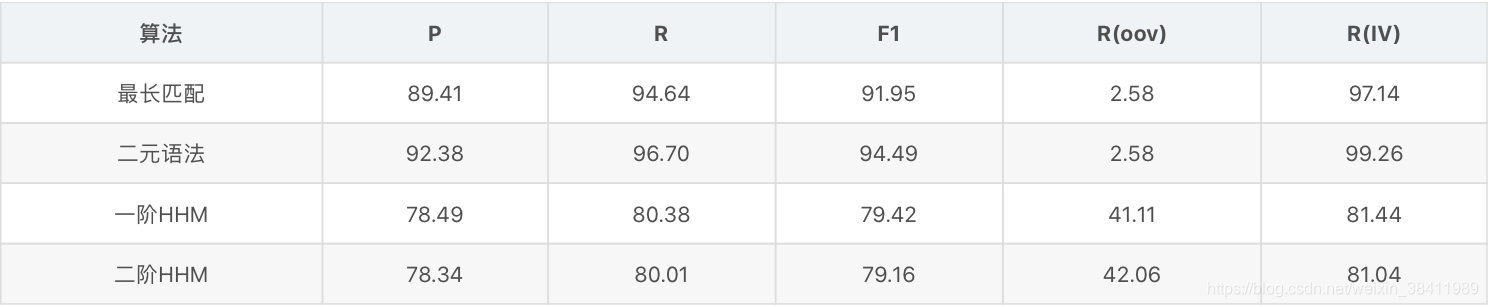
-
误差分析
一阶HMM 对比以前算法,对于一阶HMM来说
转载地址:https://codingpark.blog.csdn.net/article/details/107715590 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
能坚持,总会有不一样的收获!
[***.219.124.196]2024年04月03日 22时08分57秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
Java CompletableFuture
2019-04-29
缓存行、伪共享
2019-04-29
Redis 六种淘汰策略和三种删除策略
2019-04-29
Java LinkedHashMap
2019-04-29
PostgreSQL 关闭session链接
2019-04-29
JPA 多线程同时对一条数据进行Update的问题
2019-04-29
JPA 多线程对数据进行更新,Update和Insert同时存在的问题
2019-04-29
Java 高性能队列Disruptor
2019-04-29
SpringBoot 使用https
2019-04-29
Java 读写锁
2019-04-29
JVM Minor GC、Full GC和Major GC
2019-04-29
SpringBoot @Scheduled 执行两次的问题
2019-04-29
idea maven工程打jar包,运行出现xxx.jar中没有主清单属性的问题解决方法
2019-04-29
java 使用GDAL生产tif格式
2019-04-29
Node,js 事件循环原理(Event loop)
2019-04-29
CSS3&JavaScript 图片分隔切换
2019-04-29
CSS3&JavaScript 瀑布流
2019-04-29
tomcat配置JVM
2019-04-29
Oracle获取连接超级慢的问题
2019-04-29
关于HashMap初始化容量,设置多少合适。
2019-04-29
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 309932265 位访客
访问时间: 2024-05-02 07:16:09
访问IP: 18.116.62.45
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版