【Kaggle】Intro to Machine Learning 第一次提交 Titanic

发布日期:2021-07-01 03:25:19
浏览次数:2
分类:技术文章
本文共 1454 字,大约阅读时间需要 4 分钟。
新手可以,教你如何操作、提交等
自己简要再记录一下:
- Join the competition
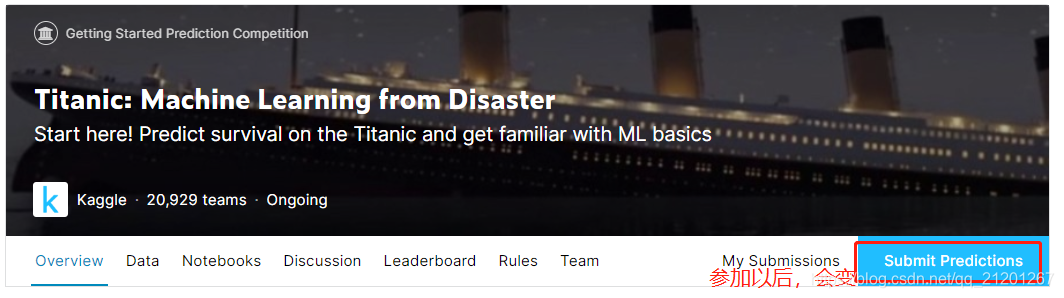 各个 tab 下可以查看数据Data、代码编写Notebooks、讨论、排名、比赛规则、队伍
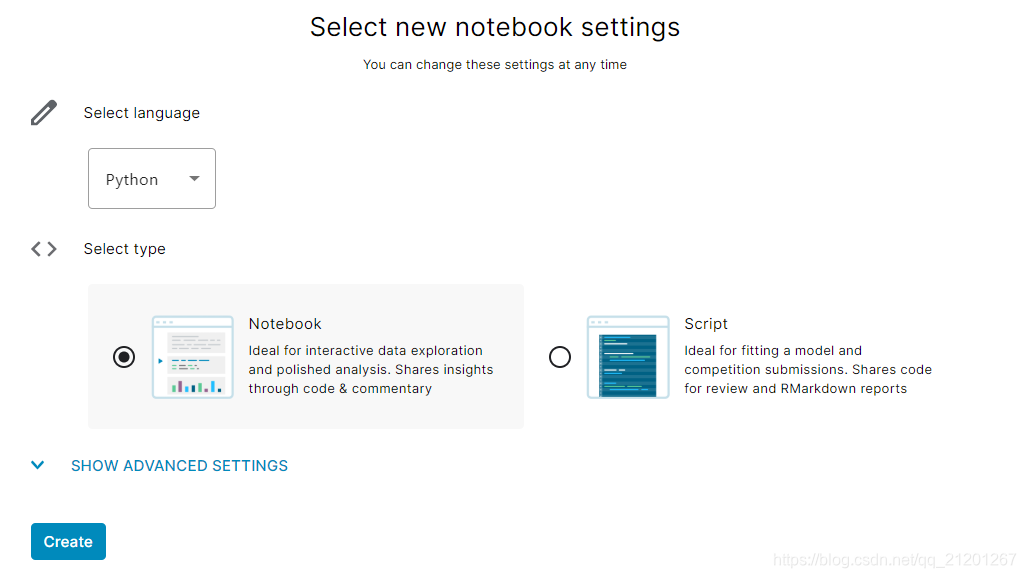
各个 tab 下可以查看数据Data、代码编写Notebooks、讨论、排名、比赛规则、队伍 - 点击 Notebooks,新建文件
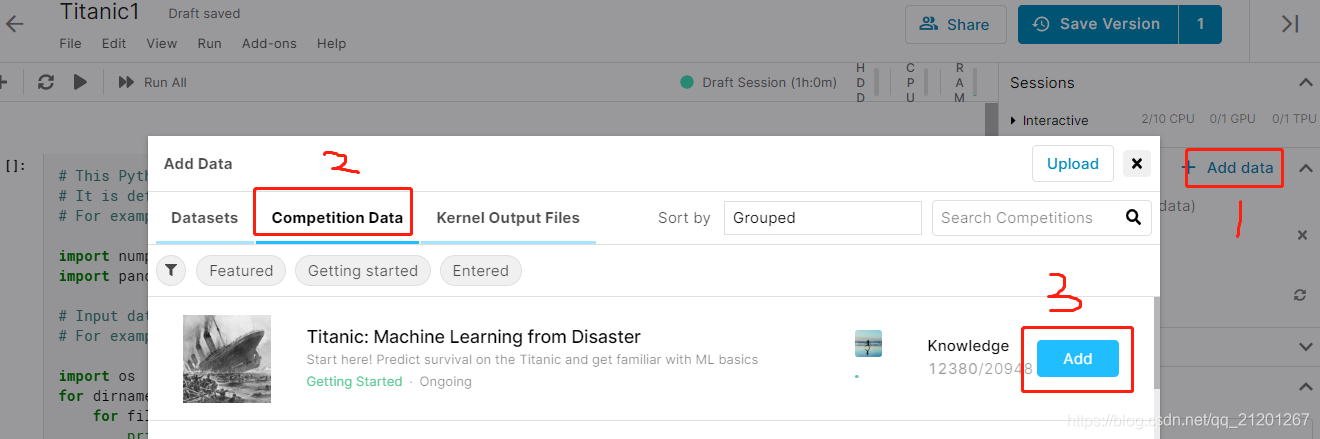
- 添加比赛数据集
- 编写代码
import numpy as np # linear algebraimport pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)import osfor dirname, _, filenames in os.walk('/kaggle/input'): for filename in filenames: print(os.path.join(dirname, filename))# 读取数据test_data = pd.read_csv("../input/titanic/test.csv")test_data.head()train_data = pd.read_csv("../input/titanic/train.csv")train_data.head()# 简要的数据查看,分析男女生存状况women = train_data.loc[train_data.Sex == 'female']["Survived"]rate_women = sum(women)/len(women)print("% of women who survived:", rate_women)men = train_data.loc[train_data.Sex == 'male']["Survived"]rate_men = sum(men)/len(men)print("% of men who survived:", rate_men)# 随机森林模型,选取4个特征from sklearn.ensemble import RandomForestClassifiery = train_data["Survived"]features = ["Pclass", "Sex", "SibSp", "Parch"]X = pd.get_dummies(train_data[features])# get_dummies编码处理X_test = pd.get_dummies(test_data[features])# 设置模型参数model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)model.fit(X, y)#训练predictions = model.predict(X_test)#预测# 输出预测文件output = pd.DataFrame({ 'PassengerId': test_data.PassengerId, 'Survived': predictions})# 写入csv文件output.to_csv('my_submission.csv', index=False)print("Your submission was successfully saved!") - 保存、运行
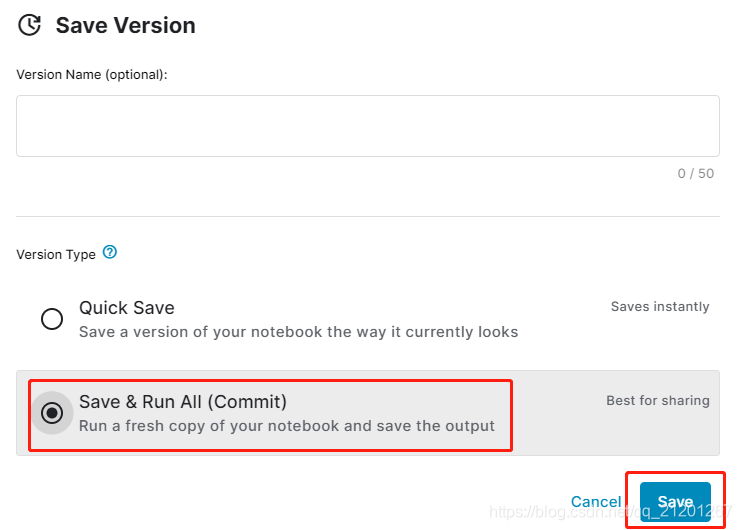

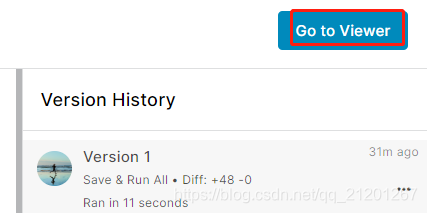 往下找到 output files
往下找到 output files 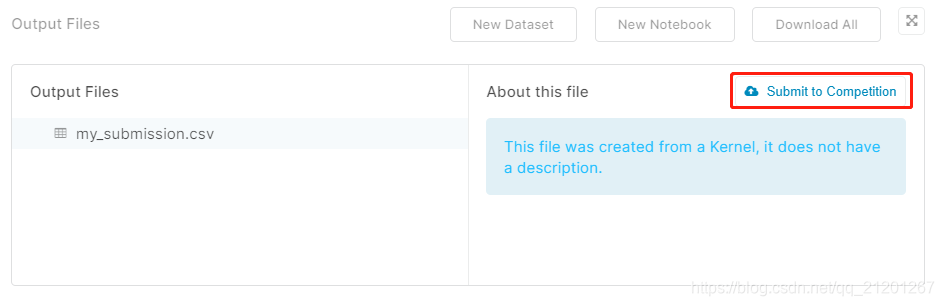
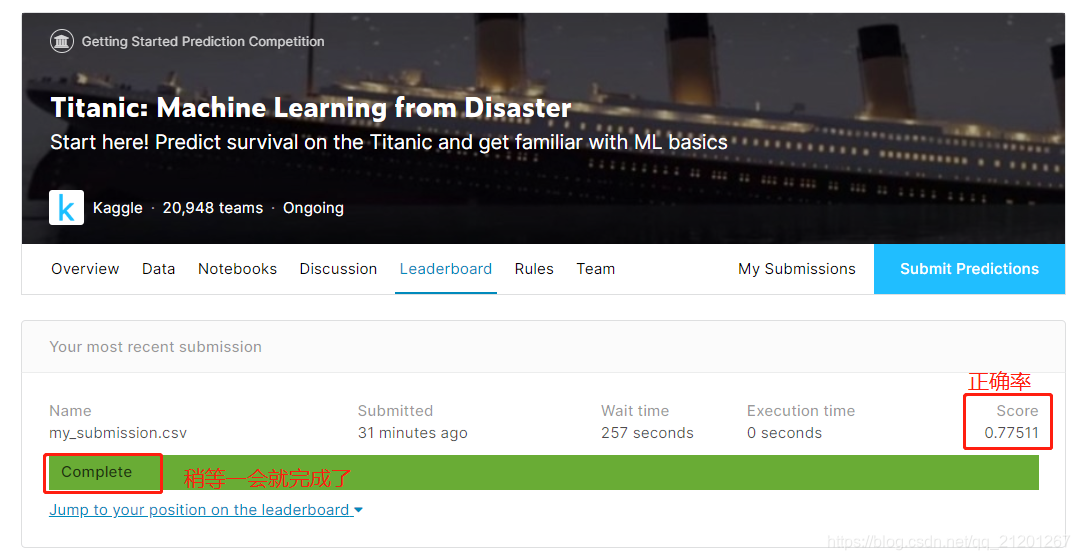
完成课程 Intro to Machine Learning,发了一张证书,哈哈,加油!
转载地址:https://michael.blog.csdn.net/article/details/106018582 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
不错!
[***.144.177.141]2024年05月03日 06时24分58秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
攻防世界web进阶区web2详解
2019-04-30
xss-labs详解(上)1-10
2019-04-30
xss-labs详解(下)11-20
2019-04-30
攻防世界web进阶区ics-04详解
2019-04-30
sql注入总结学习
2019-04-30
Linux png转jpg (convert命令)
2019-04-30
vscode git
2019-04-30
CodeForces - 456C Boredom (dp)
2019-04-30
CodeForces - 1042B Vitamins (思维)
2019-04-30
ACM 2013 长沙区域赛 Collision (几何)
2019-04-30
ACM 2014 鞍山区域赛 E - Hatsune Miku (dp)
2019-04-30
反向传播&梯度下降 的直观理解程序(numpy)
2019-04-30
ACM 2017 北京区域赛 J-Pangu and Stones(区间dp)
2019-04-30
java常用类 String面试题
2019-04-30
四线触摸屏原理
2019-04-30
C/C++如何返回一个数组/指针
2019-04-30
腾讯AI语音识别API踩坑记录
2019-04-30
java.net.BindException: 无法指定被请求的地址
2019-05-01
svn服务器安装
2019-05-01
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 311777955 位访客
访问时间: 2024-05-07 19:08:10
访问IP: 3.146.255.127
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版