本文共 10150 字,大约阅读时间需要 33 分钟。
目录
写在开头
有点总结不过来了,3D object detection这个领域从2019年文章数量急剧上升。我也没办法把所有文章都更新在这里,而且one-stage和two-stage的划分方法不太适用了。我看了的文章的详细解读都放在了一个专栏里,,读者们可以自行从其中找感兴趣的文章。
3D Object Detection
2D Object Detection 的研究已经非常成熟了,代表作品有RPN系列的FasterRCNN和MaskRCNN,One Shot系列的YOLOv1-YOLOv3。这里推荐一个2D Object Detection发展过程和论文的。
在2D Object Detection的基础上又提出了新的要求3D Object Detection。问题的具体描述检测环境中的三维物体,并给出物体的Bounding Box。相比于2D,3D的Bounding Box的表示除了多了一个维度的位置和尺寸,还多了三个角度。可以想象,一架飞机的Bounding Box的尺寸的是固定的,飞机的姿态除了位置之外,还有俯仰角、偏航角和翻滚角三个角度。
目前对于3D Object Detection有迫切需求的产业是自动驾驶产业,因为要想安全的自动驾驶,需要周围障碍物的三维位姿,在图片中的二维位姿不带深度信息,没有办法有效避免碰撞。所以3D Object Detection的数据集大多也是自动驾驶数据集,类别也主要是车辆和行人等,比较常用的有和。由于自动驾驶针对车辆,所以障碍物的高度的检测对于安全行驶并没有十分重要,而障碍物都在陆地上,所以也不存在俯仰角和翻滚角两个角度。所以有些3D Object Detection方法将这三值忽略了。
接下来我将详细列几篇论文,以及我认为论文中比较关键的一些点。每篇论文具体的细节和解读还请读者自行搜索。3D Object Detection的方法很大程度上是借鉴了2D Object Detection的方法。
相关博客:
Sliding window
Vote3Deep: Fast Object Detection in 3D Point Clouds Using Efficien(IROS2017)

 具体投票为将中心对称过后的卷积核的中心与非零点对齐,然后相乘,即可得到改点的投票。将多点投票的重叠的区域相加,得到输出。
具体投票为将中心对称过后的卷积核的中心与非零点对齐,然后相乘,即可得到改点的投票。将多点投票的重叠的区域相加,得到输出。 Two Stage
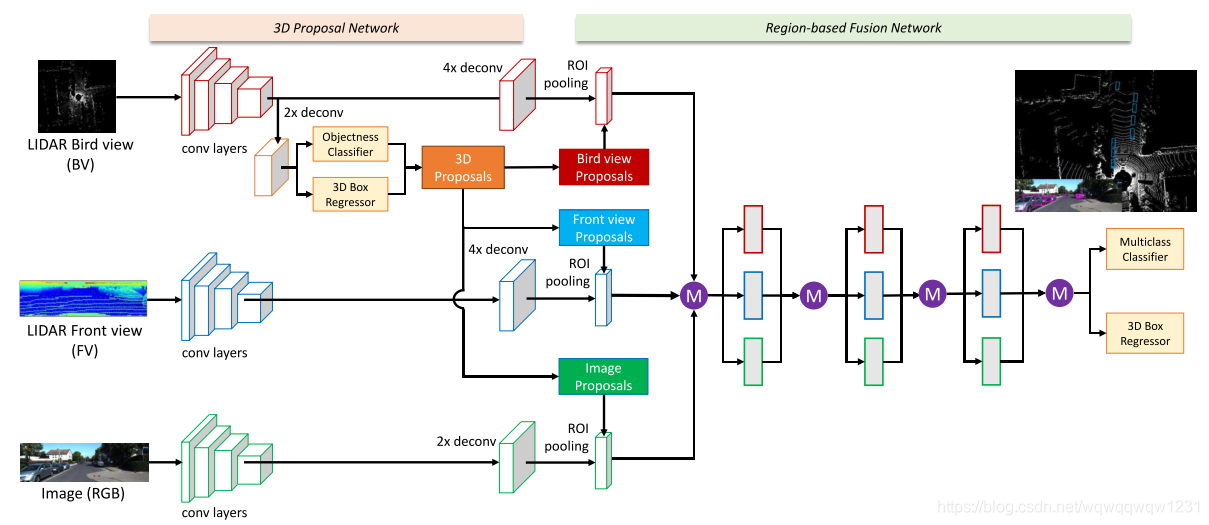
Multi-View 3D Object Detection Network for Autonomous Driving (CVPR2017)
-
文章中强调使用俯视图的好处
“We use the bird’s eye view map as input. In 3D object detection, The bird’s eye view map has several advantages over the front view/image plane. First, objects preserve physical sizes when projected to the bird’s eye view, thus having small size variance, which is not the case in the front view/image plane. Second, objects in the bird’s eye view occupy different space, thus avoiding the occlusion problem. Third, in the road scene, since objects typically lie on the ground plane and have small variance in vertical location, the bird’s eye view location is more cru- cial to obtaining accurate 3D bounding boxes. Therefore, using explicit bird’s eye view map as input makes the 3D location prediction more feasible.” -
本文提出的俯视图的构建过程非常有参考价值,是后续多篇文章所参考的依据。
RT3D: Real-Time 3-D Vehicle Detection in LiDAR Point Cloud for Autonomous Driving
用R-FCN检测车辆。
Frustum PointNets for 3D Object Detection from RGB-D Data (CVPR2018)
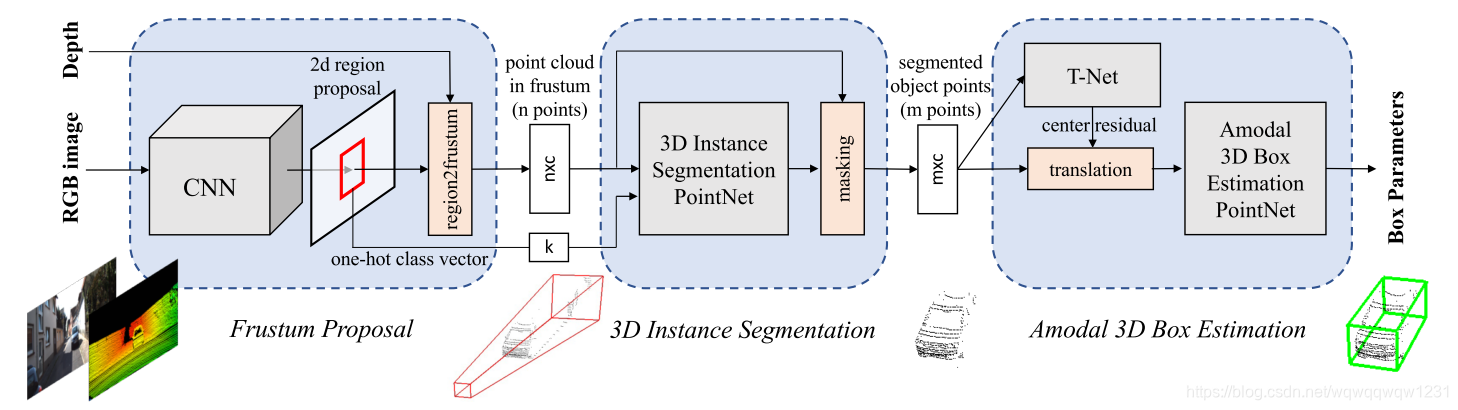
- 处理流程 利用2D Object Detection方法在image上进行车辆检测; 使用2D proposals得到3D椎体proposals,并进行坐标变换,将坐标轴旋转至椎体中心线; 利用PointNet++进行3D Instance Segmentation,并进行坐标变换,将原点平移至instance的型心; 使用T-net进行坐标变换,估计物体的中心; 3D box 回归。
其中包含三次坐标变换如下图:

-
相比于Pointnet,T-net的训练是受监督的。
“However, different from the original STN that has no direct supervision on transformation, we explicitly supervise our translation network to predict center residuals from the mask coordinate origin to real object center.” -
在回归3D box时,该文还提出同时使用Smooth_L1和Corner loss,以提升回归的准确性
"While our 3D bounding box parameterization is compact and complete, learning is not optimized for final 3D box accuracy – center, size and heading have separate loss terms. Imagine cases where center and size are accurately predicted but heading angle is off – the 3D IoU with ground truth box will then be dominated by the angle error. Ideally all three terms (center,size,heading) should be jointly optimized for best 3D box estimation (under IoU metric). To resolve this problem we propose a novel regularization loss, the corner loss: "
Joint 3D Proposal Generation and Object Detection from View Aggregation (IROS2018)
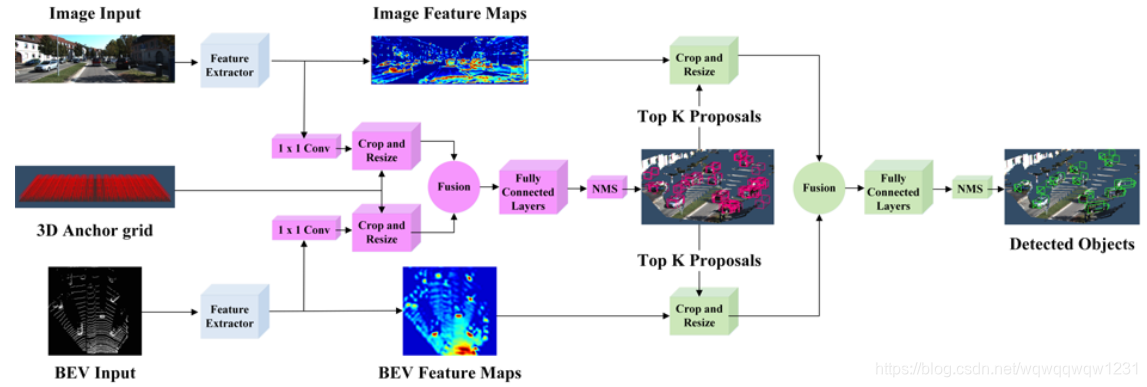
- 本文提出了一种新的3D box 的8个corner的编码方式 “To reduce redundancy and keep these physical constraints, we propose to encode the bounding box with four corners and two height values representing the top and bottom corner offsets from the ground plane, determined from the sensor height.”
PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud (CVPR2019)
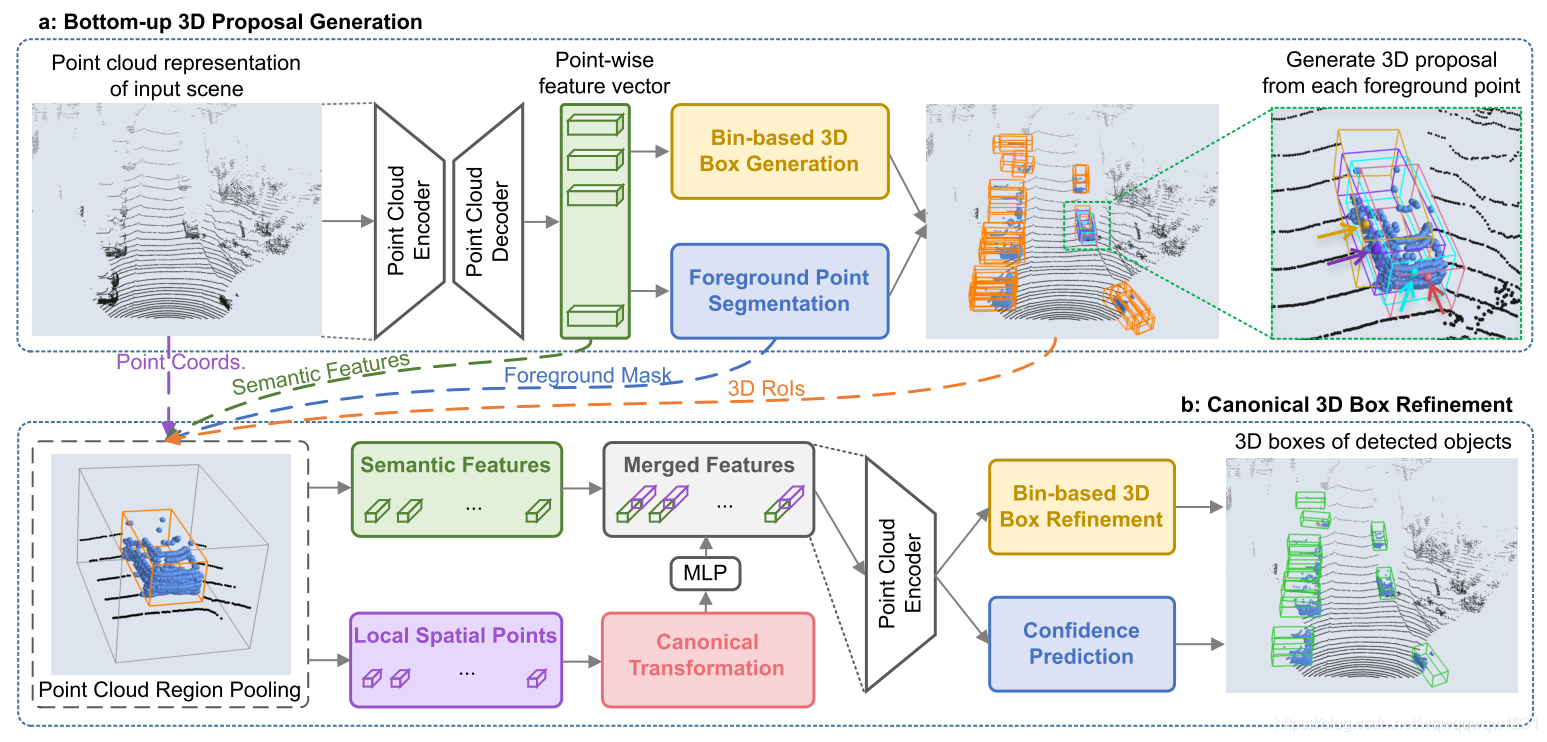
- 由于该方法第一次得到RoI的数量与三维点的数量相等,所以该方法理论上可以检测到所有的框。
- 文章中提到了Frustum PointNet的弊端 “F-PointNet [22] generates only 2D box proposals from 2D images, and estimate 3D boxes based on the 3D points cropped from the 2D regions. Its 2D-based proposal generation step might miss many difficult objects that could only be clearly observed from 3D space.”
- 解决了大量使用anchor的问题 “our method avoids using a large set of predefined 3D anchor boxes in the 3D space and significantly constrains the search space for 3D proposal generation.”
- 使用了Full-bin Loss,使得收敛速度和精度上升
VoteNet:Deep Hough Voting for 3D Object Detection in Point Clouds
Multi-Task Multi-Sensor Fusion for 3D Object Detection
GS3D: An Efficient 3D Object Detection Framework for Autonomous Driving
Stereo R-CNN based 3D Object Detection for Autonomous Driving
STD: Sparse-to-Dense 3D Object Detector for Point Cloud
[详细解读传送门(https://blog.csdn.net/wqwqqwqw1231/article/details/100565150)
Part-A^2 Net: 3D Part-Aware and Aggregation Neural Network for Object Detection from Point Cloud
[详细解读传送门(https://blog.csdn.net/wqwqqwqw1231/article/details/100541138)
Class-balanced Grouping and Sampling for Point Cloud 3D Object Detection
本文更偏重于讲一些数据增广的方法和小技巧。
BirdNet: a 3D Object Detection Framework from LiDAR Information(2018 ITSC)
本文主要的贡献是解决跨线数激光雷达的训练和检测的鲁棒性问题。
StarNet: Targeted Computation for Object Detection in Point Clouds
本文提出了不使用神经网络生成proposal的方法,该方法的另外一个先进性在于inference过程和train过程的使用点云的数量可以不同,使得部署更方便。
PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection
目前KITTI榜首。
One Stage
3D Fully Convolutional Network for Vehicle Detection in Point Cloud (IROS2017)
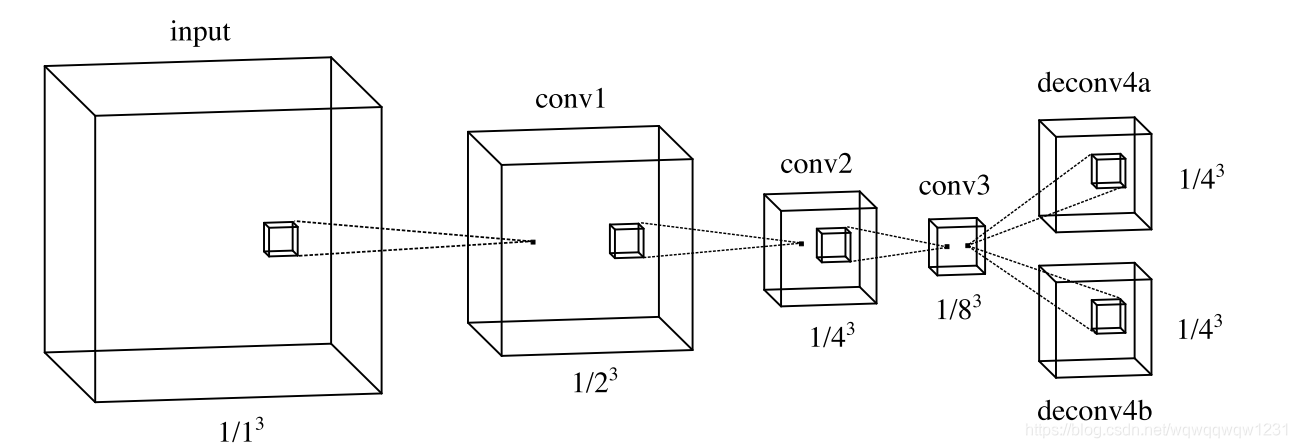
相比后来的方法,该方法显得粗糙一些,但是本论文是将3D Object Detection从传统方法过度到深度学习的文章之一,还是有值得学习之处。
- 提出了使用Bounding Box的Corners作为回归变量,该回归方法在Frustum PointNets又被重新使用,并取得了效果的提升。
- 该文章介绍了比较多的点云栅格化过程中每个栅格的特征构建的方法,可以用来查找手工构建栅格特征的方法。
Complex-YOLO: An Euler-Region-Proposal for Real-time 3D Object Detection on Point Clouds(ECCV2018)
YOLO3D: End-to-end real-time 3D Oriented Object Bounding Box Detection from LiDAR Point Cloud(ECCV2018)
两篇文章作者来自同一个机构,姑且认为两篇文章有联系。这两篇文章用的方法也如出一辙,都是使用MVNet俯视图的构建方法,然后利用YOLO在俯视图上做Object Detection,只不过是回归变量多了一个维度和角度,就解决了3D Object Detection的问题。
方法没有什么创新之处,文章中提到了Frustum Pointnet的不足之处。 “This approach has two drawbacks: i). The models accuracy strongly depends on the camera image and its associated CNN. Hence, it is not possible to apply the approach to Lidar data only; ii). The overall pipeline has to run two deep learning approaches consecutive, which ends up in higher inference time with lower effciency.” 说出了Frustum Pointnet在构建proposal的时候依赖CNN这个问题。PIXOR: Real-time 3D Object Detection from Point Clouds (CVPR2018)
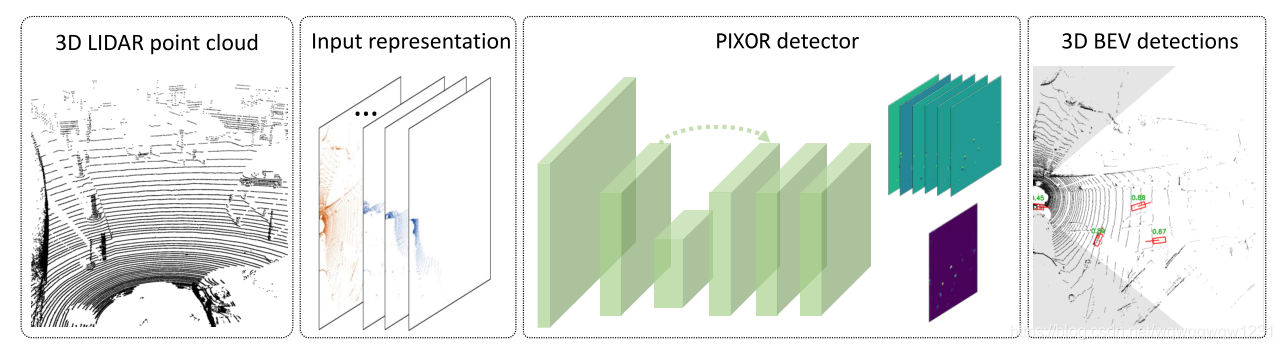
类似于MVnet,将点云转为俯视图表示。
使用resnet进行特征提取,然后upsample至原图1/4的大小。 然后加入分类头和回归头。整个网络框架如下图
 我认为这个方法类似于YOLO的思想,One Shot将box分类和回归。Feature Map上采样至俯视图尺寸的1/4,相当于YOLO中的每个格子为4*4个像素。该方法回归的变量均是2维变量:俯视图中的中心点、长宽和方向角。
我认为这个方法类似于YOLO的思想,One Shot将box分类和回归。Feature Map上采样至俯视图尺寸的1/4,相当于YOLO中的每个格子为4*4个像素。该方法回归的变量均是2维变量:俯视图中的中心点、长宽和方向角。 - 该论文的俯视图的编码是使用栅格的占据编码,不再使用大多数文章使用的高度。 “The value for each cell is encoded as occupancy”
- 论文论述了如何解决小目标的问题。小目标在原始图片张占据的像素点少,提取高层特征后,很容易在feature map只对应几个像素点。 “One direct solution is to use fewer pooling layers. However, this will decrease the size of the receptive field of each pixel in the final feature map, which limits the representa- tion capacity. Another solution is to use dilated convolu- tions. However, this would lead to checkerboard artifacts [25] in high-level feature maps. Our solution is simple, we use 16×downsampling factor, but make two modifications. First, we add more layers with small channel number in lower levels to extract more fine-detail information. Sec- ond, we adopt a top-down branch similar to FPN [21] that combines high-resolution feature maps with low-resolution ones so as to up-sample the final feature representation.”
- 一个实现细节,在regression头后没有再使用sigmoid函数
HDNET: Exploiting HD Maps for 3D Object Detection (CoRL2018)
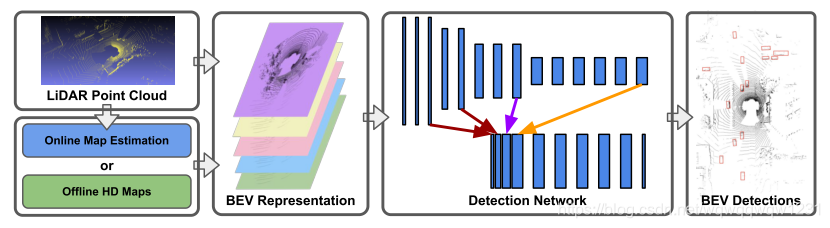
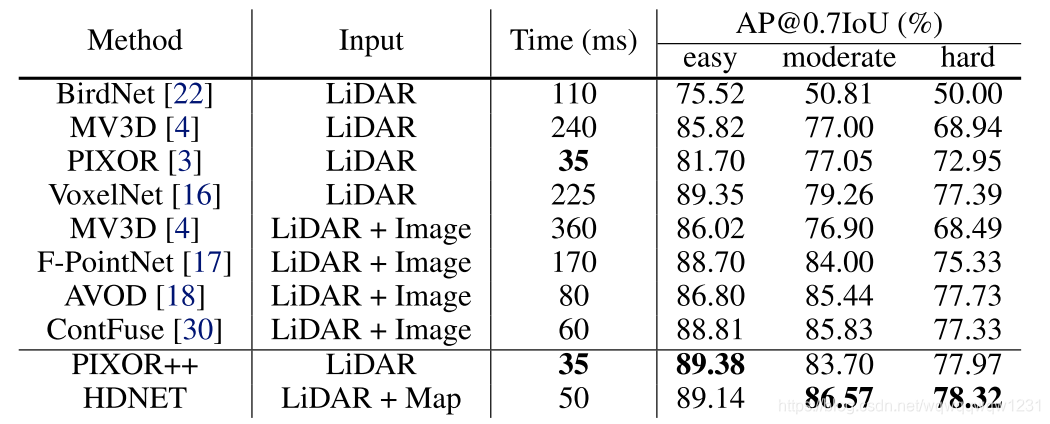
- 该文章除了使用在使用高清地图的地方对PIXOR做了改进,还在输入和回归变量的地方进行了略微改进,论文中称为PIXOR++,可以从结果看出PIXOR++的效果要比PIXOR效果好不少,值得借鉴。
- 为了提高网络在高精地图不存在情况下的鲁棒性,该论文提出了对高清地图做dropout的方法。 “In practice, having a detector that works regardless of map availability is important. Towards this goal, we apply data dropout on the semantic prior, which randomly feeds an empty road mask to the network during training. Our experiments show that data dropout largely improves the model’s robustness to map availability.”
Voxel-FPN: multi-scale voxel feature aggregation in 3D object detection from point clouds
VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection (CVPR2018) (未完)
LaserNet: An Effcient Probabilistic 3D Object Detector for Autonomous Driving Gregory (Arxiv2019)(未完)
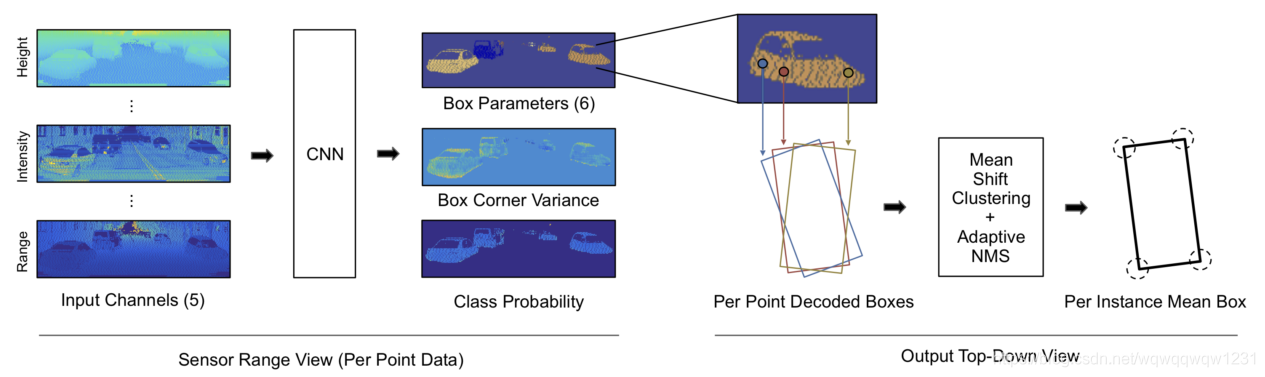
3DSSD: Point-based 3D Single Stage Object Detector
另一种分类方式:Voxel or Image or Pointcloud?
另一种分类方式,是从网络的输入和网络结构来分。对这种分类的详细的解释,可以参考我的另一篇博客。
- Voxel:输入为体素格式,典型为VoxelNet,网络使用3D卷积大量使用操作
- Image:输入为图片格式,典型为MVNet,网络使用传统的CNN
- Pointcloud:输入为点云格式,典型为PointNet,网络使用多层感知机,多层感知机的具体实现是2D卷积,但卷积核大小和步长多数为1
这种分类方式由于输入的不同,数据本身就有独自的优势和劣势:
- Voxel:最大问题就是计算慢!体素是三维的,卷积模板也是三维的,那么计算起来就比二维的慢,而且卷积核移动的方向也是三维的,随着空间的大小的增大,体素的数量是以立方的数量增长;而且在自动驾驶场景,体素是稀疏的,存在大量体素中不包含雷达点,特征为0,做很多无用卷积。所以这种方式计算量大而且很多是无效计算。
- Image:结果的好坏与输入的特征的有关,有效地将点云转为图像也是一个可以研究的点。
- PointNet:可用的工具少,目前主流的也就是PointNet系列和Graph convolution系列。
Loss的进化史
使用深度学习除了网络结构,另外一个要关注的点是Loss的构建。接下来,就聊一聊Loss构建的发展史:
未完待续。。。
转载地址:https://blog.csdn.net/wqwqqwqw1231/article/details/90693612 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
