本文共 4740 字,大约阅读时间需要 15 分钟。
1、已有Seq2Seq模型
Seq2Seq模型是处理序列到序列问题的利器,尤其是在神经网络翻译(NMT)方面,取得了很大的成功。Seq2Seq由一个encoder和一个decoder构成,encoder把观测样本X编码成一个固定长度的隐变量Z,decoder再把隐变量Z解码成输出标签Y[1]。传统的Seq2Seq模型把观测样本编码成一个固定长度的隐变量Z,这个操作被认为限制了Seq2Seq模型的能力。因此,后来提出了基于attention mechanism的RNNSearch模型(Seq2Seq+attention mechanism),在decoder端,采用含一个隐含层的前向网络,采用自适应(adaptive)的方法来计算观测序列X中,每个word与输出标签Y的权重[2]。FaceBook提出了由CNN构成的Seq2Seq模型,完全采用堆叠的CNN来构建encoder和decoder,通过CNN的堆叠方式来回去sequence中long-range dependencies关系,在decoder端采用了多层的attention机制。堆叠CNN之间采用加入残差的GLU单元来连接,加快计算的同时最大限度保留输入sequence的信息[3]。
觉得不错,记得关注头条号。
2、已有Seq2Seq模型优缺点分析
传统的基于CNN或RNN的Seq2Seq模型都存在一定的不足:CNN不能直接用于处理变长的序列样本,RNN不能并行计算,效率低。虽然完全基于CNN的Seq2Seq模型可以并行实现,但非常占内存,很多的trick,大数据量上参数调整并不容易。传统的Seq2Seq模型不适用于长的句子,Seq2Seq+attention虽然提升了处理长句子的能力,但encoder解码得到隐变量Z时,任然对观测序列X的计算添加了约束。
基于Attention Mechanism + LSTM的Seq2Seq模型的优点:自适应地计算一个权值矩阵W,权重矩阵W长度与X的的词数目一致,每个权重衡量输入序列X中每个词对输入序列Y的重要程度,不需要考虑输入序列X与输出序列Y中,词与词之间的距离关系。缺点:attention mechanism通常是和RNN结合使用,但RNN依赖t-1的历史信息来计算t时刻的信息,因此不能并行实现,计算效率比较低,特别是训练样本量非常大的时候。
基于CNN的Seq2Seq+attention的优点: 基于CNN的Seq2Seq模型具有基于RNN的Seq2Seq模型捕捉long distance dependency的能力,此外,最大的优点是可以并行化实现,效率比基于RNN的Seq2Seq模型高。缺点:计算量与观测序列X和输出序列Y的长度成正比。
针对基于CNN和RNN的Seq2Seq模型存在的不足,本文提出了一种完全基于Attention Mechanism(Self Attention)的Transformer机制:抛弃CNN和RNN,基于Attention来构造encoder和decoder,搭建完全基于Attention的Seq2Seq模型。
觉得不错,记得关注头条号。
3、All Attention Seq2Seq模型基本单元分析
1)、Add & Norm(AN)单元
Add & Norm = LayerNorm(x + Sublayer(x)),Sublayer是前面部分(Multi-Head attention或FeedFoward Layer)的输出,这种连接方式有两个明显好处:
(1)、训练速度快。LayerNorm是Batch Normalization的一个变体,在之前文章《》进行了详细的讲解。简要对比下BN与LN:LN是本次输入模型的一组样本做进行Normalization,BN是对一个batch数据进行Normalization。因此,LN可以用于RNN规范化操作,但BN不行。我个人经验是:基于LN的加速比BN快8-10倍。
(2)、引入了残差,尽可能保留原始输入x的信息。
2)、Scaled Dot-Product Attention and Multi-Head Attention单元
Attention有三个输入:query,keys,values,一个输出,选择三个输入是考虑到模型的通用性(Generative)。输出是value的加权求和,value的权重来自于query和keys的乘积,经过一个softmax之后得到。可以得到scaled dot-product attention的公式(1)所示:

为什么除一个dk的根号:常用的attention机制有additive attention,简写成AA(由一个前向神经网络实现)和dot-product(multiplicative)attention,简写成DA。虽然两种方法理论上的复杂度类似,但DA实际运行速度更快且更节省内存。当dk值比较小时,两种算法效果相当,但当dk值比较大时,AA比DA要好,原因可能是DA中Q与K的点乘得到的值过大。
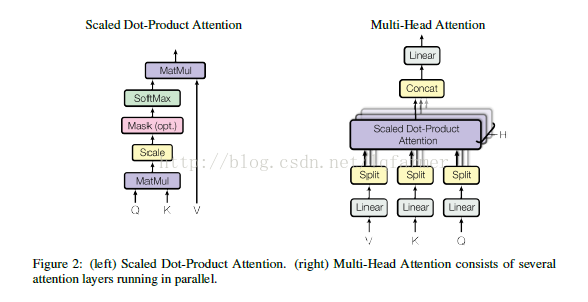
Multi-Head Attention:对输入K,V,Q,,采用不同的权重,连续进行H词Scaled Dot-Product Attention,类似于卷积网络里面采用不同的卷积核多次进行卷积操作。Multi-Head Attention可以使模型从不同的角度来获取输入X的不同subspaces representation。同时,对每个维度多了reduce,使multi=head attention总的计算量与single-head attention一致。
觉得不错,记得关注头条号。
3)、结构中逐项的feed-forward网络作用
Attention的sublayer之间嵌入一个FFN层,两个线性变换组成:FFN(x)=max(0,x*W1 + b1)W2 + b2。同层拥有相同的参数,不同层之间拥有不同的参数。目的应该是提高模型特征抽取的能力,考虑到效率,选择两个线性变换。
4)、Position Encoding
网模型的输入embedding中添加position embedding,使网络可以获得输入序列的位置(positions)之间的一个相对或者绝对位置信息。Position embedding有很多种方式获得,比如采用像word2vec方式训练。本文采用较简单的方式,基于正弦和余弦函数,根据位置pos和维度i来计算:
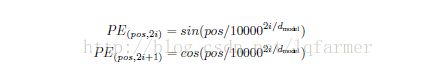
这样做的目的是因为正弦和余弦函数具有周期性,对于固定长度偏差k(类似于周期),post +k位置的PE可以表示成关于pos位置PE的一个线性变化(存在线性关系),这样可以方便模型学习词与词之间的一个相对位置关系。
4、网络整体结构分析
Transformer的每一层(layer):一个self-attention层+ 逐项的全连接层构成,通过堆叠多个层来构造encoder和decoder,网络结构如图1所示。
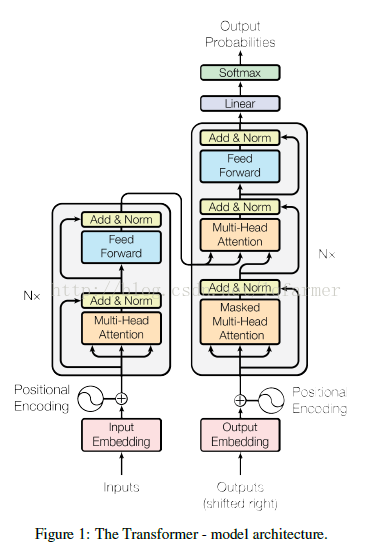
Encoder端:输入的Embedding,与Positional Embedding(后面会给出positional embedding的计算方法)相加,做为堆叠N(N=6)个完全相同的Layer层的输入。每一个Layer层由Multi-Head attention部分和一个FeedFoward部分组成,两个部分直接通过一个Add & Norm的方式连接。为了加速,模型中所有子层的输出dimension = 512。
Decoder端:decoder也是由N(N=6)个完全相同的Layer组成,decoder中的Layer由encoder的Layer中插入一个Multi-Head Attention + Add&Norm组成。输出的embedding与输出的position embedding求和做为decoder的输入,经过一个Multi-Head Attention + Add&Norm((MA-1)层,MA-1层的输出做为下一Multi-Head Attention + Add&Norm(MA-2)的query(Q)输入,MA-2层的Key和Value输入(从图中看,应该是encoder中第i(i = 1,2,3,4,5,6)层的输出对于decoder中第i(i = 1,2,3,4,5,6)层的输入)。MA-2层的输出输入到一个前馈层(FF),经过AN操作后,经过一个线性+softmax变换得到最后目标输出的概率。
觉得不错,记得关注头条号。
5、Attention机制作用分析
1)、插入decoder的中间层的MAAN结构输入:query来源于output的decoder层输出,memory的keys和values来源于对于的encoder的输出,充当权重。这一操作使得decoder可以获取输入X整个序列的信息,类似于传统Seq2Seq中的decoder端的attention机制。
2)、encoder端包含self-attention layers。当前self-attention的输入k、v,q来源于前一层的输出,encoder中每一个position可以关联前一层所有positions,可以全面获取输入序列X中positions之间依赖关系。对包含self-attention的decoder端也一样。
3)、相比基于CNN和RNN的Seq2Seq模型,基于Self-Attention的Seq2Seq模型计算效率更高,单层计算复杂度更低,学习long-range dependencies的能力更强,三种类型的Seq2Seq模型对比如下表所示:

最重要的是,基于Self-Attention的Seq2Seq网络学习long-range dependencies能力很强。Seq2Seq中的一个关键问题是如何学习sequence中的词与词之间的long-range dependencies关系。在双向LSTM(BLSTM),我们通常分正向和反向分别计算一次Sequence的信息,其中,学习long-range dependencies关键的一点是信号在网络正向和反向计算中传递的Path长度(计算次数),计算次数越多,较远的依赖关系消失情况越严重。在Self-Attention结构中,每一层都直接与前一层的所有position直接连接,因此Path的长度为O(1),最大程度保留了sequence中词与词之间的依赖关系。针对长句子,为了提高计算效率,只考虑某一个词前后r个词时,Path的路径最长长度任然只有O(n/r),其中,n为sequence长度。
6、参考文献:
[1] Sequence to Sequence Learning. Ilya Sutskever.
[2] NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE. Dzmitry Bahdanau.
[3] Convolutional Sequence to Sequence Learning. Jonas Gehring.
[4] Attention Is All You Need. Ashish Vaswani.
往期内容推荐
更多在NLP方面应用的经典论文、实践经验和最新消息,欢迎关注公众号“深度学习与NLP”或“DeepLearning_NLP”或扫描二维码添加关注。

转载地址:https://lqfarmer.blog.csdn.net/article/details/73521811 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
