机器学习——sklearn实现决策树(隐形眼镜预测和鸢尾花分类)
发布日期:2021-06-22 22:48:23
浏览次数:3
分类:技术文章
本文共 5112 字,大约阅读时间需要 17 分钟。
文章目录
sklearn中利用决策树实现隐形眼镜类型的预测
一、准备数据集
- 数据集的介绍 隐形眼镜数据集是非常著名的数据集,它包含很多眼部状态的观察条件以及医生推荐的隐形眼镜类型。隐形眼镜类型包括硬材质(hard)、软材质(soft)以及不适合佩戴隐形眼镜(no lenses)。整个数据集一共有24组数据,数据的Labels依次是age、prescript、astigmatic、tearRate、class,也就是第一列是年龄,第二列是症状,第三列是是否散光,第四列是眼泪数量,第五列是最终的分类标签。

- 数据集的下载 下载地址:
二、环境的准备
- 安装sklearn
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple sklearn
- 安装pydotplus
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pydotplus
- 安装Graphviz 下载地址: 安装过程,按照安装向导的指示进行。如果按照过程,没有选择自动添加
PATH,需要自行手动添加环境变量。 添加环境变量过程: 选择我的电脑->属性->高级->环境变量。在系统变量的Path变量中,添加Graphviz的环境变量,若Graphviz安装在了D盘的根目录,则添加:D:\Graphviz\bin
三、DecisionTreeClassifier构建决策树的部分参数说明
- criterion 特征选择标准,可选参数,默认是gini,可以设置为entropy。gini是基尼系数,使用该参数的时候,是采用的CART算法实现决策树的。entropy是信息增益,也就是采用的ID3算法实现决策树的。
- splitter 特征划分点选择标准,可选参数,默认是best,可以设置为random。best参数是根据算法选择最佳的切分特征,random随机的在部分划分点中找局部最优的划分点。“best"适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐使用"random”。
- max_depth 决策树最大深度,可选参数,默认是None。当模型样本很多的时候,可以取值10-100。
- min_samples_split 内部节点再划分所需最小样本数,可选参数,默认是2。当min_samples_split为整数,min_samples_split作为划分的最小样本数,若样本已经少于min_samples_split个样本,则停止继续划分。当min_samples_split为浮点数,那么min_samples_split就是一个百分比,ceil(min_samples_split * n_samples),数是向上取整的。如果样本量数量级非常大,则增大这个值。
- min_samples_leaf 叶子节点最少样本数,可选参数,默认是1。如果min_samples_leaf是整数,那么min_samples_leaf作为最小的样本数。如果是浮点数,那么min_samples_leaf就是一个百分比,celi(min_samples_leaf * n_samples),数是向上取整的。如果样本量数量级非常大,则增大这个值。
更多参数的详细信息内容参考下面链接:说明:一般都使用决策树默认的参数设置,若自行设置参数的值,根据实际情况进行设定。
四、利用决策树实现隐形眼镜类型的预测
- 读取数据集
from sklearn.preprocessing import LabelEncoder, OneHotEncoder#from sklearn.externals.six import StringIOfrom six import StringIOfrom sklearn import treeimport pandas as pdimport numpy as npimport pydotplusif __name__ == '__main__': fr = open('lenses.txt') lenses = [inst.strip().split('\t') for inst in fr.readlines()] print(lenses)得到的是string
- string类型的数据序列化
lenses_target = [] #提取每组数据的类别,保存在列表里 for each in lenses: lenses_target.append(each[-1]) lensesLabels = ['age', 'prescript', 'astigmatic', 'tearRate'] #特征标签 lenses_list = [] #保存lenses数据的临时列表 lenses_dict = { } #保存lenses数据的字典,用于生成pandas for each_label in lensesLabels: #提取信息,生成字典 for each in lenses: lenses_list.append(each[lensesLabels.index(each_label)]) lenses_dict[each_label] = lenses_list lenses_list = [] print(lenses_dict) #打印字典信息 lenses_pd = pd.DataFrame(lenses_dict) #生成pandas.DataFrame print(lenses_pd) le = LabelEncoder() #创建LabelEncoder()对象,用于序列化 for col in lenses_pd.columns: #序列化 lenses_pd[col] = le.fit_transform(lenses_pd[col]) 序列化
序列化 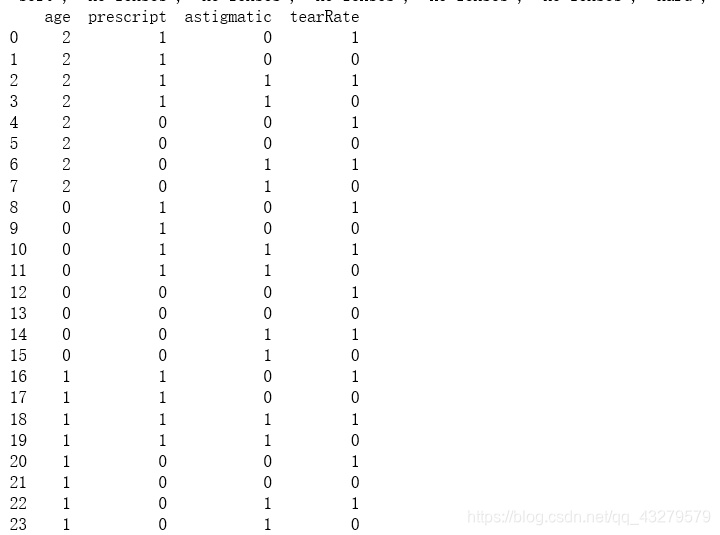
- 构建决策树
clf = tree.DecisionTreeClassifier(max_depth = 4) #创建DecisionTreeClassifier()类 clf = clf.fit(lenses_pd.values.tolist(), lenses_target) #使用数据,构建决策树
- 决策树的可视化
dot_data = StringIO() tree.export_graphviz(clf, out_file = dot_data, #绘制决策树 feature_names = lenses_pd.keys(), class_names = clf.classes_, filled=True, rounded=True, special_characters=True) graph = pydotplus.graph_from_dot_data(dot_data.getvalue()) graph.write_pdf("tree.pdf")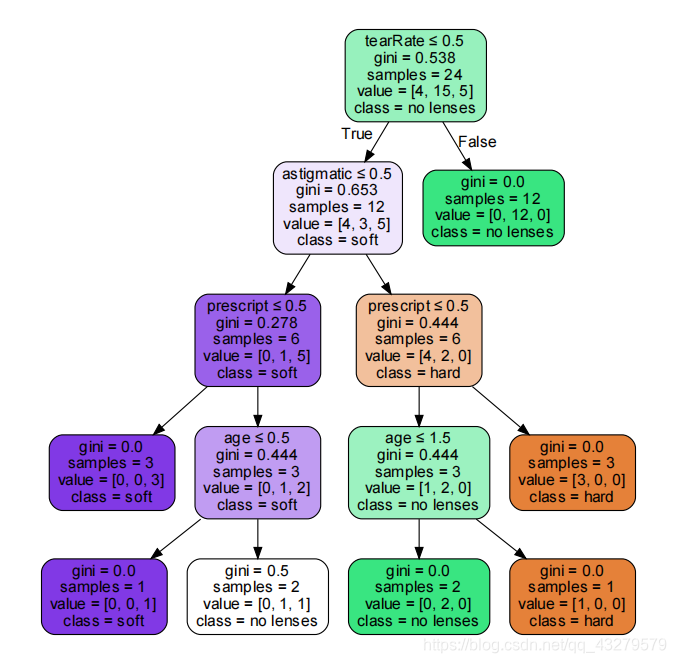
- 预测 可以根据自己的眼睛情况和年龄等特征,看一看自己适合何种材质的隐形眼镜
print(clf.predict([[1,1,1,0]]))

sklearn中利用决策树实现鸢尾花分类
一、数据集
- 数据集获取
#导入相应的包from sklearn import datasets #导入方法类from sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import LabelEncoder, OneHotEncoder#from sklearn.externals.six import StringIOfrom six import StringIOfrom sklearn import treeimport pandas as pdimport numpy as npimport pydotplusfrom sklearn.metrics import accuracy_score# 获取所需数据集iris=datasets.load_iris()#每行的数据,一共四列,每一列映射为feature_names中对应的值X=iris.data#每行数据对应的分类结果值(也就是每行数据的label值),取值为[0,1,2]Y=iris.target#通过Y=iris.target.size,可以得到一共150行数据,三个类别个50条数据,并且数据是按照0,1,2的顺序放的#print(iris)
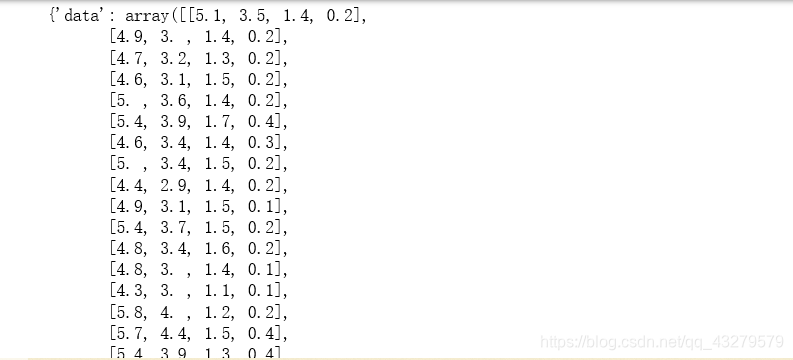
- 数据集划分
#划分训练集和测试集,按照7:3的比例划分X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=42)print(X_train.shape)print(X_test.shape)

二、利用决策树实现鸢尾花分类
- 构建决策树
clf = tree.DecisionTreeClassifier()lenses = clf.fit(X_train, Y_train)
- 决策树可视化
dot_data = StringIO()tree.export_graphviz(clf, out_file = dot_data, #绘制决策树 feature_names = iris.feature_names, class_names = iris.target_names, filled=True, rounded=True, special_characters=True)graph = pydotplus.graph_from_dot_data(dot_data.getvalue())graph.write_pdf("treeiris.pdf")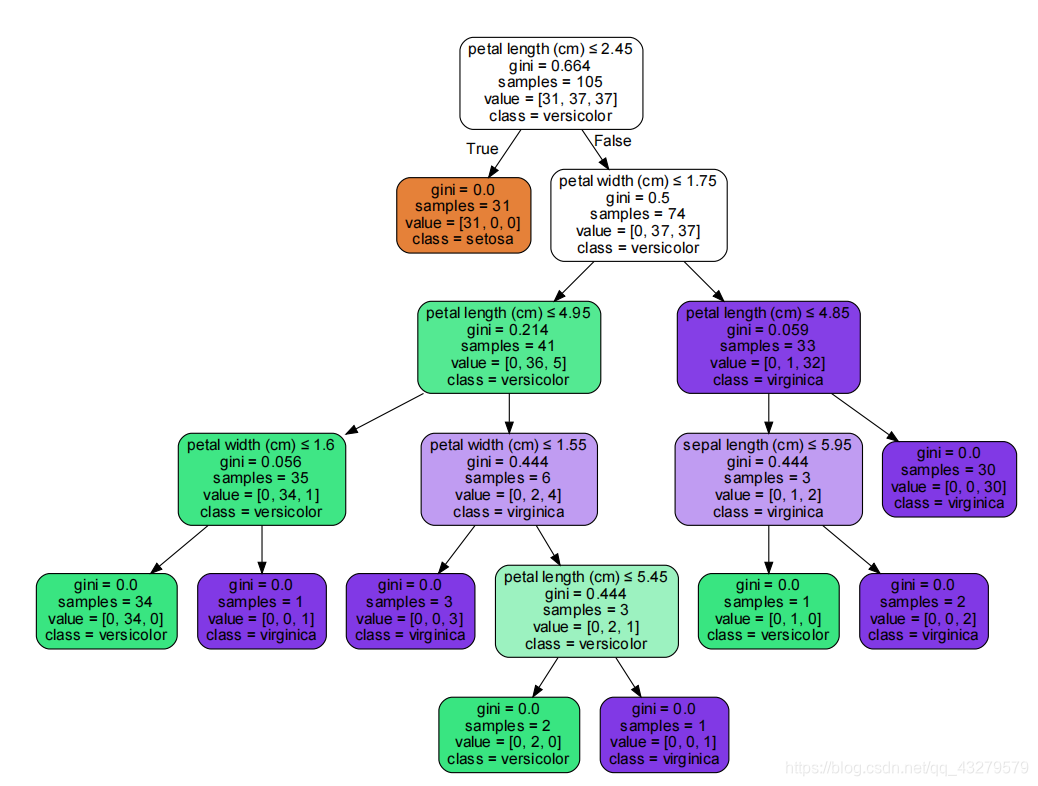
- 预测准确率
predict_results = clf.predict(X_test) # 使用模型对测试集进行预测print(accuracy_score(predict_results, Y_test))

总结
sklearn实现决策树的过程
- 对数据集进行处理
- 使用tree.DecisionTreeClassifier()进行构建
- 使用clf.fit(X_train, Y_train)进行训练
- 将构建的决策树可视化
- 给相应的数据进行预测
参考资料
转载地址:https://blog.csdn.net/qq_43279579/article/details/116853918 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
网站不错 人气很旺了 加油
[***.192.178.218]2024年04月16日 22时04分04秒
关于作者

喝酒易醉,品茶养心,人生如梦,品茶悟道,何以解忧?唯有杜康!
-- 愿君每日到此一游!
推荐文章
Eigen3矩阵与数组的互相转换
2019-04-28
动力学方程MCG矩阵的计算
2019-04-28
windows下Makefile无法删除中间文件的解决方案
2019-04-28
Simulink生成ROS功能包的步骤总结
2019-04-28
硬件在环(HIL)仿真方案
2019-04-28
基于模型设计(MBD)的机器人开发流程
2019-04-28
机器人非实时性示教系统的框架
2019-04-28
协作机械臂伺服驱动关键技术公开课笔记
2019-04-28
从伺服系统来看如何提升机器人的轨迹精度 公开课笔记
2019-04-28
关于Adams安装过程中问题的解决记录
2019-04-28
kinova-Mico安装与调试
2019-04-28
Elmo运动控制器 —— Maestro Software编程实践指南
2019-04-28
Elmo运动控制器 —— Maestro Software结构和接口
2019-04-28
Power PMAC运动控制器 —— 学习笔记2
2019-04-28
运动控制 —— 强大的状态机工具
2019-04-28
Platinum Maestro运动控制器 —— PVT模式笔记
2019-04-28
Platinum Maestro运动控制器 —— 运动程序笔记
2019-04-28
PID算法原理及参数调整原则
2019-04-28
Platinum Maestro运动控制器 ——速度位置等数据的获取
2019-04-28
Platinum Maestro运动控制器 ——Ssh登录控制器
2019-04-28
白红宇的个人博客 - 记录点点滴滴的事 - 您是第 308290626 位访客
访问时间: 2024-04-27 07:54:28
访问IP: 18.118.12.222
Copyright © 2020 - 2023 blog.css8.cn 京ICP备2021015314号-1
手机版