本文共 8064 字,大约阅读时间需要 26 分钟。
链表和数组是数据类型中两个重要又常用的基础数据类型。
数组是连续存储在内存中的数据结构,因此它的优势是可以通过下标迅速的找到元素的位置,而它的缺点则是在插入和删除元素时会导致大量元素的被迫移动,为了解决和平衡此问题于是就有了链表这种数据类型。
链表和数组可以形成有效的互补,这样我们就可以根据不同的业务场景选择对应的数据类型了。那么,本文我们就来重点介绍学习一下链表,一是因为它非常重要,二是因为面试必考,先来看本文大纲:
看过某些抗日神剧我们都知道,某些秘密组织为了防止组织的成员被“一窝端”,通常会采用上下级单线联系的方式来保护其他成员,而这种“行为”则是链表的主要特征。
简介
链表(Linked List)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer)。
链表是由数据域和指针域两部分组成的,它的组成结构如下:
复杂度分析
由于链表无需按顺序存储,因此链表在插入的时可以达到 O(1) 的复杂度,比顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要 O(n) 的时间,而顺序表插入和查询的时间复杂度分别是 O(log n) 和 O(1)。
优缺点分析
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
分类
链表通常会分为以下三类:单向链表
双向链表
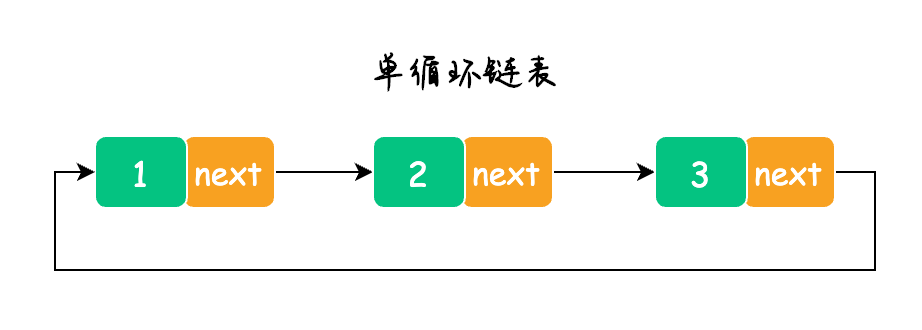
循环链表单循链表
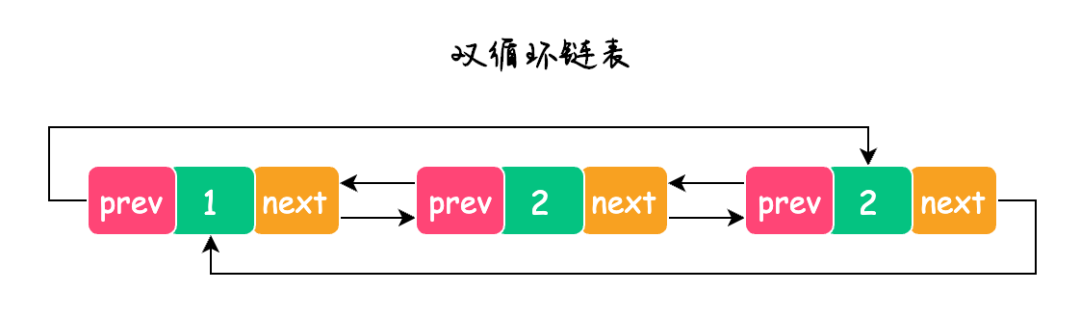
双循环链表
1.单向链表
链表中最简单的一种是单向链表,或叫单链表,它包含两个域,一个数据域和一个指针域,指针域用于指向下一个节点,而最后一个节点则指向一个空值,如下图所示:
单链表的遍历方向单一,只能从链头一直遍历到链尾。它的缺点是当要查询某一个节点的前一个节点时,只能再次从头进行遍历查询,因此效率比较低,而双向链表的出现恰好解决了这个问题。
接下来,我们用代码来实现一下单向链表的节点:private static class Node{
E item;
Node next;
Node(E element, Node next) {
this.item = element;
this.next = next;
}
}
2.双向链表
双向链表也叫双面链表,它的每个节点由三部分组成:prev 指针指向前置节点,此节点的数据和 next 指针指向后置节点,如下图所示:
接下来,我们用代码来实现一下双向链表的节点:private static class Node{
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
3.循环链表
循环链表又分为单循环链表和双循环链表,也就是将单向链表或双向链表的首尾节点进行连接,这样就实现了单循环链表或双循环链表了,如下图所示:
Java中的链表
学习了链表的基础知识之后,我们来思考一个问题:Java 中的链表 LinkedList 是属于哪种类型的链表呢?单向链表还是双向链表?
要回答这个问题,首先我们要来看 JDK 中的源码,如下所示:package java.util;
import java.util.function.Consumer;
public class LinkedList
extends AbstractSequentialList
implements List, Deque, Cloneable, java.io.Serializable{
// 链表大小
transient int size = 0;
// 链表头部
transient Node first;
// 链表尾部
transient Node last;
public LinkedList(){
}
public LinkedList(Collection extends E> c){
this();
addAll(c);
}
// 获取头部元素
public E getFirst(){
final Node f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
// 获取尾部元素
public E getLast(){
final Node l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
// 删除头部元素
public E removeFirst(){
final Node f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
// 删除尾部元素
public E removeLast(){
final Node l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
// 添加头部元素
public void addFirst(E e){
linkFirst(e);
}
// 添加头部元素的具体执行方法
private void linkFirst(E e){
final Node f = first;
final Node newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
// 添加尾部元素
public void addLast(E e){
linkLast(e);
}
// 添加尾部元素的具体方法
void linkLast(E e){
final Node l = last;
final Node newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
// 查询链表个数
public int size(){
return size;
}
// 清空链表
public void clear(){
for (Node x = first; x != null; ) {
Node next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
}
// 根据下标获取元素
public E get(int index){
checkElementIndex(index);
return node(index).item;
}
private static class Node{
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
// 忽略其他方法......
}
从上述节点 Node 的定义可以看出:LinkedList 其实是一个双向链表,因为它定义了两个指针 next 和 prev 分别用来指向自己的下一个和上一个节点。
链表常用方法
LinkedList 的设计还是很巧妙的,了解了它的实现代码之后,下面我们来看看它是如何使用的?或者说它的常用方法有哪些。
1.增加
接下来我们来演示一下增加方法的使用:public class LinkedListTest{
public static void main(String[] a){
LinkedList list = new LinkedList();
list.add("Java");
list.add("中文");
list.add("社群");
list.addFirst("头部添加"); // 添加元素到头部
list.addLast("尾部添加"); // 添加元素到最后
System.out.println(list);
}
}
以上代码的执行结果为:[头部添加, Java, 中文, 社群, 尾部添加]
出来以上的 3 个增加方法之外,LinkedList 还包含了其他的添加方法,如下所示:add(int index, E element):向指定位置插入元素;
offer(E e):向链表末尾添加元素,返回是否成功;
offerFirst(E e):头部插入元素,返回是否成功;
offerLast(E e):尾部插入元素,返回是否成功。
add 和 offer 的区别
它们的区别主要体现在以下两点:offer 方法属于 Deque接口,add 方法属于 Collection的接口;
当队列添加失败时,如果使用 add 方法会报错,而 offer 方法会返回 false。
2.删除
删除功能的演示代码如下:import java.util.LinkedList;
public class LinkedListTest{
public static void main(String[] a){
LinkedList list = new LinkedList();
list.offer("头部");
list.offer("中间");
list.offer("尾部");
list.removeFirst(); // 删除头部元素
list.removeLast(); // 删除尾部元素
System.out.println(list);
}
}
以上代码的执行结果为:[中间]
除了以上删除方法之外,更多的删除方法如下所示:clear():清空链表;
removeFirst():删除并返回第一个元素;
removeLast():删除并返回最后一个元素;
remove(Object o):删除某一元素,返回是否成功;
remove(int index):删除指定位置的元素;
poll():删除并返回第一个元素;
remove():删除并返回第一个元素。
3.修改
修改方法的演示代码如下:import java.util.LinkedList;
public class LinkedListTest{
public static void main(String[] a){
LinkedList list = new LinkedList();
list.offer("Java");
list.offer("MySQL");
list.offer("DB");
// 修改
list.set(2, "Oracle");
System.out.println(list);
}
}
以上代码的执行结果为:[Java, MySQL, Oracle]
4.查询
查询方法的演示代码如下:import java.util.LinkedList;
public class LinkedListTest{
public static void main(String[] a){
LinkedList list = new LinkedList();
list.offer("Java");
list.offer("MySQL");
list.offer("DB");
// --- getXXX() 获取 ---
// 获取最后一个
System.out.println(list.getLast());
// 获取首个
System.out.println(list.getFirst());
// 根据下标获取
System.out.println(list.get(1));
// peekXXX() 获取
System.out.println("--- peek() ---");
// 获取最后一个
System.out.println(list.peekLast());
// 获取首个
System.out.println(list.peekFirst());
// 根据首个
System.out.println(list.peek());
}
}
以上代码的执行结果为:DB
Java
MySQL
--- peek() ---
DB
Java
Java
5.遍历
LinkedList 的遍历方法包含以下三种。
遍历方法一:for (int size = linkedList.size(), i = 0; i
System.out.println(linkedList.get(i));
}
遍历方法二:for (String str: linkedList) {
System.out.println(str);
}
遍历方法三:Iterator iter = linkedList.iterator();
while (iter.hasNext()) {
System.out.println(iter.next());
}
链表应用:队列 & 栈
1.用链表实现栈
接下来我们用链表来实现一个先进先出的“队列”,实现代码如下:LinkedList list = new LinkedList();
// 元素入列
list.add("Java");
list.add("中文");
list.add("社群");
while (!list.isEmpty()) {
// 打印并移除队头元素
System.out.println(list.poll());
}
以上程序的执行结果如下:Java
中文
社群
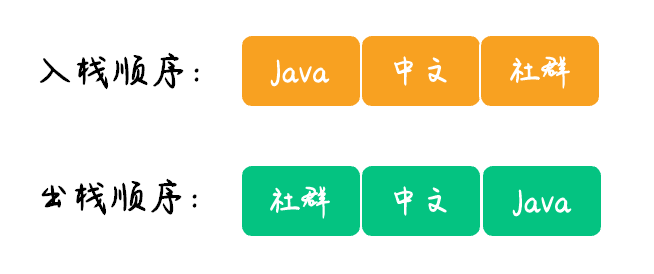
2.用链表实现队列
然后我们用链表来实现一个后进先出的“栈”,实现代码如下:LinkedList list = new LinkedList();
// 元素入栈
list.add("Java");
list.add("中文");
list.add("社群");
while (!list.isEmpty()) {
// 打印并移除栈顶元素
System.out.println(list.pollLast());
}
以上程序的执行结果如下:社群
中文
Java
链表使用场景
链表作为一种基本的物理结构,常被用来构建许多其它的逻辑结构,如堆栈、队列都可以基于链表实现。所谓的物理结构是指可以将数据存储在物理空间中,比如数组和链表都属于物理数据结构;而逻辑结构则是用于描述数据间的逻辑关系的,它可以由多种不同的物理结构来实现,比如队列和栈都属于逻辑结构。
链表常见笔试题
链表最常见的笔试题就是链表的反转了,之前的文章《链表反转的两种实现方法,后一种击败了100%的用户!》我们提供了 2 种链表反转的方法,而本文我们再来扩充一下,提供 3 种链表反转的方法。
实现方法 1:Stack
我们先用图解的方式来演示一下,使用栈实现链表反转的具体过程,如下图所示。
全部入栈:因为栈是先进后出的数据结构,因此它的执行过程如下图所示:最终的执行结果如下图所示:
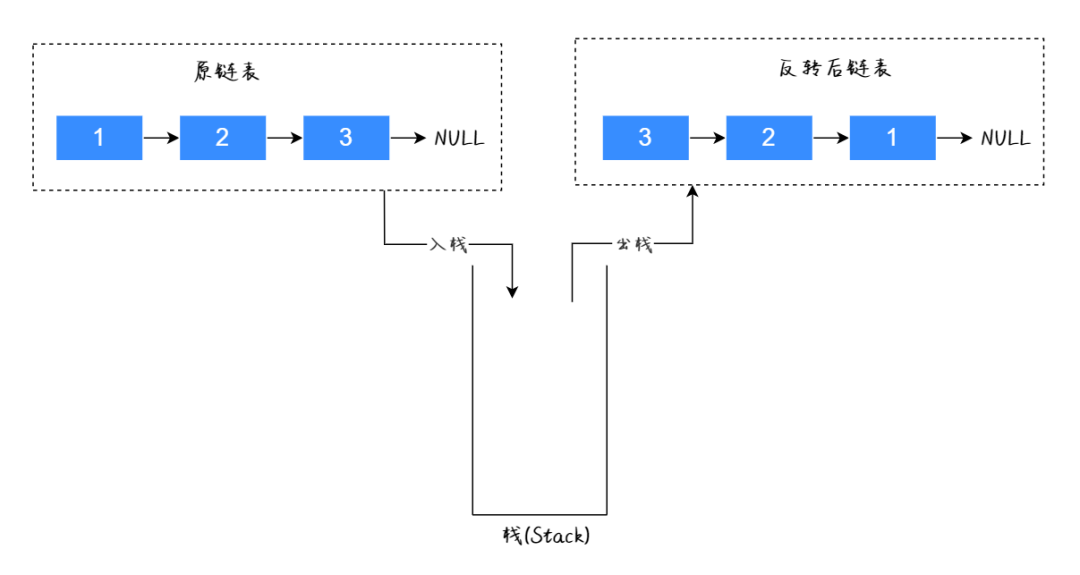 实现代码如下所示:public ListNode reverseList(ListNode head){
实现代码如下所示:public ListNode reverseList(ListNode head){
if (head == null) return null;
Stack stack = new Stack<>();
stack.push(head); // 存入第一个节点
while (head.next != null) {
stack.push(head.next); // 存入其他节点
head = head.next; // 指针移动的下一位
}
// 反转链表
ListNode listNode = stack.pop(); // 反转第一个元素
ListNode lastNode = listNode; // 临时节点,在下面的 while 中记录上一个节点
while (!stack.isEmpty()) {
ListNode item = stack.pop(); // 当前节点
lastNode.next = item;
lastNode = item;
}
lastNode.next = null; // 最后一个节点赋为null(不然会造成死循环)
return listNode;
}
LeetCode 验证结果如下图所示:

可以看出使用栈的方式来实现链表的反转执行的效率比较低。
实现方法 2:递归
同样的,我们先用图解的方式来演示一下,此方法实现的具体过程,如下图所示。
实现代码如下所示:public static ListNode reverseList(ListNode head){
if (head == null || head.next == null) return head;
// 从下一个节点开始递归
ListNode reverse = reverseList(head.next);
head.next.next = head; // 设置下一个节点的 next 为当前节点
head.next = null; // 把当前节点的 next 赋值为 null,避免循环引用
return reverse;
}
LeetCode 验证结果如下图所示:
 可以看出这种实现方法在执行效率方面已经满足我们的需求了,性能还是很高的。
可以看出这种实现方法在执行效率方面已经满足我们的需求了,性能还是很高的。
实现方法 3:循环
我们也可以通过循环的方式来实现链表反转,只是这种方法无需重复调用自身方法,只需要一个循环就搞定了,实现代码如下:class Solution{
public ListNode reverseList(ListNode head){
if (head == null) return null;
// 最终排序的倒序链表
ListNode prev = null;
while (head != null) {
// 循环的下个节点
ListNode next = head.next;
// 反转节点操作
head.next = prev;
// 存储下个节点的上个节点
prev = head;
// 移动指针到下一个循环
head = next;
}
return prev;
}
}
LeetCode 验证结果如下图所示:
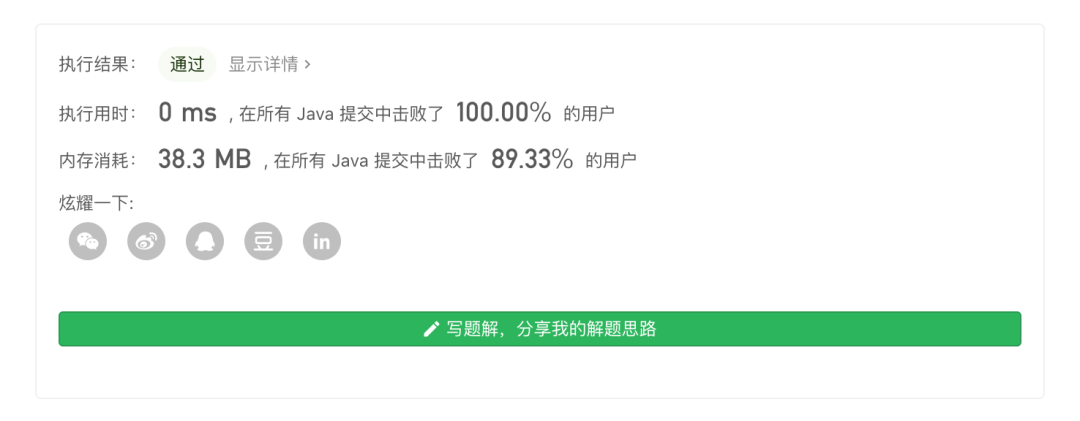 从上述图片可以看出,使用此方法在时间复杂度和空间复杂度上都是目前的最优解,比之前的两种方法更加理想。
从上述图片可以看出,使用此方法在时间复杂度和空间复杂度上都是目前的最优解,比之前的两种方法更加理想。
总结
本文我们讲了链表的定义,它是由数据域和指针域两部分组成的。链表可分为:单向链表、双向链表和循环链表,其中循环链表又可以分为单循链表和双循环链表。通过 JDK 的源码可知,Java 中的 LinkedList其实是双向链表,我们可以使用它来实现队列或者栈,最后我们讲了反转链表的 3 种实现方法,希望本文的内容对你有帮助。
转载地址:https://blog.csdn.net/weixin_32050033/article/details/113438312 如侵犯您的版权,请留言回复原文章的地址,我们会给您删除此文章,给您带来不便请您谅解!
发表评论
最新留言
关于作者
