关于MYSQL的Replication的初步学习
发布日期:2021-07-18 14:33:28
浏览次数:4
分类:技术文章
本文共 514 字,大约阅读时间需要 1 分钟。
简单说Replication实际上就是一种数据库间的同步机制,它通过主库上生成的二进制日志在从库上重放来实现主从库上的同步。
Replication is relatively good for scaling reads, which you can direct to a slave, but it’s not a good way to scale writes unless you design it right.
相对来说,Replication机制特别适合对读取进行水平伸缩(scale out),这也是很多系统通过Replication实现读写分离的目的。对于很多系统来说,读写比例是不对等的,很多时候是读操作要远远多于写操作,针对这种情况,通过Replication,将数据写入主库,而在读取数据时,散列到某个从库上,分散读取压力。也就是说,它为读操作实现负载均衡提供了条件。
从这一点来看,目前论坛系统的主从库设计并不能提升系统的整体性能。因为我们的写操作也是非常频繁的。这样,从库在不停地同步主库新抓取的数据时,还要被统计分析进程频繁读取,从而造成从库性能低下。
下图是Replication的工作机制:
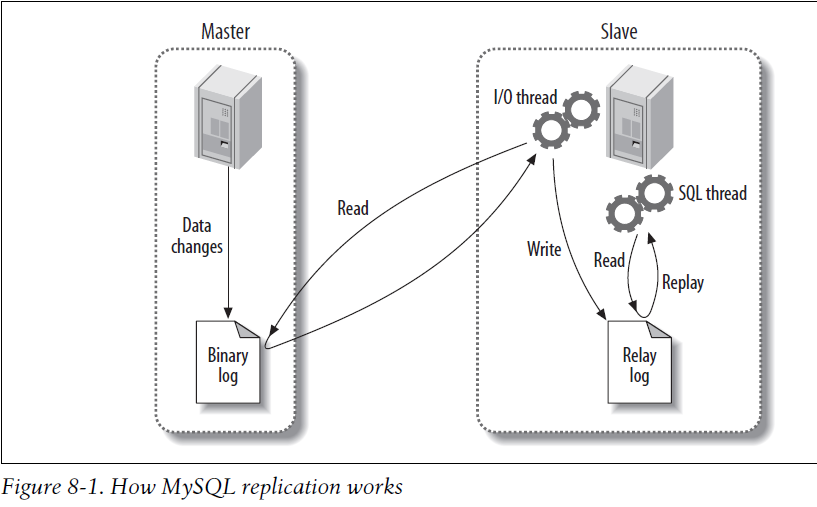
转载地址:https://blog.csdn.net/iteye_2116/article/details/81893336 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关注你微信了!
[***.104.42.241]2024年03月28日 22时59分32秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
svn提交的一个坑
2019-04-27
eclipse识别不了模拟器解决办法
2019-04-27
unity mesh合并
2019-04-27
谈谈类之间的关联关系与依赖关系
2019-04-27
unity5.x assetbundle打包和加载
2019-04-27
C#用正则表达式去匹配被双引号包起来的中文
2019-04-27
lua table排序
2019-04-27
Unity发布的ios包在iphone上声音是从听筒里出来的问题
2019-04-27
UIScrollView复用节点示例
2019-04-27
Unity 5 AudioMixer
2019-04-27
Unity 代码混淆: CodeGuard的使用
2019-04-27
UGUI 列表循环使用
2019-04-27
使用命令行运行unity并执行某个静态函数(运用于命令行打包和批量打包)
2019-04-27
web.py框架
2019-04-27
web.py学习笔记
2019-04-27
python的代码缩进
2019-04-27
A* Pathfinding Project (Unity A*寻路插件) 使用教程
2019-04-27
bash学习笔记
2019-04-27
sqlite学习
2019-04-27
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 308065818 位访客
访问时间: 2024-04-26 14:35:32
访问IP: 18.191.189.85
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版