本文共 1317 字,大约阅读时间需要 4 分钟。
这里写自定义目录标题
本文也是使用anchor free的方式来做object detection的,网络结构看下来和很像。
AFDet
Backbone & Neck
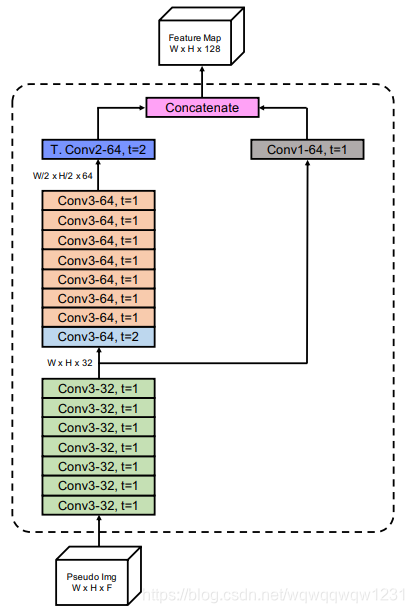
使用PointPillar的方式构建backbone,但是只进行了一次stride=2的conv,然后又upsample,所以backbone输出的特征图的分辨率和输入的分辨率是一样的。
对于KITTI数据集,pillar的尺寸时[0.16m, 0.16m]
Head
从网络结构上看,就是标准的anchor free的head,和CenterNet,CenterPoint差不多。
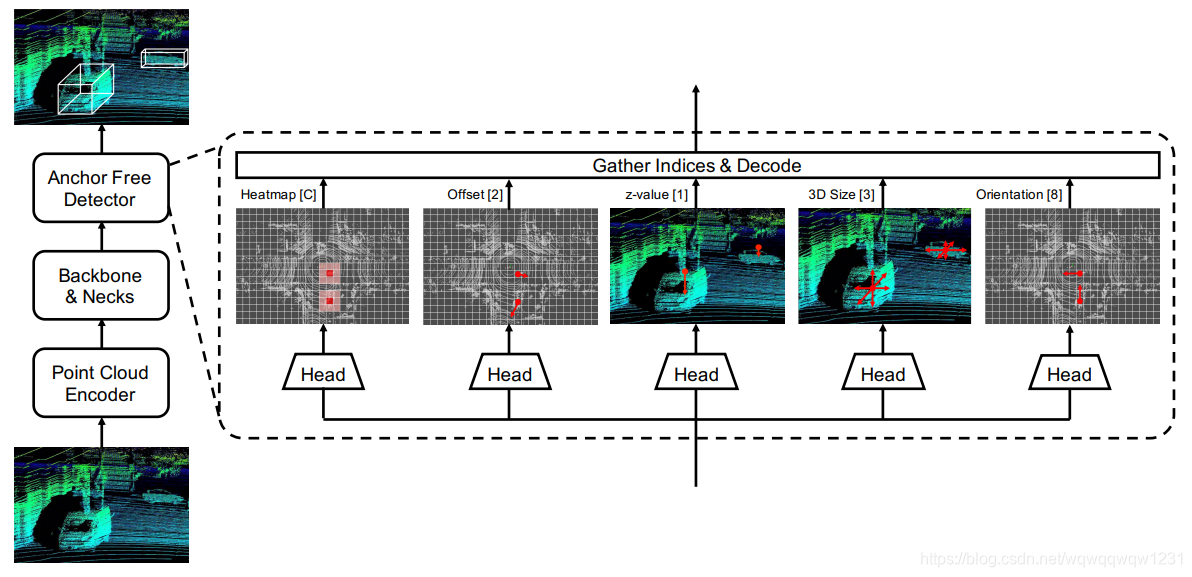 其中Heatmap的监督的Loss,也是与CenterNet,CenterPoint一样的。只是target的生成有些区别,下面会详细对比一下。
其中Heatmap的监督的Loss,也是与CenterNet,CenterPoint一样的。只是target的生成有些区别,下面会详细对比一下。 对于Cente offset这个预测值,文中提到是有两个做用:1)一个是将预测的中心通过加上offset,把中心的预测变成一个连续值,2)纠正错误的中心预测,也就是当heatmap预测中心偏了几个像素,offset有能力对这种偏差纠错。
如此,offset的预测的监督就不能是只在中心点这个像素上了,而且要在中心点周围几个像素上都要做监督。通过消融实验发现,使用中心点向周围扩展两个像素做监督最好,也就是每个物体,以物体中心为中心,周围5x5个像素中的offset都要受到监督。
AFDet与CenterPoint的区别
heatmap的target中的高斯核半径的设置
两篇文章都有提到相对于CenterNet,生成heatmap的target的过程中的高斯核半径的设置需要增大,因为俯视图下,物体都比较小,大量像素为背景,所以需要增加heatmap的target中不为0的点的数量。
CenterPoint的方式是,强制半径最小为2,heatmap生成的方式是高斯核。AFDet中则使用物体内部的点的target为其与中心距离的反比。这两篇文章的做法都能解决上述问题。
对于CenterNet的heatmap的高斯核计算方式,是来自于CornerNet。想法来源于,当width和height准的时候,center偏移多少,仍能保持在一定的IoU以上。以这个想法,确定高斯核的半径。具体可见https://zhuanlan.zhihu.com/p/96856635
voxel或者pillar的大小设置
AFDet中使用的[0.16m,0.16m]的Pillar设置,Neck输出分辨率与输入分辨率不变,也就是说检测仍然在[0.16m,0.16m]的特征图上做。
CenterPoint在waymo上用的是[0.32m, 0.32m]的Pillar设置,Neck的特征图的分辨率仍然与输入的相同,检测在[0.32m, 0.32m]的特征图上做。
Part-A^2和PV-RCNN来看,对于KITTI数据集,voxel设置为[0.05m,0.05m],但backbone将其将降采样8x,也就是检测在[0.4m,0.4m]的特征图上做。对于waymo的话,voxel设置为[0.1m,0.1m],降采样8x就是[0.8m,0.8]。
转载地址:https://blog.csdn.net/wqwqqwqw1231/article/details/118157366 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
